Download

1 / 45
460 likes | 502 Views
Explore the dynamic challenges faced by large distributed systems and the shift towards autonomic management for self-adaptation and efficiency. Learn about triggers, remedies, and the history of autonomic computing. Discover the concept of self-stabilization in self-organizing systems.

E N D
Autonomic Systems Sukumar Ghosh Department of Computer Science The University of Iowa
Preamble Large distributed systems are witnessing explosive growth. Peer-to-peer networks Sensor networks 2G/3G/4G cellular networks Cloud computing infrastructure Grids Also, the growth of processor population vastly outpaced the growth of human population 2
Examples Skype is used by 200 million users worldwide. The scale, dynamism and uncertainty present significant reconfiguration and management challenges
Examples The Computing Grid (LCG) for the Large Hadron Collider in CERN will handle more than one petabyte of data every month. The data will be sent out to 140 different computer centers in 33 different countries for storage and analysis.
Examples Physical hosts Virtual Machines Policy Autonomic Virtual Machine mapping in a Data Center. An autonomic controller dynamically manages the mapping of virtual machines onto physical hosts in accordance with policies specified by the user.
The problem Who will manage these networks? Management includes Fault handling System reconfiguration on demand Adapting to environmental changes Employing people for everything is unrealistic Slow and error prone Not enough bodies in the IT force Not profitable from a business perspective 6
The preferred solution Large systems have to manage themselves. Otherwise these are not practical or profitable. It is much more than the traditional perception of fault tolerance. Changes in environment, user demands, security breaches are no more catastrophic, but expected events, and add to the adversarial scenario. Everything is dynamic, and changes need to be dealt with on-the-fly. 7
Types of triggers Failure crash, transient, byzantine, security etc Environment changes processes join or leave user demands change Let F denote a trigger
Types of remedies P = predicate reflecting “desirable” configurations P Q (the weakest predicate generated by F) Q Masking: P = Q P Non-masking: P Q P [Arora and Gouda 1993] Caused by F
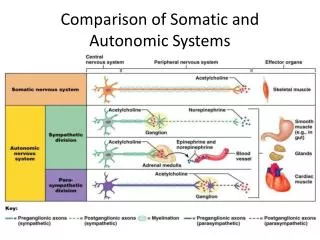
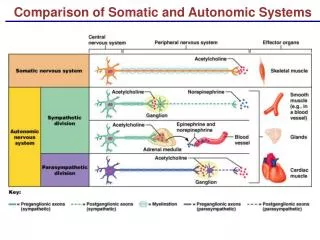
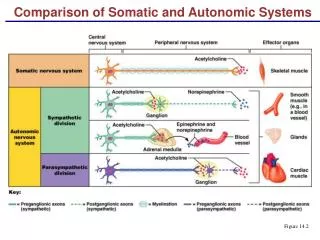
Autonomic systems Dictionary meaning of autonomic(au·to·nom·ic) 1. controlled by automatic responses: describes functions of the nervous system not under voluntary control, e.g. the regulation of heartbeat or gland secretions 2. without thought: describes an action or response that occurs without conscious control Stresses the philosophy of self-management Can computing systems behave in a similar manner? 10
A bit of history • Fault-tolerant computing system design started with space expeditions in • the 60’s (Self Testing And Repairing computer for the Voyager Mission -- • see the STAR paper by Avizienis in 1971). The autonomic computing • initiative started by IBM in 2001 to reduce the barrier that complexity poses • to further growth of systems. • Related paradigms • Organic computing • Evolutionary computing • Amorphous computing • Autonomic communication stresses only on the networking aspects of • autonomic computing. The living cell is as complex as any man-made computer, Yet the living cell is not algorithmically controlled in any practical sense: it is not digital or deterministic. See www.organic-computing.org
Self-star properties Self-optimizing Self-healing Self-management Self-protecting Self-organizing Self- Self- These (and similar self-) properties are collectively called self-* properties, and these characterize an Autonomic System. 12
Self-stabilization Somehow, the autonomic systems community forgot to include self-stabilization (that dates back to 1974) in their wish-list of self-star properties. Self-stabilizing systems are capable of eventual recovery to a legal configuration from arbitrary initial configurations. Such systems are suitable for ad-hoc deployment - they tolerate arbitrary transient failures than can corrupt its data state, as long as the codes remain unchanged.
Self-stabilization any transient fault Faulty configuration Legal configuration recovery No fault
Self-organization The ability to react fast to topology changes and restore the system to a legal configuration. Self-organizing systems efficiently handle join and leave operations of processes Join / leave (p) Join / leave (p) fp Self-organization In progress Self-organization In progress Self-organization In progress Local aggregate function fp for the neighborhood of p
Self-organization Node 25 contacts 119 to join the system succ(119) 25 0 11 119 108 36 pre(119) 43 96 91 60 Before
Self-organization Time complexity of join is O(N). Too large! 0 11 119 25 108 36 43 96 After 91 60 To qualify for being “self-organizing” join or leave should be completed in sublinear time (Dolev 2007)
Self-organization in Chord Contacts 119 to Join the system 25 0 11 +1 119 +2 +4 108 36 +16 43 96 91 60 Before
Self-organization in Chord 0 11 119 25 108 36 43 96 After 91 60 Time complexity of join is O(log N). It is self-organizing
Self-organization vs Self-stabilization Self-organizing systems Self-stabilizing systems
Self-organization vs Self-stabilization 0 25 0 119 11 fault 119 25 43 96 108 36 91 108 11 43 ? 96 92 92 91 60 36 60 Self-organizing but not self-stabilizing to the legal configuration (“single ring”)
Self-optimization Processes collectively try to maximize or minimize a cost metric related to the system configuration. Example: minimum spanning tree construction.
Self-optimization The perception of the cost may be global or individual. In traditional solutions, all processes cooperate. When processes are selfish, the perception of the cost is individual. Game theory is rich in dealing with such issues.
Pay $a for each link you buy Pay $1 for every hop to every node Network Creation Game (Fabrikant et al PODC 2003) • N nodes, each represented by a vertex and can buy (undirected) links to a set of others (si) • One agent buys a link, but anyone can use it • Cost to node: Distance from i to j
2 1 -1 3 -3 4 2 1 c(i)=2+9 Example + c(i)=+13 (Convention: arrow from the node buying the link)
Some questions • Will the system of processes reach a Nash equilibrium? • If so, what is the relationship between the equilibrium • topology and ? • Fabrikant et al. (PODC 2003) discuss some cases and make some conjectures. • Moscibroda, Schmidt and Wattenhofer (PODC 2006) showed examples where the system may never reach an equilibrium.
No equilibrium The shortest path tree computation by the three nodes has no equilibrium configuration. The edge costs shown are for (black, white, grey)
No equilibrium (white, black) Max flow tree 9, 7 6,7 7,0 9, 7 r 9,1 7,9 9,0 6,9 Each node tries to push the maximum flow to the root
Research questions What are the necessary conditions for the existence of such non-equilibrium configurations? What are the sufficient conditions? Are such conditions locally detectable?
Research issues Algorithms for implementing self-* properties relevant to specific systems or applications (algorithmic research: what is possible, what is impossible, bounds, complexity etc.) New type of properties that may be meaningful (can a system learn from failure history and be smarter? How can a system gracefully degrade?) New approaches to solving problems (can we reverse engineer some natural phenomenon to implement some of the self-* properties?
Sample research problems N processes in a P2P network. Each process j has a preferred set of peers nbr(j), but a degree << |nbr(j)| << N How will each process choose its neighbors, so that the total communication cost (number of hops) to its preferred set of peers is minimum?
Sample research problem (Handling churn in a P2P network) Nodes join and leave at a high rate R/unit time. How to devise an efficient replication mechanism so that (1) at least one copy of each object always exists, and (2) is accessible to all peers?
Self-healing As it stands now, it seems to be as generic as the term “fault-tolerance.” No clear definition has emerged, but mostly local recovery from “minor failures” (not necessarily limited to join or leave) is implied. Some allow graceful degradation after healing.
Graceful degradation Other interpretations are possible too Q P Degraded Configuration P’ P, Q are predicates on the global states
Self-healing On August 15, 2007, Skype was down for 48 hours Skype designers claimed that Skype was self-healing. So, what went wrong? The company described it as a “failure in their self-healing mechanism” Villu Arak. What happened on August 16, 2007. http://heartbeat.skype.com/2007/08/what-happened-on-august-16.html
Example of self-healing System monitors the failure of components, and proactively protects the system from major failures. Example. Fine-grained component-level restarts, micro-reboots, help increase availability (Candea, Cutler, Fox, 2004).
Micro-reboot in Mercury OS (Mercury OS : Candea, Cutler, Fox, 2004). • Failure monitor (M) continuously performs liveness check and tells R of failure • Recovery module (R) It uses reboot tree to decide which component must be rebooted. • Prevents Infinite reboots.
The Reboot Tree • Reboot failed component • Doesn’t work, move to parent • Repeat until entire system • is rebooted
Self-healing with learning Refinement . System gradually learns about failures while it is running, predicts / anticipates failures, and eventually proactively protects itself. Thus the system “gets better with time.” It drops its protective gears when there is no failure. (By profiling failures at run time, the system potentially lowers the overhead of healing when there is no failure).
Self-protection Mainly refers to protection from external threats. The remedy depends on the actual system and the nature of threats. (Identity theft, Virus, Hacking) are the common threats for the IT installations, but the threats may be different in a sensor network. The system should successfully recognize such threats and defend using local knowledge.
Self-protection Biology and nature provide helpful hints. For example, systems with diversity, modularity and redundancy are less susceptible to failure from external attacks. linux windows xyz
New challenges:cyber-physical systems Deal with the interaction between Distributed computing and Physical processes Examples: UAV, collision avoidance systems, cooperating mobile robots. Such systems must continuously self-organize, adapt to changes, guarantee real-time response, safety etc.
Conclusions Many other self- properties are possible. Self-aware (learning about ones own behavior) Self-scaling Self-configuring Self-repairing The definitions need to be cleaned up.
Conclusions Biology & nature Control theory Autonomic systems ? ? algorithms
Robot swarm EU funded I-SWARM project (University of Karlsruhe) Spy fly project in Harvard