
Uploaded by
pules
0 SLIDES
509 VIEWS
60LIKES
Schema-less databases
DESCRIPTION
Schema-less databases. Really…?. In actuality, there is no such thing as a schema-less database In a relational database, the schema is explicit and created separately in advance
Download

1 / 0
Download Presentation 
Schema-less databases
An Image/Link below is provided (as is) to download presentation
Download Policy: Content on the Website is provided to you AS IS for your information and personal use and may not be sold / licensed / shared on other websites without getting consent from its author.
Content is provided to you AS IS for your information and personal use only.
Download presentation by click this link.
While downloading, if for some reason you are not able to download a presentation, the publisher may have deleted the file from their server.
During download, if you can't get a presentation, the file might be deleted by the publisher.
E N D
Presentation Transcript
-
Schema-less databases
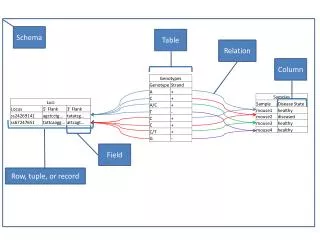
Really…? In actuality, there is no such thing as a schema-less database In a relational database, the schema is explicit and created separately in advance In column-based database, we create a fresh schema for each row, and in fact, we often reuse schema fragments from rows that are grouped together The same is true for document databases In column-based and also in document databases, users directly query the data based on the schema In graph-based databases, we are in essence building the schema as we build the data Perhaps we could say that a key-value db has no schema, but in truth, the app is must be coded to look for & interpret schematic information -
Schema updates
In a relational database, it is almost always a big deal to change a schema In “schema-less” databases, the idea is to make it as easy as possible, so that we can: dynamically keep structural information up to date – because today, this sort of information changes frequently. keep the database online – but this does not always work, or we at least have to pull part of it offline. count on the structural information of other objects to remain current – because we can surgically control exactly what objects have their schemas changed. - The schema-less approach & consequences The general idea with schema-less databases is: To treat meta data like data, as much as possible To allow much more individuality for each object Interesting side effects of this idea The database can hold much more varied forms of data Data from a schema-less database could be extracted, interpreted by the application, and then structured and stored in a relational database when necessary
- Language-related factors 1. In a schema-less database, the boundary between the db and the application is lower, as much of the query/update code is written in a conventional language 2. Or, perhaps we could say that the boundary is higher, because much more complex/rich things can be done to the data directly in the database But perhaps the deciding factor is that in a schema-less database, we don’t have many the amenities – such as full ACID transactions - that a relational database would have, and so 1 above is closer to the truth.
- Problems with schema-less approach If there is no explicit schema, it can be difficult to know what to change in the application if some of the data changes format, as code in many places will be doing their own data interpretations If updates and queries are written in a general purpose language, it can be harder to isolate the code that needs to be changed within the database-level code In a relational database, queries are fairly declarative
-
The term “migrations”
This refers to the evolution of schema information during the life-cycle of applications that use it In a relational database this is a big deal, but it is explicit In a schema-less database, we can better support incremental change The term is also used in MVC-based web development environments to refer to the indirect creation of schema components during the development of a web app Perhaps the best way to look at this term is philosophically – we want to migrate schemas, not operation is an offline-online endless loop - Maintaining backward compatibility We could create new objects or new versions of objects in order to be assured that applications can use the database as it was In a graph database, we could add new edges but not delete old ones In fact, we could view both data and metadata this way, and have an ever-growing database This is not as absurd as it might sound – for legal and business reasons, we often need to keep old data We can push old data off on faraway clusters
- Reasons for using a schema Encapsulation gives us a structure that can serve as the scope of an operation We rely on structure as a differentiator so we can reuse data and retarget data No structure – bits Minimal structure – textual documents Modest structure – relational tables Medium structure – business objects High structure – CAD Extreme structure – photos, video, audio, language
- Assignment 4 You will build an application using PostGreSQL and Cassandra The application will consist of a handful of operations that you will perform on each database – you can run your operations manually and have no app PostgreSQL will hold your schema based, tabular data Cassandra will hold your schema-variable data There will be two tables in PostgreSQL The first holds customers who are buying items Key for customer, customer names, item purchased for each row (FK of primary key of second table) The second will hold the items for purchase Key for item, price for item Cassandra will hold the buying history of each customer What items purchased How many of each item Price paid all of the instances of a given item – prices can change over time This is due at the beginning of class on Feb. 25.




















More Related