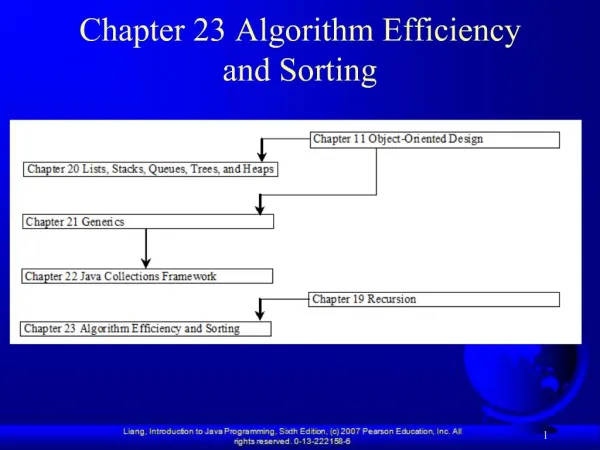
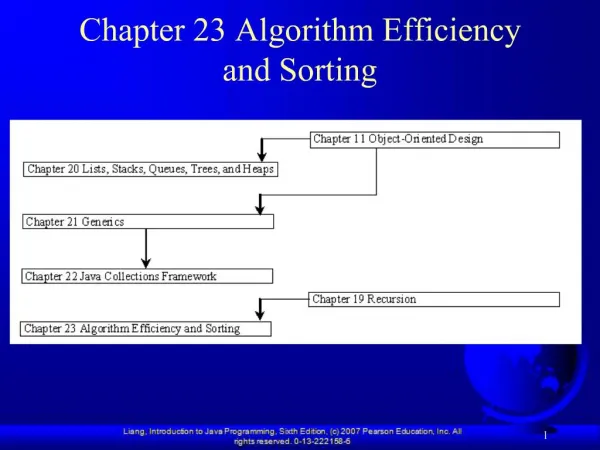
Lexical Permutation Sorting Algorithm
Lexical Permutation Sorting Algorithm. LPSA is superior to BWT!?. Burrows Wheeler Transform. 可逆圧縮の前処理 BWT( ブロックソーティング ) Move-to-Front エントロピー圧縮 圧縮効率と処理速度のバランスが良い bzip2, Bred 等の基本アルゴリズム フルカラー画像の圧縮にも有効. Burrows Wheeler Transform. BWT (ブロックソーティングアルゴリズム)


Lexical Permutation Sorting Algorithm
E N D
Presentation Transcript
Lexical Permutation Sorting Algorithm LPSA is superior to BWT!?
Burrows Wheeler Transform • 可逆圧縮の前処理 • BWT(ブロックソーティング) • Move-to-Front • エントロピー圧縮 • 圧縮効率と処理速度のバランスが良い • bzip2, Bred 等の基本アルゴリズム • フルカラー画像の圧縮にも有効
Burrows Wheeler Transform • BWT(ブロックソーティングアルゴリズム) • ローテーション入力系列を左方向にローテートし、その長さと同じ数の系列を生成する。 • ソート生成した系列群を辞書式にソートする。 • 出力 • 出力系列: L • プライマリインデックス: I
原系列: S0 = GEGEGENOGE S0 GEGEGENOGE S1 EGEGENOGEG S2 GEGENOGEGE S3 EGENOGEGEG S4 GENOGEGEGE S5 ENOGEGEGEG S6 NOGEGEGEGE S7 OGEGEGEGEN S8 GEGEGEGENO S9 EGEGEGENOG ローテーション
原系列: S0 = GEGEGENOGE S0 GEGEGENOGE S1 EGEGENOGEG S2 GEGENOGEGE S3 EGENOGEGEG S4 GENOGEGEGE S5 ENOGEGEGEG S6 NOGEGEGEGE S7 OGEGEGEGEN S8 GEGEGEGENO S9 EGEGEGENOG ソーティング
原系列: S0 = GEGEGENOGE 出力: ( GGGGOEEEEN , 6 ) S0 GEGEGENOGE S1 EGEGENOGEG S2 GEGENOGEGE S3 EGENOGEGEG S4 GENOGEGEGE S5 ENOGEGEGEG S6 NOGEGEGEGE S7 OGEGEGEGEN S8 GEGEGEGENO S9 EGEGEGENOG 出力
BWTの効果 • どうして同じ文字が並ぶの? ソートすることにより、似通った文脈は隣り合う。 ex. encode と decode → ode...enc, ode...dec • こんなに文字を入れ替えちゃってだいじょうぶ? 出力系列 Lとプライマリインデックス Iから原系列を復元できます。
原系列: S0 = G S0 ?????????E S? ?????????G S? ?????????E S? ?????????G S? ?????????E S? ?????????G S? ?????????E S? ?????????N S? ?????????O S? ?????????G 原系列の求め方 出力: ( GGGGOEEEEN , 6 )
原系列: S0 = G S0 G????????E S? E????????G S? G????????E S? E????????G S? G????????E S? E????????G S? N????????E S? O????????N S? G????????O S? E????????G 原系列の求め方 出力: ( GGGGOEEEEN , 6 )
原系列: S0 = G 1 2 3 4 1 2 3 4 原系列の求め方 出力: ( GGGGOEEEEN , 6 ) S? GE????????G S? GE????????G S? GE????????G S? GE????????G S? OG????????O S0 EG????????E S? EG????????E S? EG????????E S? EN????????E S? NO????????N
E G E N O G E S9 1 1 2 2 3 3 S3 4 4 S5 S8 1 1 2 2 3 3 S4 4 4 S6 S7 原系列の求め方 原系列: G E G S0 = 出力: ( GGGGOEEEEN , 6 ) S? GE????????G S1 S? GE????????G S? GE????????G S? GE????????G S? OG????????O S0 EG????????E S2 S? EG????????E S? EG????????E S? EN????????E S? NO????????N
Lexical Permutation Sorting Algorithm • 入力列を {1, 2, ... ,n} の順列に限定する。 文字列は multisetの順列と考えられる • φ(n) 個の列を出力列の候補にできる。 φ(n):n と互いに素な n 以下の数の個数。 ex. φ(7)=6, φ(8)=4 • 候補の中で、最も都合のよい列を出力系列とする。 • 一般の文字列の場合とのうまい関係がある。
abcde π = bcaed 置換 X = { a, b, c, d, e } π: X → X π(a) = b, π(b) = c, π(c) = a, π(d) = e, π(e) = d . π = [b, c, a, e, d ] (cartesian form)
LPSAの例 原系列: p = [3, 1, 5, 4, 2] 31542 15423 54231 42315 23154 15423 23154 31542 42315 54231 N= N’ = BWTだと・・・ 出力系列: 53124 or 34251 プライマリインデックス: 3
5 2 3 4 θ θ θ θ θ や も出力系列としてつかえる。 2 3 θ θ LPSAならお得 15423 23154 31542 42315 54231 1 2 3 4 5 5 3 1 2 4 N’ = θ= = [5,3,1,2,4] ただし、インデックスがさらに一つ増える。
2 4 6 θ θ θ から θ は一意には決まらない。 2 θ 任意の列じゃ駄目? 154263 263154 315426 426315 542631 631542 1 2 3 4 5 6 4 3 5 6 2 1 2 N’ = θ = (φ(n)個の列が候補となる)
π = π 1 i N=[π ,π , ... ,π ] 2 1 n LPSAなら、さらにお得 LPSAの場合、一列目をみるだけでソートできる。 1 2 3 4 5 3 1 5 4 2 31542 15423 54231 42315 23154 N= =[3,1,5,4,2] も同様
π = π 1 i π -1 1 N’=[π π ,π π , ... ,π π ] -1 -1 -1 1 1 1 2 1 n LPSAなら、さらにお得 LPSAの場合、一列目をみるだけでソートできる。 1 2 3 4 5 3 1 5 4 2 31542 15423 54231 42315 23154 N= =[3,1,5,4,2] も同様 = [2, 5, 1, 4, 3]
-1 λ=μ =[1, 4, 2, 5, 3] 一般的な文字列に対するLPSA 原系列: Y =a b a b b ソート後: Y’ =a a b b b Y’ 1 3 5 2 4 ababb babba abbab bbaba babab ababb abbab babab babba bbaba N(Y)= N’(Y) = μ=[1, 3, 5, 2, 4], Y’ [i] = Y [μ( i )], Y [i] = Y’ [λ( i )]
一般的な文字列に対するLPSA 得られたλを入力列としてLPSAを行う。 14253 42531 25314 53142 31425 14253 25314 31425 42531 53142 N(λ)= N’(λ) = 原系列を復元するには・・・ k 出力列θ , k, プライマリインデックス, Y’
BWTとLPSAの関係(論文中の定理3.2) Yを文字列、λ=λとすると、 N’i, j(Y) = Y’ [N’i, j (λ)] Y’ ababb abbab babab babba bbaba 14253 25314 31425 42531 53142 N’(Y) = N’(λ) = Y’ =a a b b b
定理3.2の直感的証明 Y’ ababb babba abbab bbaba babab 14253 42531 25314 53142 31425 N(Y)= N(λ)= Y [i] = Y’ [λ( i )], N(Y) = Y’[N(λ)] N’i, j(Y) = Y’ [N’i, j (λ)]