Download
1 / 10
100 likes | 243 Views
Learning for Structured Prediction Overview of the Material. TexPoint fonts used in EMF. Read the TexPoint manual before you delete this box.: A A A A A A A A A A A A A A A A A. Outline. Type of structures considered Generative vs Discriminative

E N D
Learning for Structured PredictionOverview of the Material TexPoint fonts used in EMF. Read the TexPoint manual before you delete this box.: AAAAAAAAAAAAAAAAA
Outline • Type of structures considered • Generative vs Discriminative • Global discriminative vs local discriminative • Decoding: • at testing vs at learning • methods for decoding • Predefined features vs latent features • I will use red italic to have illustration of methods; oversimplify some points
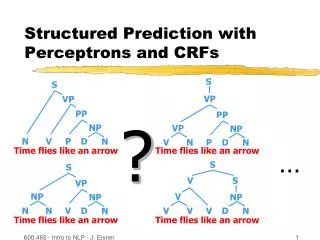
Types of Structures • Sequences: • Chain CRFs, HMMs, (chain type) M3Ns, .... • Trees: • Constituency trees: weighted CFGs (including LA-PCFGs), left-corner/shift-reduce parsers (the MaxEnt parser, ISBN parser,...) • Dependency structures: MST-parser, Nivre’s shift reduce parser, ... • Rankings • Prank (today) • Not considered: DAGs (e.g., some semantic representations), Bipartite graphs (machine translation), or more general graphs ...
Generative vs Discriminative • Discriminative: CRFs, MEMM, Structured Perceptron, Max-Margin Markov Networks (M3Ns),... • Learn mapping from to , so that expected error is minimal • Pros: • model what you actually care about • complex features of x are easy to integrate • different errors can be considered • less assumptions (and therefore, better asymptotic performance) • Generative • Score how likely is the combination of input and output • Pros: • easier to learn (if everything is observable – ML parameters are normalized counts) • “cleaner” semi-supervised learning , select to maximize • often, better with small datasets • some approaches care about (speech recognition, statistical machine translation,...) • arguably, preferable with latent variables HMMs, PCFGs (including the LA-PCFGs), ...
Global Discr. vs Local Discr. • Local (distribs over small decsions) MEMMs, SVM decision classifiers in Nivre’s shift reduce parser • Pros: • no real decoding at training time (cheap learning) • complex features of can be integrated easily (about training! still need to decode at testing) • Cons: • mismatch btw test and train modes: rely on true features in training and on predicted ones in testing • label bias (cannot dump a unlikely transition if the number of outgoing states is not sufficiently large) • Global (distribs over the entire sequences) structperceptron, CRFs, M3Ns (model: MST parser) • Pros • Theoretically much cleaner and in practice works better • Cons • Decoding at training time (+ partition function for CRFs); but approximate learning methods exist • Learning can be very problematic if complex features of are used • Both models require decoding at testing. Decoding does not really depend on the training criteria but on the features of
Specific learning criteria • CRFs • Maximize • Perceptron • Ensure separability on the training set (with large margin in some variations – e.g., ALMA): rank correct structure above incorrect one • Max-Margin Markov Networks (M3Ns) • Separate training set with maximal margin (sensitively to the error) • For every labeled example • where is any structure, is some loss function (e.g., Hamming distance for sequence measuring how many labels do not match) • “Wrong sequences with small errors should be penalized less than with more errors” • SVM-Struct, Boosting, ....
Decoding at training vs testing: examples • Different combinations are possible ....
Inference (argmax) • Simple dependencies in y: • Viterbi to find the most likely sequence (or, Chi-Liu-Edmonds for MST) • Or, marginal decoding to find the most likely label for every “position” • Complex dependencies: • Beam or greedy search (or some smarter search methods) • Reformulate the inference problems as a integer linear program and use methods known in ILP • (We do not care here when the inference is used: either at training or testing, or at both)
Latent Variables vs Explicit Features • Explicit features: • Pros: • Mostly convex optimization (no local minima) • Cheaper to learn • Cons: • Models is as good as the features are: extensive feature engineering needed • Non local dependencies in y are often necessary • Latent variable models: • Pros: • Learn how to propagate relevant information (learns complex features from simple ones) • Can learn a model with simple decompositions over extended y -- efficient decoding • Latent representation (e.g., extended parsing states or extended grammar) can potentially be useful in other tasks – multi-task learning • Cons: • Non-convex optimization – need to avoid local minima (tricky) • More expensive to train Most of the model we considered: CRFs, MEMMs, etc LA-PCFGs, ISBNs
Last bits • Term paper: due Mar 31 but send me ideas, outlines, draft well before the deadline (soon!) • Feedback on the content would be very much appreciated (as I am preparing a lecture class with a similar set of topics) • Thanks for participating!!!