Download

1 / 45
470 likes | 779 Views
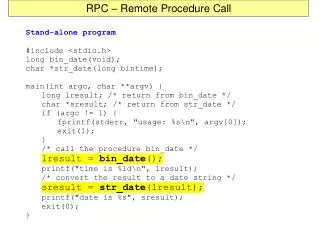
Remote Procedure Calls (RPC). - Swati Agarwal. RPC – an overview. Request / reply mechanism Procedure call – disjoint address space. client. server. request. computation. reply. Why RPC?. Function Oriented Protocols Telnet, FTP

E N D
Remote Procedure Calls (RPC) - Swati Agarwal
RPC – an overview • Request / reply mechanism • Procedure call – disjoint address space client server request computation reply
Why RPC? • Function Oriented Protocols • Telnet, FTP • cannot perform “execute function Y with arguments X1, X2 on machine Z” • Construct desired program interface • Build run time environment – format outgoing commands, interface with the IPC facility, parse incoming response
Why RPC ? (cont.) • Why not give transparency to programmers? • Make programmers life easy !! • Distributed applications can be made easier • Solution – Formalize a separate protocol • Idea proposed by J. E. White in 1976
Implementing Remote Procedure Calls- Andrew Birrell, B. J. Nelson • Design issues reflected + how these can be addressed • Goals • Show that RPC can make distributed computation easy • Efficient RPC communication • Provide secure communication with RPC
Issues faced by designers • Binding • Communication protocol • Dealing with failures – network / server crash • Addressable arguments • Integration with existing systems • Data Integrity and security
Issue : Binding • Naming - How to specify what to bind to? • Location - How to find the callee’s address, how to specify to the callee the procedure to be invoked? • Possible solutions : - Specify network addresses in applications - Some form of broadcast protocol - Some naming system
Issue : Binding - Solution • Grapevine • Distributed and reliable database • For naming people, machines and services • Used for naming services exported by the server • Solves Naming problem • Primarily used for delivery of messages (mails) • Locating callee similar to locating mailboxes • Addresses Location problem • For authentication
Binding cont.. • Exporting machine - stateless • Importing – no effect • Bindings broken if exporter crashes • Grapevine allows several binding choices : • Specify network address as instance • Can specify both type and instance of interface • Only type of interface can be specified – most flexible
Issue : Packet-level Transport Protocol • Design specialized protocol? • Minimize latency • Maintaining state information (for connection based) unacceptable – will grow with clients • Required semantics • Exactly once – if call returns • Else report exception
Simple Calls • Arguments / Results fit in one packet
Simple Calls (cont..) • Client retransmits until ack received • Result acts as an ack (Same for the callee, next call packet is a sufficient ack) • Callee maintains table for last call ID • Duplicate call packets can be discarded • This shared state acts as connection – no special connection establishment required • Call ID to be unique – even if caller restarts • Conversation identifier – distinguish m/c incarnations
Advantages.. • No special connection establishment • In Idle state • Callee : only call id table stored • Caller : single counter sufficient (for sequence num) • No concern for state of connection – ping packets not required • No explicit connection termination
Complicated Calls • Caller retransmits until acknowledged • For complicated calls – packet modified for explicit acks • Caller sends probes until gets response • Callee must respond • Type of failure can be judged (communication / server crash) – exception accordingly reported
Exception Handling • Emulate local procedure exceptions – caller notified • Callee can transmit an exception instead of result packet • Exception packet handled as new call packet, but no new call invoked instead raises exception to appropriate process • Call failed - may be raised by RPCRuntime • Differs from local calls
Processes - optimizations • Process creation and swap expensive • Idle server processes – also handle incoming packets • Packets have source / destination pids • Subsequent call packets can use these • Packets can be dispatched to waiting processes directly from interrupt handler
Other optimization – • Bypass software layers of normal protocol hierarchy for RPC packets • RPC intended to become the dominant communication protocol • Security • Encryption – based security for calls possible • Grapevine can be used as an authentication server
Performance • Measurements made for remote calls between Dorados computers connected by Ethernet (3 Mbps)
Performance Summary • Mainly RPC overhead – not due to local call • For small packets, RPC overhead dominates • For large packets, transmission time dominates • Protocols other than RPC have advantage • High data rate achieved by interleaving parallel remote calls from multiple processes • Exporting / Importing cost unmeasured
Summary • RPC package fully implemented and in use • Package convenient to use • Should encourage development of new distributed applications formerly considered infeasible
Performance of Firefly RPC - M. Schroeder , M. Burrows) • RPC already gained wide acceptance • Goals : • Measure performance of RPC (intermachine) • Analyze implementation and account for latency • Estimate how fast it could be
RPC in Firefly • RPC – primary communication paradigm • Used for all communication with another address space irrespective of same / different machines • Uses stub procedures • Automatically generated from Modula2+ interface definition
Measurements • Null Procedure • No arguments and no results • Measures base latency of RPC mechanism • MaxResult Procedure • Measures server-to-caller throughput by sending maximum packet size allowed • MaxArg Procedure • Same as MaxResult : measures throughput in opposite direction
Latency and Throughput • The base latency of RPC is 2.66 ms • 7 threads can do ~740 calls/sec • Latency for MaxResult is 6.35 ms • 4 threads can achieve 4.65 Mb/sec • Data transfer rate in application since data transfers use RPC
Marshalling Time • Most arguments and results copied directly • Few complex types call library marshalling procedures • Scale linearly with number of arguments and size of arguments / result – for simple arguments
Marshalling Time - Much slower when library marshalling procedures called
Analysis of performance • Steps in fast path (95 % of RPCs) • Caller: obtains buffer (Starter), marshals arguments, transmits packet and waits (Transporter) • Server: unmarshals arguments, calls server procedure, marshals results, sends results • Caller: Unmarshals results, free packet (Ender)
Transporter • Fill RPC header in call packet • Call Sender - fills in other headers • Send packet on Ethernet (queue it, notify Ethernet controller) • Register outstanding call in RPC call table, wait for result packet (not part of RPC fast path) • Packet-arrival interrupt on server • Wake server thread - Receiver • Return result (send+receive)
Reducing Latency • Usage of direct assignments rather than calling library procedures for marshalling • Starter, Transporter and Ender through procedure variables not through table lookup • Interrupt routine wakes up correct thread • OS doesn’t demultiplex incoming packet • For Null(), going through OS takes 4.5 ms
Reducing Latency • Packet buffer management scheme • Server stub can retain call packet for result • Waiting thread contain packet buffer – this packet can be used for retransmission • Packet buffers reside in memory shared by everyone • Security can be an issue • RPC call table also shared
Improvements • Write fast path code in assembly not in Modula2+ • Speeded up by a factor of 3 • Application behavior unchanged
Proposed Improvements • Different Network Controller • Save 11 % on Null() and 28 % on MaxResult • Faster Network – 100 Mbps Ethernet • Null – 4 %, MaxResult – 18% • Faster CPUs • Null – 52 %, MaxResult – 36 % • Omit UDP checksums • Ethernet controller occasionally makes errors • Redesign RPC Protocol
Improvements • Omit layering on IP and UDP • Busy Wait – caller and server threads • Time for wakeup can be saved • Recode RPC run-time routines
Effect of processors • Problem: 20ms latency for uniprocessor • Uniprocessor has to wait for dropped packet to be resent • Solution: take 100 microsecond penalty on multiprocessor for reasonable uniprocessor performance
Effect of processors • Sharp increase in uniprocessor latency • Firefly RPC implementation of fast path is only for a multiprocessor
Summary • Concentrates upon the performance of RPC • Understand where time is spent • Resulting performance is good, but not demonstrably better than others • Faster implementations exist but on different processors • Performance would be worse on multi-user computer – packet buffers cannot be shared