Download

1 / 51
520 likes | 1.23k Views
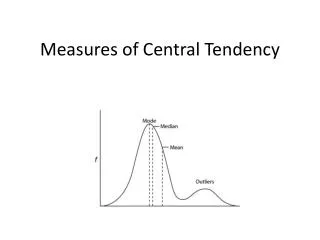
Measures of Central Tendency. Definitions Measures of Central Tendency Central Tendency: the Mean Central Tendency: the Median Central Tendency: the Mode Central Tendency: A Skewed Distribution. Definitions.

E N D
Measures of Central Tendency Definitions Measures of Central Tendency Central Tendency: the Mean Central Tendency: the Median Central Tendency: the Mode Central Tendency: A Skewed Distribution
Definitions • In addition to frequency distributions, we use two other types of statistics to describe the distribution of a variable: • Measures of central tendency are statistics that summarize a distribution of scores by reporting the most typical or representative value of the distribution. • Measures of variability are statistics that indicate the amount of variety or heterogeneity in a distribution of scores.
Measures of Central Tendency • We will study three measures of central tendency: • The mean, the preferred measure for interval data • The median, the preferred measure for ordinal data • The mode, the preferred measure for nominal and dichotomous data
Central Tendency: the Mean • The mean is the arithmetic average of the scores. • The mean is the preferred measure of central tendency for interval level variables, unless the distribution is highly skewed (has a few unusually high or unusually low scores). For a highly skewed distribution, the median is the preferred measure of central tendency. • The mean is interpreted as the average or typical score. • The mean is not an appropriate statistic for ordinal, nominal, or dichotomous variables.
Computing a Mean – Sample Problem Suppose we want to know how many credit cards a typical college student has. We ask a sample of five students how many credit cards they each have, and obtained the answers: 2, 1, 3, 2, and 4. The number of credit cards for each student is an interval level variable. The mean is an appropriate statistic for computing the typical or average number of credit cards owned by a college student.
Computing a Mean – Summing Scores The first step in computing a mean is summing the scores of all of the subjects in our sample: 2 1 3 2 + 4 12
Computing a Mean – Dividing by the Number of Subjects The second step in computing a mean is dividing the sum of scores for all of the subjects in our sample (12) by the number of subjects (5) in the sample: 12 ÷ 5 = 2.4 The mean number of credit cards possessed by the five college students in our sample is 2.4 credit cards.
2.4 2 1 2 3 4 ----+----+----+----+---- Visualizing the Mean • If we position the five values for number of credit cards on a number line and show the location of the mean, we can visualize the mean as a measure of central tendency.
Interpreting the Mean • We can make the following interpretative statements about the mean which we just computed: • The typical number of credit cards possessed by students in our sample was 2.4 credit cards. • The average number of credit cards possessed by students in our sample was 2.4 credit cards. • A typical student in our sample had 2.4 credit cards. • Our best guess of the number of credit cards for any student in our study is 2.4 credit cards.
The Mean as a Best Guess - Defined • The first student in our sample had 2 credit cards. If we guessed that he had the mean number of credit cards (2.4), we would be off by 2 – 2.4 = –0.4; for the second student with 1 credit card, we would be off by 1 – 2.4 = -1.4; and so forth for the other students. The amount that we are off for each case is called the deviation. • To measure the total units of error for all cases, we square each deviation to eliminate the plus and minus signs, and sum the squared deviations for all of the cases in our sample, as we will see on the next slide. • The total sum of squared errors associated with the mean is smaller than the total amount of error associated with any other guess of a typical value. Since there is less total error, we say the mean is the best estimator for all subjects.
The Mean as a Best Guess - Demonstrated Using the value of 2.0 as our guess: 2 – 2.0 = 0.0, (+0.0)2 = 0.00 1 – 2.0 = -1.0, (-1.0)2 = 1.00 3 – 2.0 = 1.0, (+1.0)2 = 1.00 2 – 2.0 = 0.0, (+0.0)2 = 0.00 4 – 2.0 = 2.0, (+2.0)2 = 4.00 6.00 The total error is 6.00 units of error, larger than the error associated with the mean. Using the mean of 2.4 as our guess: 2 – 2.4 = -0.4, (-0.4)2 = 0.16 1 – 2.4 = -1.4, (-1.4)2 = 1.96 3 – 2.4 = 0.6, (+0.6)2 = 0.36 2 – 2.4 = -0.4, (-0.4)2 = 0.16 4 – 2.4 = 1.6, (+1.6)2 = 2.56 5.20 The total error is 5.20 units of error.
Comments about the Mean • All cases in the sample are used in computing the mean, so we can interpret it as typical of all cases. • The mean may or may not be the actual value for any subject in the sample, e.g. no one in the our sample has 2.4 credit cards. • Unusual scores have a large impact on the mean of a distribution. If the fifth subject in our study had 10 credit cards instead of 4, the mean would change from 2.4 to 3.6. We will discuss this further under the topic of skewing.
Central Tendency: the Median • The median is the score at the mid-point of a sorted distribution of scores. Half of the scores fall above this point and half fall below this point. • The median is the preferred measure of central tendency for ordinal level variables, and for interval level variables that have a badly skewed distribution. • The median is interpreted as the central or middle score. • The median can be computed for interval level variables, but is not an appropriate statistic for nominal or dichotomous variables.
Computing the Median • To compute the median, we sort the values from low to high. The median is the middle score. • If the number of cases in the sample is an odd number, the middle case is the case above and below which the same number of cases occur. • If the number of cases in the sample is an even number, there will be two middle scores and the median is halfway between these two middle scores.
Computing the Median when the Number of Cases is an Odd Number • If the number of cases in the sample is an odd number, the middle case is the case above and below which the same number of cases occur. • For our sample of number of credit cards (2, 1, 3, 2, and 4), the median is: • 1 2 2 3 4 • Median = 2.0
1 2 2 3 4 4 • Median = 2.5 Computing the Median when the Number of Cases is an Even Number • If the number of cases in the sample is an even number, there will be two middle scores and median is halfway between these two middle scores. • Suppose our sample contained 6 cases with scores of 1, 2, 2, 3, 4, and 4. The median would be:
2.0 2 1 2 3 4 ----+----+----+----+---- Visualizing the Median • If we position the five values for number of credit cards on a number line and show the location of the median, we can visualize the median as a measure of central tendency.
Interpreting the Median • We can make the following interpretative statements about the median for the sample of number of credit cards: • The central score in the distribution of number of credit cards possessed by students was 2.0 credit cards. • The middle score in the distribution of number of credit cards possessed by students was 2.0 credit cards. • The typical number of credit cards possessed by students was 2.0 credit cards. • Fifty percent of the cases in our sample had a score below (above) 2.0. • Half of the cases in our sample had a score below 2.0 and half of the cases in our sample had a score above 2.0.
Using the median of 2.5 as the estimated value for each case, we make 1.0 units of error: 1 - 2.5 = -1.5 2 - 2.5 = -0.5 2 - 2.5 = -0.5 3 - 2.5 = 0.5 4 - 2.5 = 1.5 4 - 2.5 = 1.5 1.0 Using the value of 3.0 as the estimated value for each case, we make -2.0 units of error: 1 – 3.0 = -2.0 2 – 3.0 = -1.0 2 – 3.0 = -1.0 3 – 3.0 = 0.0 4 – 3.0 = 1.0 4 – 3.0 = 1.0 -2.0 Using the value of 2.0 as the estimated value for each case, we make 4.0 units of error: 1 – 2.0 = -1.0 2 – 2.0 = 0.0 2 – 2.0 = 0.0 3 – 2.0 = 1.0 4 – 2.0 = 2.0 4 – 2.0 = 2.0 4.0 The Median as a Best Guess • The median is our best guess of the value on an ordinal level variable for any given subject in our data set. If we guess the median as the value for every subject, the sum of the errors (positive or negative) associated with our guess is smaller than it would be for any other value we might pick as a guess. We will use the six values for number of credit cards (1, 2, 2, 3, 4, and 4) with a median of 2.5 yields to demonstrate this point.
Comments about the Median • The median may or may not be the actual value for any subject in the sample. • If there are a lot of cases with the median value, the description of the median as the central score may be confusing. • Unusually large or unusually small scores have no impact on the median of a distribution since only the one or two middle scores are used in computing it. This makes the median a better measure of central tendency than the mean for a distribution that has a few cases in the distribution with either very large or very small scores.
Central Tendency: the Mode • The mode is the most common value in a distribution, the category of a variable that has the largest frequency. • The mode is the preferred measure of central tendency for a nominal level variable, including a dichotomous variable. • The mode is interpreted as the most common score. • The mode can be computed for ordinal level variables, and for interval level variables that have been grouped in a frequency distribution.
Computing the Mode The mode can be read directly from the frequency distribution table. The mode for Race is the category 5 = White which has the largest frequency (231).
The Mode and the Modal Frequency • The modal frequency is sometimes confused with the modal category. The modal frequency is the number of cases that fall in the modal category. • The mode is the category that has the highest frequency. • The mode can be represented by: • the code number for the modal category, e.g. 1, 2, etc. • or, by the label for the modal category, e.g. white, female, high school graduate, etc.
Visualizing the Mode • Visually the mode is the tallest bar in the bar chart.
Interpreting the Mode • We can make the following interpretative statements about the mode for the variable Race in the High School data set: • The most common value in the Race distribution is 5 = White. • The largest category for the variable Race is 5 = White. • More subjects fell in the category 5 = White than in any other category. • A subject in the data set was most likely to be white. • Typically, a student in the data set was white. • Our best guess of the Race for any subject is 5 = White.
The Mode as a Best Guess • The mode is our best guess of the value for any given subject in our data set. If we guess the mode as the value for every subject, the number of times we are correct is equal to the modal frequency. The number of errors we would make is equal to the sample size minus the modal frequency. • Since the mode is the category with the largest frequency, guessing any other value for all cases would produce more errors.
Comments about the Mode • The mode will always be one of the possible scores in the data set. • Not every distribution has a single mode. If more than one category has the highest frequency, we refer to the distribution as bimodal or multimodal. • When a distribution is bimodal or multimodal, the mode is not an effective measure of central tendency. In fact, we may say that the distribution does not have central tendency.
A Skewed Distribution • The mean is the preferred measure of central tendency for an interval level variable, unless the variable is badly skewed. • Skew is a statistical measure of the shape of a distribution. Skew measures the extent to which a distribution of scores has a few scores that are extremely high (positive skew) or extremely low (negative skew). • As a rule-of-thumb, we will characterize a distribution as badly skewed if its skew is equal to or larger than +1.0 (positive skew) or equal to or smaller than –1.0 (negative skew).
Central Tendency for Skewed Distributions • The objective of our measures of central tendency is to present a score that is typical of all or most of the cases in the distribution. • When there are a few unusual scores, the value of the mean changes to include these scores. In effect, the value of the mean changes so that it is less representative of the majority of cases and more representative of the few unusual cases. • In skewed distributions, the median better represents the central tendency for the majority of cases than does the mean.
Measures of Variability Definitions Measures of Variability Variability: Standard Deviation Variability: the Range Variability: Index of Qualitative Variation
Definitions • In addition to frequency distributions, we use two other types of statistics to describe the distribution of a variable: • Measures of central tendency are statistics that summarize a distribution of scores by reporting the most typical or representative value of the distribution. • Measures of variability are statistics that indicate the amount of variety or heterogeneity in a distribution of scores.
Measures of Variability • In today’s class, we will study three measures of variability: • The standard deviation, the preferred measure for interval data • The range, the preferred measure for ordinal data • The index of qualitative variation, the preferred measure for nominal and dichotomous data • For all of the measures of variability, larger numerical values indicate greater variability or variability, i.e. greater difference from the measure of central tendency.
Variability: the Standard Deviation • The standard deviation measures the deviations between the mean of the distribution and each of the individual scores. • The standard deviation is the preferred measure of variability for interval level variables, unless the distribution is badly skewed. For a badly skewed distribution, the range is a preferred measure of variability. • The standard deviation is not an appropriate statistic for ordinal, nominal, or dichotomous variables.
Computing a Standard Deviation When we calculated the mean for the the credit card problem, we computed the deviations from the mean as a measure of error. The standard deviation is computed by dividing the measure of total error by the number cases and taking the square root of that result. Using the mean of 2.4 as our guess: 2 – 2.4 = -0.4, (-0.4)2 = 0.16 1 – 2.4 = -1.4, (-1.4)2 = 1.96 3 – 2.4 = 0.6, (+0.6)2 = 0.36 2 – 2.4 = -0.4, (-0.4)2 = 0.16 4 – 2.4 = 1.6, (+1.6)2 = 2.56 5.20 The total error is 5.20 units of error. The standard deviation is the square root of (5.20 ÷ 5), or 1.02.
Interpreting the Standard Deviation • The standard deviation does not have any inherent or intuitive meaning; it is a statistical measure of the variability of cases around the mean for an interval level variable. • Standard deviation is commonly presented in terms of the proportion of cases that fall between the mean plus/minus 1, 2, or 3 standard deviation measures. • The standard deviation is most useful in comparing variability among groups for interval level variables.
Picturing the Standard Deviation • The larger the standard deviation, the more spread out the distribution of cases. • The number of scores near the mean will be fewer. • The range of scores will be larger, with more cases having larger deviations from the mean.
Variability: the Variance • The variance is another measure of variability that is equal to the square the standard deviation. The variance is the average of the squared deviations from the mean. • In describing distributions, the standard deviation is the more commonly cited statistic. Variance is used primarily in inferential statistics such as the analysis of variance and correlation, which we will study later in this course.
Variability: the Range • The range is the highest score minus the lowest score in a sorted distribution. • The range is the preferred measure of variability for ordinal level variables, and for interval level variables that have a badly skewed distribution. • The range can be computed for interval level variables, but is not an appropriate statistic for nominal or dichotomous variables.
Computing a Range The range is computed by sorting the scores in the distribution and subtracting the lowest score from the highest score. Using the data from the credit card problem, we would sort the five scores (2, 1, 2, 3, and 4) as shown below, and compute the range by subtracting 1 from 4. • 2 2 3 4 • Range = 3.0
Interpreting the Range • The range is usually described as the total spread in the distribution. • The range is based only on two scores in the distribution, the highest and the lowest, and it tells us nothing about the distribution of the majority of scores in between. • The range is most useful when we are comparing groups and can describe one group as having a larger or smaller range, or spread, than the other groups.
Picturing the Range • The median and range do not precisely define a distribution. The three charts below have the same median and range, but very different distributions of cases. • The presence of cases with either larger or smaller values will change the range for the distribution, adding additional bars to the chart. • The impact on the overall shape of the distribution will be as varied as the three charts above. Even though they had the same statistical values for central tendency and dispersion, each had a very different pattern of scores in the distribution.
Variability: the Interquartile Range • Since many variables contain one or more extremely large or extremely small scores, the range may be misleading. • This problem is avoided with the interquartile range which is the difference between the third quartile and the first quartile. The third quartile is the value below which 75% of the cases fall. The first quartile is the value below which 25% of the cases fall. • While less subject to the influence of extreme cases than the range, the interquartile range still uses information for only two cases or values in the distribution.
Variability: Index of Qualitative Variation (IQV) • The IQV is a measure of variability for nominal level and dichotomous variables. Since the mode is the preferred measure of central tendency for a nominal variable, the measure of dispersion for a nominal variable would indicate the degree to which cases fall in the non-modal categories. • The IQV is the preferred measure of central tendency for a nominal level variable, including dichotomous variables. • The IQV can be computed for ordinal level variables and for interval level variables that have been grouped in a frequency distribution.
Computing an IQV • If all of the cases in a distribution fall in one category, that category would be the modal category and there would be no dispersion. In this case, the IQV would be 0%. • If all of the categories in a distribution have the same frequency, I.e. the distribution was multimodal, there would be maximum dispersion, and the IQV would be 100%. • The IQV ranges from 0% to 100%, where low percentages represent low dispersion, and high percentages represent high dispersion.
Interpreting the IQV • Low values of the IQV (approaching 0%) indicate low dispersion, or little difference from the modal category. • High values for the IQV (approaching 100%) represent high dispersion, or large numbers of cases not in the modal category. • The IQV is most useful when comparing dispersion among groups on a nominal level variable.
Picturing the Index of Qualitative Variation - 1 • The IQV increases as the number of cases in the modal category decreases. • If a variable has two categories and the number of cases in each is 50, the IQV is 100%.
Picturing the Index of Qualitative Variation - 2 • If the variable has three categories and the 50 cases not in the modal category are divided among the non-modal categories, the IQV decreases, i.e. there is less dispersion. • As the division of cases among the non-modal categories becomes more evenly divided, the IQV increases, indicating greater dispersion.
Picturing the Index of Qualitative Variation - 3 • On this slide, we keep the number of cases in the modal category the same for all four charts, but change the number of categories in the distributions. • The IQV decreases as the number of categories in the distribution increases.