MICROBIAL GENETICS GENOMICS
1. MICROBIAL GENETICS GENOMICS. 2. MICROBIAL GENETICS - GENOMICS. GENOMICS, FUNCTIONAL GENOMICS, STRUCTURAL GENOMICS HOMOLOGY SEQUENCING WHOLE GENOMES Library of Cloned Fragments, Assembly of contigs Annotation Locates each Gene (ORF) &


MICROBIAL GENETICS GENOMICS
E N D
Presentation Transcript
1 MICROBIAL GENETICS GENOMICS
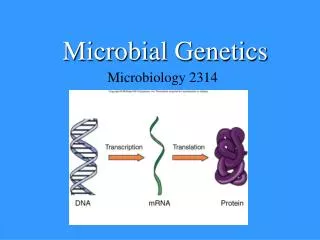
2 MICROBIAL GENETICS - GENOMICS GENOMICS, FUNCTIONAL GENOMICS, STRUCTURAL GENOMICS HOMOLOGY SEQUENCING WHOLE GENOMES Library of Cloned Fragments, Assembly of contigs Annotation Locates each Gene (ORF) & Identifies each Gene Function (i.e., what is function of gene product) Orthologous, Paralogous CONCEPT OF CORE GENE POOL AND FLEXIBLE GENE POOL Core Gene Pool Replication, Transcription, Translation, Glycolysis, Cell Wall Synthesis Flexible Gene Pool Insertion sequences, transposons, integrons, plasmid, phages (prophages), genomic islands Pathogenicity, Drug Resistance, Toxin Synthesis/Secretion, Conjugation GLOBAL STUDIES OF GENE EXPRESSION DNA arrays / Gene arrays / Microarrays / DNA chips Making arrays to be used to measure amount of mRNA from each gene Labeling RNAs (by making fluorescent cDNAcopies) Hybridization of cDNAs to microarrays and measure intensity of fluorescence
3 GENOMICS - STUDY OF ALL GENES AND SITES WITHIN THE CHROMOSOME(S) OF AN ORGANISM BY DETERMINING AND ANALYZING THE NUCLEOTIDE SEQUENCE OF THE ENTIRE CHROMOSOME(S) FUNCTIONAL GENOMICS - STUDY OF FUNCTIONS OF A CELL OR ORGANISM BY ANALYSIS OF CHROMOSOME NUCLEOTIDE SEQUENCE STRUCTURAL GENOMICS - STUDY OF 3D SHAPES OF PROTEINS BY COMPARISON OF AMINO ACID SEQUENCES [DEDUCED FROM GENE SEQUENCES] TO PROTEIN STRUCTURE DATA BASES BIOINFORMATICS - DEVELOPMENT OF SOFTWARE AND ALGORITHMS TO ANALYZE GENE AND PROTEIN SEQUENCES AND TO COMPARE THEM TO DATA BASES ALGORITHM - RULES FOR PROCEDURES FOR SOLVING MATHEMATICAL PROBLEM, USUALLY INVOLVING REPETITIVE OPERATIONS HOMOLOGY - EXTENT OF SIMILARITY [OR IDENTITY] BETWEEN GENES OR PROTEINS. PROTEINS WHICH PERFORM THE SAME FUNCTIONS OFTEN HAVE SIMILAR AMINO ACID SEQUENCES. GENES WHICH ENCODE SIMILAR PROTEINS HAVE SIMILAR NUCLEOTIDE SEQUENCES. SOME PROTEINS [AND GENES] ARE VERY SIMILAR AND ARE SAID TO HAVE A HIGH DEGREE OF HOMOLOGY. OTHER PROTEINS AND GENES ARE MORE DISTANTLY RELATED AND SHARE A LOW DEGREE OF HOMOLOGY. UNRELATED PROTEINS HAVE NO SIMILARITY IN SEQUENCE. DNA SEQUENCING - CLONE GENE OR FRAGMENT OF INTEREST, PRIMER,SYNTHESIS OF LABELED DNA AS OVERLAPPING FRAGMENTS. EACH INCREASING IN LENGTH BY ONE NUCLEOTIDE. DETERMINATION OF LAST NUCLEOTIDE ON 3’ END OF EACH FRAGMENT GIVES ORDER OF NUCLEOTIDES POLYMERIZED BY THE NEW SYNTHESIS AND THE NUCLEOTIDE SEQUENCE ALONG ONE STRAND. USE ANOTHER PRIMER TO CONFIRM SEQUENCE OF COMPLEMENTARY STRAND. WHOLE GENOME RANDOM OR SHOTGUN SEQUENCING -
4 • WHOLE GENOME - RANDOM/SHOTGUN SEQUENCING • PREPARE LIBRARY OF RANDOM FRAGMENTS • SMALL AND LARGE INSERTS • EXTRACT CHROMOSOME SHEAR TO ~2, ~20 KB FRAGMENTS • CLONE INTO PLASMID VECTORS • NEED ~20,000 CLONES FOR A 2 MEGA BP CHROMOSOME
5 SEQUENCE SHORT INSERTS ~ 40,000 SEQUENCES (WITH UNIVERSAL PRIMERS) ~ 500-800 BP/SEQUENCE 1L FROM LEFT – TOP STRAND SEQ. FROM RIGHT – BOTTOM STRAND SEQ. 1R ALL SEQUENCES ARE DETERMINED 5’ – 3’ CLONE 1 67L 714L 67R 714R CLONE 67 CLONE 714
COMPILE – ASSEMBLE ALL SEQUENCES TO FIND OVERLAP- PING REGIONS – THE GOAL IS TO FIND ONE CONTINUOUS CIRCULAR CHROMOSOME SEQUENCE BUT, YOU HAVE SEQUENCES 5’-3’ READING LEFT TO RIGHT AND OTHER SEQUENCES 5’-3’ READING RIGHT TO LEFT HOW TO COMPARE SEQUENCES DETERMINED 5’-3’ LEFT TO RIGHT FROM ONE STRAND TO THOSE DETERMINED 5’-3’ RIGHT TO LEFT FROM THE OTHER STRAND? LEFT TO RIGHT: 5’ AATTAAGAACCTCCCGAGCTCTGT 3’ TOP STRAND RIGHT TO LEFT: 5’ GCGCGCAGATATACAGAGC 3’ BOTTOM STRAND DO THESE SEQUENCES OVERLAP? CONVERT THE RIGHT TO LEFT SEQUENCES TO THEIR REVERSE COMPLEMENTARY SEQUENCES
LEFT TO RIGHT: 5’ AATTAAGAACCTCCCGAGCTCTGT 3’ TOP STRAND RIGHT TO LEFT: 5’ GCGCGCAGATATACAGAGC 3’ BOTTOM STRAND BY COMPUTER, REVERSE THE BOTTOM STRAND SO THE 3’ END IS ON THE LEFT: 3’ CGAGACATATAGACGCGCG 5’ DEDUCE BY COMPUTER, WHAT IS THE COMPLEMENT OF THE BOTTOM STRAND (WHICH WILL BE ANTI-PARALLEL). THAT IS, THE COMPLEMENT WILL NOW BE 5’-3’ LEFT TO RIGHT, WHICH IS THE TOP STRAND SEQUENCE: REVERSE COMPLEMENT OF THE BOTTOM STRAND SEQUENCE IS: 5’ GCTCTGTATATCTGCGCGC 3’ (DEDUCED TOP STRAND BUT READ FROM BOTTOM STRAND) DO THEY OVERLAP?
DO THOSE TWO SEQUENCES OVERLAP? TOP STRAND 5’ AATTAAGAACCTCCCGAGCTCTGT 3’ TOP STRAND DEDUCED FROM SEQUENCING BOTTOM STRAND 5’ GCTCTGTATATCTGCGCGC3’ DO THEY OVERLAP? 5’ AATTAAGAACCTCCCGAGCTCTGT 3’ 5’ GCTCTGTATATCTGCGCGC3’ YES! YOU NOW HAVE A CONTIG: 5’ AATTAAGAACCTCCCGAGCTCTGTATATCTGCGCGC 3’
SEQUENCING LARGE FRAGMENTS 2. DESIGNED PRIMERS (FROM NEW SEQUENCED REGIONS) PRIMER PAIR #2 1. UNIVERSAL PRIMERS 4. PRIMER PAIR #4 …UNTIL ENTIRE FRAGMENT HAS BEEN SEQUENCED 3. PRIMER PAIR #3
ANNOTATION - LOCATION OF THE GENES • FIND THE GENES – CODING REGIONS – OPEN READING FRAMES • CRITERIA: START AND STOP CODONS • MINIMUM LENGTH ~75-80 CODONS • PRECEEDED BY SHINE-DALGARNO • DNA SEQUENCE • 5’ ATGCATGTTAGGGAGCCAACCGATTTGAGG … CCCTAG • 3’ TACGTACAATCCCTCGGTTGGCTAAAACCC … GGGATC • FRAMES LEFT TO RIGHT • 1 METHISVALARGGLUPROTHRASPLEUARG…PRO*** • 2 CYSMETLEUGLYSERGLNPROILE*** TOO SHORT • ALACYS***GLYALAASNARGPHEGLU NO START ATG • NO ORF • MUST CONSIDER THAT REGION LEFT TO RIGHT AND RIGHT TO LEFT TRANSCRIPTION AND TRANSLATION
Figure 8-43 PREDICTING OPEN READING FRAMES (ORFS) IN A DNA SEQUENCE. SCAN SEQUENCE LEFT TO RIGHT & RIGHT TO LEFT IN ALL SIX FRAMES FOR START AND STOP CODONS WITH SHINE-DALGARNO PROPERLY SPACED BEFORE THE START CODON AND A MINIMUM LENGTH (~75-80) OF CONTIGUOUS CODONS
6 • ANNOTATION –IDENTIFYING WHAT EACH GENE • CODES FOR – FUNCTION OF EACH GENE PRODUCT • IDENTIFY GENES (ORFs) BY COMPARING DEDUCED AMINO ACID SEQUENCE AGAINST ALL KNOWN PROTEIN SEQUENCES – HOMOLOGY • IDENTIFY tRNA AND rRNA GENES AND OPERONS • BY NUCLEOTIDE HOMOLOGY (THESE GENES ARE HIGHLY CONSERVED AMONG ALL ORGANISMS) • IDENTIFY REPEAT SEQUENCES - NUCLEOTIDES • e.g., INSERTION SEQUENCES – ALSO CONSERVED
7 HOMOLOGY = DEGREE OF IDENTITY OR SIMILARITY [AMINO ACIDS OR NUCLEOTIDES] ORTHOLOGOUS PROTEINS - SIMILAR PROTEINS FROM DIFFERENT SPECIES - ORTHOLOGS PARALOGOUS PROTEINS - SIMILAR PROTEINS WITHIN SAME ORGANISM PARALOGS
Figure 8-44 MULTIPLE-SEQUENCE ALIGNMENT. APPRECIATE!!! DIHYDROLIPAMIDE DEHYDROGENASES – OXIDATIVE DECARBOXYLATIONS OF RESPIRATION INCLUDING PYRUVATE CONVERSION TO ACETYL CoA AND CO2, OTHERS; SINGLE LETTER AA
9 1.8 6 58 1,738 616 1,122 71 56 102 67 43 91 143 34 19 71 116 50 64 30 165 351 237 28 %b (4) (3) (6) (4) (2) (5) (8) (2) (1) (4) (7) (3) (4) (2) (10) (20) (14) (2) 1.7d 2 37 1,727 1,089 638 64 49 24 26 19 53 158 9 4 38 117 37 19 21 56 547 513 29 % 4 3 1 1 1 3 9 0.5 0.2 2 7 2 1 1 3 31 29 2 1.7 3 36 1,589 707 882 42 57 101 125 24 90 100 26 17 41 99 38 25 10 88 186 497 24 % 3 4 6 8 2 6 6 2 1 3 6 2 2 0.6 6 12 31 2 Haemophilus influenzae Methanococcus jannaschii c Helicobacter pylori APPRECIATE!!! GENOME (x 10 e 6BP) R RNA OPERONS T RNA GENES ORFs UNKNOWN FUNCTION ASSIGNED FUNCTIONa NUMBER OF GENES FOR: AMINO ACID METABOL COENZYME SYNTHESIS CELL ENVELOPE CELL DIVISION, ETC SUGAR/NITROGEN META DNA METABOLISM ENERGY METABOL LIPID/PHOSPHOLIPID OTHER CATEGORIES PROTEIN FATE (FOLDING, ETC) PROTEIN SYNTHESIS NUCLEIC ACID PRECURSORS REGULATORS TRANSCRIPTION TRANSPORT HYPOTHETICAL CONSERVEDe HYPOTHETICAL, NOT CONSERVED OTHER UNKNOWN a BASED ON HOMOLOGY OF DEDUCED PROTEIN SEQUENCE TO PREVIOUSLY CHARACTERIZED PROTEINS b PERCENTAGES (ROUNDED OFF) OF TOTAL GENES c AUTOTROPHIC ARCHAEON, GROWS ON THE OCEAN FLOOR AT BASE OF 2600 METER VOLCANO, 200 ATMOSPHERES PRESSURE, TEMP RANGE OF 48 T0 94ºC, WITH OPTIMUM OF 85ºC, STRICT ANAEROBE, PRODUCES METHANE BY OXIDIZING H2 AND REDUCING CO2 d PLUS TWO PLASMIDS OF 58 AND 16 KBP e IN OTHER CREATURES
8 APPRECIATE !!!
Figure 8-42 Circular display map of the Mycoplasma mycoides genome (1,211,703 bp). APPRECIATE !
FIG 8-42 LEGEND: APPRECIATE !!! • OUTER TWO CIRCLES: ORFS ORIENTED CLOCKWISE • (OUTERMOST) AND COUNTER-CLOCKWISE (INNER). • USUALLY ORIENTED FOR REPLICATION AND • TRANSCRIPTION TO MOVE IN SAME DIRECTION • FROM ORIGIN TO TERMINUS. • THIRD FROM OUTSIDE: MOBILE GENETIC ELEMENTS • FOURTH: RIBOSOMAL AND TRANSFER RNA GENES • FIFTH: GENOMIC ISLANDS • SIXTH: GC CONTENT: RED - >50%, BLACK - <50%
14 MAJOR RESULT OF GENOMICS STUDIES OF PROKARYOTES
10 STEP FUNCTIONAL GENOMICS INCLUDES GLOBAL STUDY OF GENE EXPRESSION • DNA ARRAYS / GENE ARRAYS / MICROARRAYS / DNA CHIPS • = DNA FRAGMENTS CORRESPONDING TO EVERY GENE (ORF) FIXED TO TINY SEPARATE SPOTS ON A SLIDE • USED TO DETECT AND QUANTITATE mRNA FROM EVERY GENE MAKING THE ARRAY EXTRACT CHROMOSOMAL DNA AMPLIFY FRAGMENTS (BY PCR) CORRESPONDING TO EACH ORF (REQUIRES SPECIFIC PRIMER PAIRS) AFFIX EACH FRAGMENT TO SEPARATE SPOT ON SLIDE
STEP 2:EXTRACT mRNA FROM CULTURE(S) AND CONVERT • mRNAs TO COMPLEMENTARY DNAs • REVERSE TRANSCRIPTASE WITH dATP, dGTP, dTTP • AND dCTP WITH RED FLUORESCENT TAG • STEP 3: HYBRIDIZE cDNA's TO MICROARRAY TO QUANTITATE • AMOUNT OF EACH cDNA REMEMBER - DNAs ON SLIDE ARE IN EXCESS (OVER cDNAs) MEASURE FLUORESCENCE FLUORESCENCE INTENSITY IS PROPORTIONAL TO CONCENTRATION OF EACH cDNA cDNAAMOUNT REFLECTS AMOUNT OF mRNA FROM EACH GENE (ORF) CORRELATE EXPRESSION LEVEL OF GENES WITH FUNCTION OF PROTEIN, OTHER PROCESS BEING STUDIED E.G., ALCOHOLISM/LYMPHOMA
MICROARRAY – EXPRESSION OF ALL GENES – ONE GROWTH CONDITION 1. PREPARE MICROARRAY- DNA CORRESPONDING TO EACH ORF ON SEPARATE SPOT 2. GROW CULTURE, EXTRACT mRNA CONVERT mRNAs TO cDNAs (RED FLUORESCENT TAG) dCTP-REDdATP, dGTP, dTTP 3. HIGHLY EXPRESSED GENES – LOTS OF RED cDNA INFREQUENTLY EXPRESSED GENES – SMALL AMOUNT RED cDNA 4. HYBRIDIZE cDNAs TO MICROARRAY READ FLUORESCENCE INTENSITY