Download

1 / 2

E N D
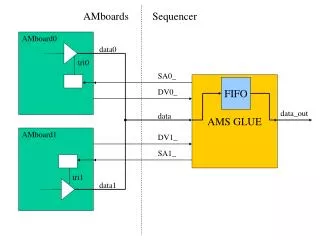
AWS Glue Pipeline The AWS Glue Pipeline allows you to execute SQL queries on a large dataset. It has several features, including Data Ingestion, Data Replication, Job Bookmarks, and Cost. Let's go over the features and how to use them. We'll also discuss how to configure the AWS Glue Console. Data Ingestion AWS Glue is a tool that allows programmatic data integration. It is a free, portable, reusable service that allows users to write and run custom code to process data. This service can be used to build and execute data transformation pipelines. It supports Parquet, ORC, and Streaming ETL jobs. It also provides a unified data catalog and helps users find matching records. AWS Glue enables data ingestion by creating an ETL job in the AWS Management Console. The data is then pointed to AWS Glue, which creates code for data loading and transformation. It also stores metadata in the Data Catalog. This data is then used for reporting and other analysis tasks. Glue also offers tools for data preparation and visualization, such as DataBrew, which helps users clean and normalize their data before it is used. Glue also lets users create a unified view of their data with Elastic Views. Another great feature of Glue is that it allows users to group files together and perform operations on them as a single group. This helps prevent memory pressure on the driver and increases performance. Data Replication AWS Glue is a powerful data pipeline tool that allows you to easily replicate data from one data warehouse to another. It's free, portable, and customizable. You can also create customized alerts for each pipeline. AWS Glue works with Snowflake's data warehouse as a service, so you don't have to worry about maintaining your own data warehouse infrastructure. There are two types of pipelines available: AWS Glue and AWS Data Pipeline. AWS Glue provides end-to-end data pipeline coverage, while AWS Data Pipeline is more focused on designing a data workflow. AWS Glue supports both on-premises databases and on-cloud data warehouses. AWS Glue also handles dependencies between jobs, using external sources as triggers. You can create workflows manually or create them automatically. Both tools use ElasticViews to monitor changes in source data and provide updates to target data automatically. The initial pipeline was not designed for isolation, so it was difficult to test and manage. The first step of the pipeline was not automated, and it involved multiple steps that could not be automated. It also included Lambda functions and CloudWatch events, which made it difficult to test and manage. A different architectural choice would have been better.
Job Bookmarks The AWS Glue Pipeline includes job bookmarks, which enable you to track data processed in each run of an ETL job. They also enable rewinding, reprocessing subsets of data, and backfilling scenarios. Job bookmarks are a powerful tool, but many customers have encountered problems while using them, including when custom jobs are used. These custom jobs require the use of several parameters that are specific to AWS Glue. VISIT HERE To create an ETL job, navigate to the main AWS Glue Studio interface and click on "Create job." Click on the Create job panel, and select "Visual with blank canvas" to create an empty job. After creating the job, you can set metrics and reasons for failure. This feature is useful when incremental data is needed. It enables you to process data from relation database systems and S3 buckets without processing all of it at once. For example, if a dataset contains a number of records, you can create a new dataset and then process it again using the same data set. Cost The AWS Glue Pipeline cost is $0.44 per Data Processing Unit (DPU) or per hour of usage. This tool provides the necessary features and data warehouse functionality to help businesses build and deploy ETL solutions. The service comes with three core components, the data catalog, ETL pipeline, and the serverless streaming ETL function. The data catalog acts as a central repository of metadata and indexes data objects and locations, which are used to define the targets of ETL jobs. Glue is a data warehouse service that allows you to load data from various sources, validating, transforming, and storing it in a central data warehouse. It supports data loading from static and streaming sources. It also scales automatically to meet your current demands. It also collects metrics and logs of ETL procedures. AWS Glue costs $0.44 per hour, or $21 per day. It also supports writing to Dynamic Frames. Both services offer more flexibility for pricing, with a lower rate for low-frequency use than for high-volume use. You can also get a free tier with AWS Glue.