Compiler and Runtime Support for Shared Memory Parallelization of Data Mining Algorithms
This paper explores the potential of parallelizing data mining algorithms using compiler and runtime support in shared memory systems. It highlights the value of high-performance computing beyond traditional scientific applications, specifically addressing commercial settings where parallel configurations are prevalent in database servers. Key data mining techniques like K-means and Apriori are analyzed, along with challenges such as race conditions and memory overheads. The research presents middleware support, language interfaces, and experimental results to demonstrate effective parallelization strategies that significantly improve algorithm performance. ###


Compiler and Runtime Support for Shared Memory Parallelization of Data Mining Algorithms
E N D
Presentation Transcript
Compiler and Runtime Support for Shared Memory Parallelization of Data Mining Algorithms Xiaogang Li Ruoming Jin Gagan Agrawal Department of Computer and Information Sciences Ohio State University
Motivation • Languages, compilers, and runtime systems for high-end computing • Typically focus on scientific applications • Can commercial applications benefit ? • A majority of top 500 parallel configurations are used as database servers • Is there a role for parallel systems research ? • Parallel relational databases – probably not • Data mining, decision support – quite likely
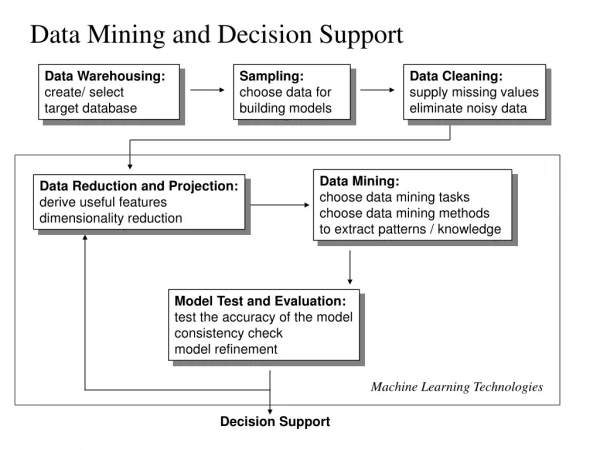
Data Mining • Extracting useful models or patterns from large datasets • Includes a variety of tasks - mining associations, sequences, clustering data, building decision trees, predictive models - several algorithms proposed for each • Both compute and data intensive • Algorithms are well suited for parallel execution • High-level interfaces can be useful for application development
Data Parallel Java Compiler Techniques FREERIDE(middleware) Runtime Techniques Project Overview MPI+Posix Threads+File I/O Clusters of SMPs
Outline • Key observation from mining algorithms • Parallelization Techniques • Middleware Support and Interface • Language Interface and Compilation techniques • Experimental Results • K- means • Apriori • Summary
Common Processing Structure • Structure of Common Data Mining Algorithms {* Outer Sequential Loop *} While () { { * Reduction Loop* } Foreach (element e) { (i,val) = process(e); Reduc(i) = Reduc(i) op val; } } • Applies to major association mining, clustering and decision tree construction algorithms
Outline • Key observation from mining algorithms • Parallelization Techniques • Middleware Support and Interface • Language Interface and Compilation techniques • Experimental Results • K- means • Apriori • Summary
Challenges in Parallelization • Statically partitioning the reduction object to avoid race conditions is generally impossible. • Runtime preprocessing or scheduling also cannot be applied • Can’t tell what you need to update w/o processing the element • The size of reduction object means significant memory overheads for replication • Locking and synchronization costs could be significant because of the fine-grained updates to the reduction object.
Parallelization Techniques • Full Replication: create a copy of the reduction object for each thread • Full Locking: associate a lock with each element • Cache Sensitive Locking: one lock for all elements in a cache block • Optimized Full Locking: put the element and corresponding lock on the same cache block
Memory Layout for Various Locking Schemes Full Locking Cache-Sensitive Locking Optimized Full Locking Lock Reduction Element
Outline • Key observation from mining algorithms • Parallelization Techniques • Middleware Support and Interface • Language Interface and Compilation techniques • Experimental Results • K- means • Apriori • Summary
Middleware Support for Shared Memory Parallelization • Interface Requires: • Specification of an iterator and termination condition • Local reduction for each parallel loop • Functionality • Fetch data elements chunk by chunk, apply local reduction • Parallelization and Synchronization • Global reduction for all threads • Check termination condition, move to next iteration
Example :Kmeans Clustering Algorithm • Problem: -Given N points in a metric space and a distance function. -Try to find K centers and assign each point to one of these centers. -Minimize total distance between each point and the center it belongs to. • Algorithm • Make initial guesses for the centers m1, m2, ..., mk Until there are no changes in any center • Use the estimated centers to classify the points into clusters • For i from 1 to k • Replace mi with the mean of all of the pointss for Cluster i • end_for • end_until
Programming Interface: k-means example • Initialization Function void Kmeans::initialize() { for (int i=0;i<k;i++) { clusterID[I]=reducobject->alloc(ndim); } {* Initialize Centers *} }
Find a nearest center Assign point to the center k-means example (contd.) • Local Reduction Function void Kmeans::reduction(void *point) { for (int i=0;i<k;i++) { dis=distance(point,i); if (dis<min) { min=dis; min_index=i; } for (int j=0;j<ndim;j++) reductionobject->Add(objectID,j,point[j]); reduction object->Add(objectID,ndim,1); reductionobject->Add(objectID,ndim+1,dis); } }
Outline • Key observation from mining algorithms • Middleware Support for Shared Memory Parallelization • Interface and Compilation techniques • Experimental Results • K- means • Apriori • Summary
Language Support A data parallel dialect of Java: to give compiler information about independent collections of objects, parallel loops and reduction operations — domain & rectdomain — foreach loop — reduction interface: - can only be updated inside a foreach loop by operations that are associative & commutative -intermediate value of the reduction variables may not be used within the loop, except for self-updates
Input Data Reduction Loop K-means Clustering expressed by Data Parallel Java public class Kmeans { public static void main(String[] args) { RectDomain<1> InputDomain=[lowend:hiend]; KmPoint[1d] Input=new KmPoint[InputDomain]; While (not_converged) { foreach (p in InputDomain) { min=MIN_NUMBER; for ( i=0;i<k;i++) { int dis=kcenter.distance(Input[p],i); if(dis<min) { min=dis; minindex=i; } } kcenter.assign(Input[p],minindex,min); } kcenter.finalizing(); } }}
Tasks of Compilation • Mapping from reduction interface in our dialet of Java to reduction object used by middleware - Parallelization techniques are transparent to compiler by using reduction object. • Extract important function from Java code to fit into our middleware -Data fetching -Local reduction -Iterator and termination condition
Mapping of Reduction interface • Decide the size of reduction object to be allocated. -By declaration information of reduction interface -By symbolic analysis if can not decide statically • Allocation of reduction object -Layout can be block or cyclic • Changed reference and modification of members to corresponding elements of reduction object. x[1]=0 (*reductionElement)(reduct_buffer,1)=0
Extract important functions • Local reduction function -From body of data parallel loop -Cumulative and associative operations on reduction interface are replaced by operator of reduction object. meansx1[i]+=Input[p].x2 reducObject->Add(reduct_buffer, I,Input.x1) • Iterator and termination -simple from overall code • Data fetching function - from declaration of input class. -use constructor of input class to provide additional information.
Results • Full Replication achieve best result when size of reduction object is small • Cache Sensitive locking outperforms Full replication and Optimized Full locking as size of reduction object increased Relative performance of Full Replication, Optimized Full locking and Cache-Sensitive Locking : 4 threads, different support levels
Results Comparison of compiler generated and manual versions– Apriori Association Mining (1GB Dataset)
Results Comparison of compiler generated and manual versions– K-means Clustering ( 1GB Dataset, K=100)
Conclusion Provide runtime and compiler supports for shared parallelization of data mining applications. -Different parallelization techniques. -Support of middleware simplifies code generation. -Compiler generated code is competitive.