Translation Look-Aside Buffers
200 likes | 397 Views
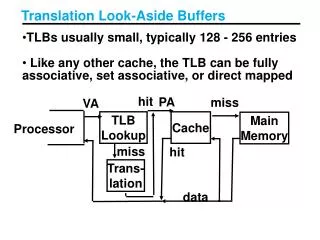
Translation Look-Aside Buffers. TLBs usually small, typically 128 - 256 entries Like any other cache, the TLB can be fully associative, set associative, or direct mapped. hit. PA. miss. VA. TLB Lookup. Cache. Main Memory. Processor. miss. hit. Trans- lation. data. PA. VA. TLB.

Translation Look-Aside Buffers
E N D
Presentation Transcript
Translation Look-Aside Buffers • TLBs usually small, typically 128 - 256 entries • Like any other cache, the TLB can be fully associative, set associative, or direct mapped hit PA miss VA TLB Lookup Cache Main Memory Processor miss hit Trans- lation data
PA VA TLB Main Memory CPU Cache hit data Virtual Address Cache Only require address translation on cache miss! Every time a process is switched, the cache need to be flushed.(without PID) I/O using PAs must translate them to VAs to interact with virtual cache. synonym problem (aliasing): two different virtual addresses map to same physical address => two different cache entries holding data for the same physical address! nightmare for update: must update all cache entries with same physical address or memory becomes inconsistent determining this requires significant hardware, essentially an associative lookup on the physical address tags to see if you have multiple hits.
Optimal Page Size ° Minimize wasted storage — small page minimizes internal fragmentation — small page increase size of page table ° Minimize transfer time — large pages (multiple disk sectors) amortize access time cost a page of 1024 bytes : seek, latency, transfer times 20, 8, 0.4 ms = 28.4ms two page of 512 bytes: 28.2ms x 2 = 56.4ms — sometimes transfer unnecessary info, prefetch useful data, discards useless data early General trend toward larger pages because — big cheap RAM — increasing memory / disk performance gap — larger address spaces
Virtual Address 10 TLB Lookup V page no. offset Access Rights V PA Physical Address 10 P page no. offset • As described, TLB lookup is in serial with cache lookup: Machines with TLBs go one step further: they overlap TLB lookup with cache access. • Works because lower bits of result (offset) available early
Overlapped TLB & Cache Access • So far TLB access is serial with cache access • can we do it in parallel? • only if we are careful in the cache organization! Direct-mapped Cache TLB assoc lookup index 1 K 32 10 2 20 4 bytes page # disp VA 00 PPN TLB Hit/Miss = Data PPN Cache Hit/Miss What if cache size is increased to 8KB?
Problems With Overlapped TLB Access Overlapped access only works as long as the address bits used to index into the cache do not changeas the result of VA translation This usually limits things to small caches, large page sizes, or high n-way set associative caches if you want a large cache Example: suppose everything the same except that the cache is increased to 8 K bytes instead of 4 K: 11 2 cache index 00 This bit is changed by VA translation, but is needed for cache lookup 12 20 virt page # disp Solutions: 1. go to 8K byte page sizes; 2. go to 2 way set associative cache; or 3. SW guarantee VA[13]=PA[13] 2 way set assoc cache 1K 10 4 4
Cache Data Cache Tag Valid Cache Block 0 : : : Compare Parallel set-associative cache and TLB associative lookup TLB PPN 10 2 20 VA page # disp 00 TLB Hit/Miss Cache Index Valid Cache Tag Cache Data Cache Block 0 : : : Addr Tag Addr Tag Compare 1 0 Mux Sel1 Sel0 OR Cache Block Hit
Page Fault( Valid bit = 0 in page table) • Not talking about TLB miss • TLB is HW attempt to make page table lookup fast (on average) • Page fault means that page is not resident in memory • Hardware must detect situation • Hardware cannot remedy the situation • Therefore, hardware must trap to the operating system so that it can remedy the situation • pick a page to discard (possibly writing it to disk) • load the page in from disk • update the page table • resume to program so HW will retry and succeed!
Page Replacement Algorithms If there is a free frame, use it. Just like cache block replacement, but much more time to think! Algorithm in software. Architecture only responsible for PT status First-in/First-Out: -- in response to page fault, replace the page that has been in memory for the longest period of time -- an old, but frequently referenced, page could be replaced -- easy to implement: maintain history thread thru page table entries(replace the page at the head of the queue, and insert the new page brought in at the tail of the queue), no need to track past reference history -- usually exhibits the worst behavior! Least Recently Used: -- selects the least recently used page for replacement -- requires knowledge about past references update frame list on every reference!
Hardware / Software Boundary • What aspects of the Virtual -> Physical Translation is determined in hardware? • Type of Page Table • Page Table Entry Format • TLB Format • Disk Placement • Paging Policy
Warping the Hardware / Software Boundary Load Instruction SW VA -> PA; if miss[PA] load_block[PA] R <= Cache[PA] HW Page Fault Operating System Boundary Page Fault Handler, ... Disk Driver Routines
Overall Operations of a memory hierarchy Cache TLB Virtual Mem Possible? hit hit hit possible miss hit hit possible, cache miss hit miss hit possible, TLB miss miss miss hit possible, TLB and cache misses miss missmiss possible, TLB and cache misses, page fault miss hit miss impossible hit hit miss impossible hit miss miss impossible
Working Set: pages that is actively used in memory At any given point, the program heavily accesses a restricted set of pages for most recent page references — the working set with a parameter given the past n references, compute the number of faults with k pages, for each k. The optimal size of the working set is the knee of the curve. Transitions between working set result in high fault rates. fault rate K (page frames)
System can attempt to monitor the working set for each process. too many faults => need to enlarge number of frames if the sum of working set sizes exceeds the total number of available frames, select a process to suspend (prevent thrashing) as frames grow stale(old) , take them back when a job is swapped, swap its working set — what about very large memories
Physical View vs Logical View 16Kbyte, direct-mapped cache with 32byte block size (no valid, dirty, LRU bits) Logical View 00 Cache Tag 512 x 18 Cache Data 512 x 256 18 9 3 2 = 32 Physical View 00 Data RAM 4K x 32 Tag RAM 512 x 18 18 9 3 2 12 = 32
Difficulties in LRU Implementation Facts: On cache hit, update (read and write) LRU bit. On cache miss, read LRU bit for cache block replacement. Difficulties: LRU must be updated after hit/miss is detected. Longer delay -> Critical path
Page Replacement: Not Recently Used Associated with each page is a reference flag such that ref flag = 1 if the page has been referenced in recent past = 0 otherwise -- if replacement is necessary, choose any page frame such that its reference bit is 0. This is a page that has not been referenced in the recent past page fault handler: dirty used 1 0 page table entry last replaced pointer (lrp) if replacement is to take place, advance lrp to next entry (mod table size) until one with a 0 bit is found; this is the target for replacement; As a side effect, all examined PTE's have their reference bits set to zero. 1 0 page table entry 1 0 0 0 Or search for the a page that is both not recently referenced AND not dirty. Architecture part: support dirty and used bits in the page table/tlb => may need to update PTE on any instruction fetch, load, store
Summary : why virtual memory? (1) ° Generality ability to run programs larger than size of physical memory ° Storage management allocation/deallocation of variable sized blocks is costly and leads to (external) fragmentation ° Protection regions of the address space can be read only, executable, . . . ° Flexibility portions of a program can be placed anywhere, without relocation
Summary : why virtual memory? (2) ° Storage efficiency retain only most important portions of the program in memory ° Concurrent I/O execute other processes while loading/dumping page ° Expandability can leave room in virtual address space for objects to grow. ° Performance Observe: impact of multiprogramming, impact of higher level languages
Conclusion about VM • Virtual Memory invented as another level of the hierarchy • Controversial at the time: can SW automatically manage 64KB across many programs? • DRAM growth removed the controversy • Today VM allows many processes to share single memory without having to swap all processes to disk, protection more important • (Multi-level) page tables to map virtual address to physical address • TLBs are important for fast translation • TLB misses are significant in performance


















