Download
1 / 29
290 likes | 418 Views
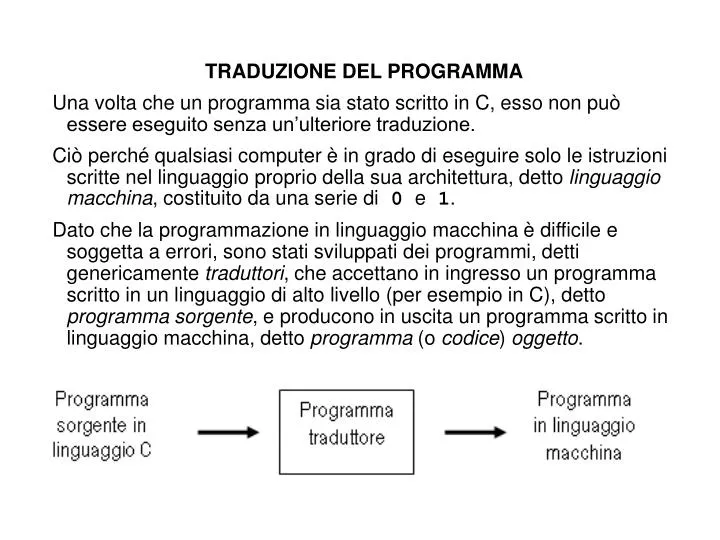
TRADUZIONE DEL PROGRAMMA Una volta che un programma sia stato scritto in C, esso non può essere eseguito senza un’ulteriore traduzione.

E N D
TRADUZIONE DEL PROGRAMMA Una volta che un programma sia stato scritto in C, esso non può essere eseguito senza un’ulteriore traduzione. Ciò perché qualsiasi computer è in grado di eseguire solo le istruzioni scritte nel linguaggio proprio della sua architettura, detto linguaggio macchina, costituito da una serie di 0 e 1. Dato che la programmazione in linguaggio macchina è difficile e soggetta a errori, sono stati sviluppati dei programmi, detti genericamente traduttori, che accettano in ingresso un programma scritto in un linguaggio di alto livello (per esempio in C), detto programma sorgente, e producono in uscita un programma scritto in linguaggio macchina, detto programma (o codice) oggetto.
Un programma può essere tradotto in linguaggio macchina secondo due strategie diverse, ossia usando un programma interprete oppure un programma compilatore: • un programma interprete traduce individualmente ogni istruzione del programma sorgente e la esegue immediatamente; quindi non produce un codice oggetto. • un programma compilatore traduce tutte le istruzioni del programma sorgente in un programma equivalente, prima che ciascuna di esse sia eseguita; quindi produce un codice oggetto. Il C è un linguaggio compilato, quindi il programma sorgente è tradotto come un tutt’uno nel linguaggio macchina. • In realtà, la traduzione di un programma sorgente in un programma eseguibile avviene in due passaggi consecutivi: • il primo eseguito da un programma detto compilatore • il secondo eseguito da un programma detto loader/linker.
Il compilatore dunque accetta in ingresso il programma sorgente e produce in uscita un programma oggetto, scritto nelle istruzioni proprie del microprocessore usato (ossia in linguaggio assembly). In genere il programma oggetto non consiste in un codice adatto per l’esecuzione, codice che sarà prodotto successivamente da un gruppo di tre programmi datti assemblatore, legatore, caricatore.
Intel 4004 Instruction Set Intel 4004 Instruction Set
Programma compilatore. Un compilatore è costituito in realtà da diversi programmi, che eseguono sul sorgente un certo numero di operazioni. Esse si possono dividere in due parti: analisi e sintesi. • L’analisi suddivide il programma sorgente nelle sue parti costituenti e ne crea una rappresentazione intermedia. • La sintesi genera il programma target dalla rappresentazione intermedia. • La parte di analisi si può suddividere nelle seguenti fasi: • analisi lessicale (o lexing); • analisi sintattica (o parsing); • analisi semantica; • La parte di sintesi si può suddividere nelle seguenti fasi: • generazione del codice intermedio; • ottimizzazione del codice; • generazione del codice finale.
Nell’analisi lessicale (o lexing) il programma è considerato come un’unica sequenza di caratteri; essa viene scansionata per individuare gli elementi base del linguaggio che costituiscono un’istruzione, quali parole chiave, identificatori, costanti, operatori, delimitatori, ... Un analizzatore lessicale legge il programma da sinistra a destra e raggruppa le sequenze di caratteri in token, che sono unità lessicali di significato compiuto. La sequenza di caratteri che dà luogo a un token è detta lessema. L’analisi lessicale può rilevare errori relativi alla grafia delle parole chiave o di identificatori creati dall’utente, al formato delle costanti, ... Ad es., il seguente diagramma lessicale permette di stabilire se un identificatore abbia il formato corretto (cioè inizi con una lettera, seguita da lettere e/o cifre).
Una volta eseguita l’analisi lessicale, le fasi successive della compilazione non faranno più riferimento ai singoli caratteri, ma alle parole individuate come elementi di base.
Consideriamo, come esempio, la seguente istruzione di assegnazione: totale = base + increm * 60 L’analizzatore lessicale raggruppa i caratteri nei seguenti token: A questo punto il compilatore costruisce una Tabella dei simboli, dove registra gli identificatori usati nel programma insieme ai loro attributi. Essa ha l’aspetto indicato in figura
Come si vede, gli attributi di un token ID si possono riferire a: memoria allocata, tipo dati, portata o ambito, numero e tipo di argomenti, ecc. Quando viene rilevato un identificatore e generato un token ID, il lessema corrispondente è inserito nella Tabella dei simboli, e al token ID viene associato un puntatore alla posizione nella Tabella. Si ottengono anche una o più tabelle dei simboli contenenti tutti gli identificatori dichiarati nell’ambito del programma come tipi, variabili, procedure, funzioni,... che saranno utilizzate nelle successive fasi di analisi semantica, generazione del codice e gestione della memoria.
Nell’analisi sintattica, o parsing, viene riconosciuta la struttura del programma e viene rappresentato il suo significato in una forma intermedia, dalla quale verrà poi prodotto con semplici trasformazioni il codice oggetto. L’analisi sintattica è guidata dalla definizione formale del linguaggio di programmazione - data per esempio mediante la forma normale di Backus o i diagrammi sintattici - e consente di caratterizzare tutti e soli i programmi “validi”, cioè sintatticamente corretti, e di comprenderne il significato. Ad es., il seguente diagramma sintattico permettere di stabilire se sia stato impiegato un identificatore valido in C
Il diagramma seguente permette invece di controllare la validità di una istruzione if.
Gli errori che si rilevano in questa fase riguardano l’erronea strutturazione del programma a partire dalle proposizioni, ad es. la mancata corrispondenza di parametri in un’espressione, l’assenza di parole chiave attese in determinate posizioni (come il while dopo il do), la mancanza della parola chiave case in corrispondenza di una switch e così via. Come risultato di questa fase si ottiene una forma intermedia (albero, matrice, ...) corrispondente alla struttura sintattica del programma analizzato. I token vengono raggruppati in frasi grammaticali rappresentate da un albero parse, che fornisce una struttura gerarchica al programma sorgente. La struttura gerarchica è espressa da regole ricorsive dette produzioni.
Ad es., produzioni per istruzioni di asegnazione sono: <assegnazione> → ID “=” <espr> <espr> → ID | NUM | <espr><oper> | (<espr>) <op> → + | - | * | / Ecco un esempio di albero parse
Nell’analisi semantica vengono compiute diverse verifiche di consistenza semantica dei concetti utilizzati dal programma. Ad esempio, la frase “il libro legge lo studente” è sintatticamente corretta, mentre risulta errata dal punto di vista del significato. • L’analisi semantica di un programma verifica: • se gli identificatori usati in una procedura siano stati dichiarati nella procedura stessa, • se rispettino le regole di “visibilità” previste dal linguaggio per variabili e procedure, e • se il loro tipo sia coerente con l’uso che ne viene fatto (ad es., i numeri reali non possono essere usati come indici dei vettori). • In caso di errori viene fornita la diagnostica relativa.
Fase di sintesi A partire dalla forma intermedia acquisita durante l’analisi sintattica avviene la generazione del codice intermedio, nella forma di un programma per una macchina astratta. Il codice deve essere facilmente traducibile nel programma target. Tale generazione avviene in base a regole molto semplici, che fanno corrispondere un’istruzione macchina a ciascuna struttura elementare rappresentata nella forma intermedia.
Il codice prodotto nella fase precedente può non essere efficiente. Al fine di ottenere un programma oggetto corto ed efficiente si possono effettuare vari interventi di ottimizzazione del codice. Per esempio spostare all’esterno di un ciclo le istruzioni che non dipendono dalle variabili del ciclo stesso, eliminare il calcolo di espressioni ripetute più volte o semplificare espressioni aritmetiche o logiche. • Questi interventi possono essere: • dipendenti dalla macchina, se tengono conto delle caratteristiche hardware e del repertorio di istruzioni del computer su cui dovrà operare il codice oggetto; • indipendenti dalla macchina, se non ne tengono conto. • I diversi compilatori adottano diverse tecniche di ottimizzazione.
Nella generazione del codice viene prodotto il codice target in linguaggio assembly, una versione mnemonica del codice macchina che usa: • codici operativi o mnemoniche per le operazioni (Tabella dei codici); • nomi simbolici per gli operandi (al posto delle locazioni di memoria) (Tabelle dei simboli); • Vengono scelte le locazioni di memoria per ciascuna variabile, le istruzioni sono tradotte in una sequenza di istruzioni assembly e le variabili e i risultati intermedi sono assegnati ai registri di memoria.
Programmi assemblatore, legatore, caricatore. Il programma assemblatore (assembler) s’incarica di tradurre ciascuna istruzione del codice target in una in linguaggio macchina, producendo un codice in linguaggio macchina secondo lo schema seguente Tuttavia, mentre la traduzione del codice operativo in linguaggio macchina è in ogni caso univoca, non è sempre possibile sostituire immediatamente a ogni riferimento simbolico di locazione di memoria l’indirizzo effettivo della relativa locazione.
Infatti gli operandi che indicano una locazione di memoria possono indicare: • indirizzi assoluti, quali quelli dei dispositivi di ingresso/uscita, che non dipendono ovviamente dalla particolare collocazione del programma in memoria. Essi possono essere tradotti direttamente in indirizzi binari; • indirizzi relativi ai dati e alle istruzioni del codice macchina. Ovviamente tali indirizzi cominciano da 0, e affinché il codice possa esere eseguito correttamente, essi dovrebbero rimanere gli stessi anche quando il codice viene caricato in memoria centrale. Ciò richiederebbe che il codice venisse allocato in memoria a partire dall’indirizzo 0, cosa non sempre possibile; d’altra parte, la grande maggioranza dei codici possono essere caricati in qualsiasi zona di memoria disponibile (per cui sono detti codici rilocabili). Gli indirizzi relativi, che a differenza di quelli assoluti devono essere tradotti in indirizzi di memoria centrale tenendo conto dell’indirizzo di memoria a partire dal quale il programma viene caricato, sono detti anche rilocabili.
Per gli operandi rilocabili l’assemblatore crea, in una prima fase, una tabella dei simboli, nella quale pone i nomi che individua come riferimenti simbolici e la loro posizione relativa nel programma. Solo in una seconda fase gli operandi simbolici saranno sostituiti con gli indirizzi corrispondenti, consultando la tabella dei simboli. Perciò il programma assemblatore viene detto a due passi o fasi.
Programma legatore. Prima della trasformazione definitiva di tutti gli indirizzi in assoluti, è però necessaria un’altra operazione, eseguita dal programma legatore (linker). Esso unisce insieme i differenti file e moduli che possono costituire un sigolo programma (file oggetto), ai quali aggiunge eventualmente dei file di biblioteca (library). Spesso i termini linker e loader sono usati in modo interscambiabile.
Programma caricatore.A questo punto interviene il programma caricatore (loader), per trasformare tutti gli indirizzi in assoluti. Esso memorizza in uno speciale registro base o di riferimento l’indirizzo di memoria a partire dal quale viene caricato il programma(detto indirizzo base), quindi somma tale indirizzo base a ogni indirizzo relativo, ottenendo un indirizzo assoluto.
In tal modo, se sarà necessario spostare il programma in un’altra zona di memoria (processo detto rilocazione), sarà sufficiente modificare il valore dell’indirizzo base. Riassumendo, la trasformazione degli operandi di un programma in linguaggio assembly avviene, nel caso più generale, nelle tre fasi seguenti:
l’assemblatore trasforma gli operandi simbolici in indirizzi assoluti, rilocabili o globali • il legatore trasforma gli indirizzi globali in rilocabili • il caricatore trasforma gli indirizzi rilocabili in assoluti.
Compilatore DMC. In Internet si trovano ottimi compilatori assolutamente freeware. Noi utilizzeremo il compilatore DMC della Digital Mars, che si può scaricare gratuitamente all’indirizzo cliccando sul link:
Si tratta di un programma che esegue la complazione e il link di file C, C++ e ASM in un solo passaggio. Il download crea nella cartella Documenti una cartella dm con alcune sottocartelle:
Dato che il compilatore (dmc.exe) si trova nella sottocartella bin, il modo più veloce (anche se non il più elegante) per provare il funzionamento dei propri programmi in C consiste nel: • salvare il proprio programma in formato solo testo e con estensione .c nella sottocartella bin della cartella dm; • eseguire il programma Prompt dei comandi da • Start → Tutti i programmi → Accessori → • 3. dal prompt C:\Documents … \Documenti> digitare: • cd dm\bin • dmc hello.c • 4. se l’operazione ha successo, vengono creati i tre file hello.exe, hello.map, hello.obj, il primo dei quali si può ora eseguire con il comando • hello






















