Download

1 / 22
220 likes | 309 Views
This research addresses the issue of data transfer between parallel programs for more accurate simulations and visualization. By focusing on multi-scale problems, the study proposes solutions for efficient data exchange. The implementation involves runtime matching and matching policies to optimize performance. The experiments demonstrate the effectiveness of the approach in minimizing overhead.

E N D
Flexible Control of Data Transfer between Parallel Programs Joe Shang-chieh Wu Alan Sussman Department of Computer Science University of Maryland, USA
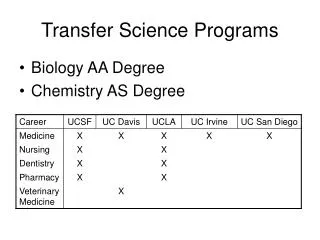
Particle and Hybrid model Corona and solar wind Rice convection model Global magnetospheric MHD Thermosphere-ionosphere model Grid 2004
What is the problem? • Coupling existing (parallel) programs • for physical simulations more accurate answers can be obtained • for visualization, flexible transmission of data between simulation and visualization codes • Exchange data across shared or overlapped regions in multiple parallel programs • Couple multi-scale (space & time) programs • Focus on multiple time scale problems (when to exchange data) Grid 2004
Roadmap • Motivation • Approximate Matching • Matching properties • Performance results • Conclusions and future work Grid 2004
Is it important? • Petroleum reservoir simulations – multi-scale, multi-resolution code • Special issue in May/Jun 2004 of IEEE Computing in Science & Engineering “It’s then possible to couple several existing calculations together through an interface and obtain accurate answers.” • Earth System Modeling Framework several US federal agencies and universities. (http://www.esmf.ucar.edu) Grid 2004
Solving multiple space scales • Appropriate tools • Coordinate transformation • Domain knowledge Grid 2004
Matching is OUTSIDE components • Separate matching (coupling) information from the participating components • Maintainability – Components can be developed/upgraded individually • Flexibility – Change participants/components easily • Functionality – Support variable-sized time interval numerical algorithms or visualizations • Matching information is specified separately by application integrator • Runtime match via simulation time stamps Grid 2004
Ap0.Sr12 Ap1.Sr0 Ap0.Sr4 Ap2.Sr0 Ap0.Sr5 Ap4.Sr0 Separate codes from matching Exporter Ap0 Configuration file Importer Ap1 Grid 2004
Matching implementation • Library is implemented with POSIX threads • Each process in each program uses library threads to exchange control information in the background, while applications are computing in the foreground • One process in each parallel program runs an extra representative thread to exchange control information between parallel programs • Minimize communication between parallel programs • Keep collective correctness in each parallel program • Improve overall performance Grid 2004
Approximate Matching • Exporter Ap0 produces a sequence of data object A at simulation times 1.1, 1.2, 1.5, and 1.9 • A@1.1, A@1.2, A@1.5, A@1.9 • Importer Ap1 requests the same data object A at time 1.3 • A@1.3 • Is there a match for A@1.3? If Yes, which one and why? Grid 2004
Supported matching policies <importer request, exporter matched, desired precision> = <x, f(x), p> • LUB minimum f(x) with f(x) ≥ x • GLB maximum f(x) with f(x) ≤ x • REG f(x) minimizes |f(x)-x| with |f(x)-x| ≤ p • REGU f(x) minimizes f(x)-x with 0 ≤ f(x)-x ≤ p • REGL f(x) minimizes x-f(x) with 0 ≤ x-f(x) ≤ p • FASTR any f(x) with |f(x)-x| ≤ p • FASTU any f(x) with 0 ≤ f(x)-x ≤ p • FASTL any f(x) with 0 ≤ x-f(x) ≤ p Grid 2004
te’ te’’ Acceptable ≠ Matchable Grid 2004
te’ Region-type matches Grid 2004
Experimental setup Question : How much overhead introduced by runtime matching? • 6 PIII-600 processors, connected by channel-bonded Fast Ethernet • utt = uxx + uyy + f(t,x,y), solve 2-d diffusion equation by the finite element method. • u(t,x,y) : 512x512 array, on 4 processors (Ap1) • f(t,x,y) : 32x512 array, on 2 processors (Ap2) • All data in Ap2 is sent (exported) to Ap1 using matching criterion <REGL,0.05> • Ap1 receives (imports) data with 3 different scenarios. 1001 matches made for each scenario (results averaged over multiple runs) Grid 2004
Experiment result 1 Ap1 execution time (average) Grid 2004
Experiment result 2 Ap1 pseudo code Ap1 overhead in the slowest process Grid 2004
Experiment result 3 • Fastest process (P11) • - high cost, remote match • Slowest process (P13) • - low cost, local match • High cost match can be hidden Comparison of matching time Grid 2004
Conclusions & Future work • Conclusions • Low overhead approach for flexible data exchange between different time scale e-Science components • Ongoing & future work • Performance experiments in Grid environment • Caching strategies to efficiently deal with slow importers • Real applications – space weather is the first one Grid 2004
Main components Grid 2004
Local and Remote requests Grid 2004
Space Science Application Grid 2004