Download

1 / 33
380 likes | 861 Views
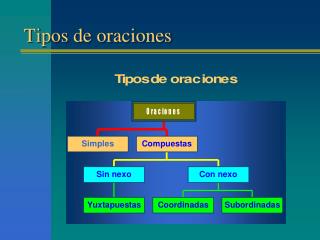
Paralelismo de Tareas. Paralelismo de Datos. Tipos de Paralelismo. Paralelismo de datos: cada procesador ejecuta la misma tarea sobre diferentes conjuntos o subregiones de datos Paralelismo de tareas: cada procesador ejecuta una diferente tarea

E N D
Paralelismo de Tareas Paralelismo de Datos Tipos de Paralelismo • Paralelismo de datos: cada procesador ejecuta la misma tarea sobre diferentes conjuntos o subregiones de datos • Paralelismo de tareas: cada procesador ejecuta una diferente tarea • La mayoría de las aplicaciones están entre estos dos extremos
Paralelismo Maestro-Esclavo • Una común forma de usar paralelismo en el desarrollo de aplicaciones desde hace años (especialmente en PVM) fue el paralelismo Maestro-Esclavo: • un simple procesador es responsable de distribuir los datos y recolectar los resultados (paralelismo de tarea) • todos los otros procesadores ejecutan la misma tarea sobre su porción de datos (paralelismo de datos)
Modelos de Programación Paralela • Los modelos de programación que se usan actualmente son: • Paralelismo de datos - las operaciones son ejecutadas en paralelo sobre colecciones de datos estructurados. • Paso de mansajes - procesos colocados en memoria local se comunican con otros procesos enviando y recibiendo mensajes. • Memoria compartida - cada procesador tiene acceso a un conjunto de memoria compartida
Modelos de Programación Paralela • La mayoría de los esfuerzos en paralelización están dentro de las siguientes categorias: • Códigos pueden ser paralelizados usando librerías de paso de mensaje tal como MPI. • Códigos pueden ser paralelizados usando directivas de compilación tal como OpenMP. • Códigos pueden ser escritos en nuevos lenguajes paralelos.
Modelos de Programación Arquitecturas • Correspondecia natural • Paralelismo de datos CM-2 (máquina SIMD) • Paso de mensaje IBM SP (MPP) • Memoria compartida SGI Origin, Sun E10000 • Correspondencia implementada • HPF (un lenguaje paralelo de datos) y MPI (una librería de paso de mensaje) -> sobre la mayoría de los computadores paralelos • OpenMP (un conjunto de directivas, etc. para programación de memoria compartida) -> sobre mayoría de máquinas de memoria compartida.
SPMD • Todas las máquinas actuales son MIMD (Multiple Instruction, Multiple Data) y pueden explotar paralelismo de datos o paralelismo de tareas. • El primer paradigma de programación paralela es el SPMD: Single Program, Multiple Data • Cada procesador ejecuta una copia del código fuente • Paralelismo de datos (a través de la descomposición de los datos) y paralelismo de tareas (a través de funciones que retornan al procesador ID)
OpenMP – Estandar para SM • OpenMP es un nuevo estandar para programación en memoria compartida: SMPs y cc-NUMAs. • OpenMP provee un conjunto estandar de directivas, rutinas de librerías run-time • Ambiente de variables para paralelizar códigos bajo el modelo de memoria compartida. • Ver http://www.openmp.org para más información
OpenMP Ejemplo Fortran 77 Fortran 77 + OpenMP program add_arrays parameter (n=1000) real x(n),y(n),z(n) read(10) x,y,z do i=1,n x(i) = y(i) + z(i) enddo ... end program add_arrays parameter (n=1000) real x(n),y(n),z(n) read(10) x,y,z !$OMP PARALLEL DO do i=1,n x(i) = y(i) + z(i) enddo ... end La directiva resaltada especifica que el bucle es ejecutado en paralelo. Cada procesador ejecuta un subconjunto de iteraciones del bucle.
MPI – Estandar de Paso de Mensaje • MPI tiene un estandar para paso de mensaje en C y Fortran. No es necesario conocer MPL, PVM, etc. • MPI es grande y pequeño: • MPI es grande, ya que contiene 125 funciones las cuales dan al programador control fino sobre las comunicaciones • MPI es pequeño, ya que los programas de paso de mensaje pueden ser escritos usando sólo seis funciones
MPI Ejemplos - Send y Receive Los mensajes en MPI son de doble dirección: ellos requieren un send y un correspondiente receive: PE 0 llama a MPI_SEND para pasar la variable realx hacia PE 1. PE 1 llama a MPI_RECV para recibir la variable realy desde PE 0 if(myid.eq.0) then call MPI_SEND(x,1,MPI_REAL,1,100,MPI_COMM_WORLD,ierr) endif if(myid.eq.1) then call MPI_RECV(y,1,MPI_REAL,0,100,MPI_COMM_WORLD, status,ierr) endif
MPI Ejemplo – Operaciones Globales MPI también tiene operaciones globales para hacer broadcast y reduce (collect) de información PE 5 broadcasts the single (1) integer value n to all other processors call MPI_BCAST(n,1,MPI_INTEGER,5, MPI_COMM_WORLD,ierr) PE 6 collects the single (1) integer value n from all other processors and puts the sum (MPI_SUM) into into sum call MPI_REDUCE(n,allsum,1,MPI_INTEGER,MPI_SUM,6, MPI_COMM_WORLD,ierr)
MPI Implementaciones • MPI está implementado para todas las máquinas de memoria distribuida. • MPI es el modelo natural para máquinas de memoria distribuida (MPPs, clusters) • MPI ofrece alto rendimiento para DSMs • MPI es útil en sistemas SMPs que forman clusters • MPI puede ser usado sobre máquinas de memoria compartida
MPI vs. OpenMP • No existe la mejor aproximación para escribir códigos paralelos. Cada una tiene sus ventajas y desventajas: • MPI - poderoso, general, y universal, compuesto de rutinas de paso de mensaje las cuales proveen un control muy fino sobre las comunicaciones, pero obliga al programador a operar en un relativo bajo nivel de abstracción. • OpenMP – conceptualmente es una sencilla aproximación para desarrollar códigos paralelos sobre máquinas de memoria compartida, pero no es aplicable a plataformas de memoria distribuida.
MPI vs. OpenMP • MPI es más general y portable (plataformas, aunque no es eficiente en sistemas SMPs) • La arquitectura y el problema a resolver frecuentemente hacen que la decisión sea suya!!!.
Librerías Paralelas • Finalmente, existen librerías matemáticas paralelas que capacitan al usuario a escribir códigos (serial), que tienen rutinas que llaman a solvers paralelos : • ScaLAPACK es para resolver sistemas lineales densos, autovalores y problemas de minimos cuadrados. También ver PLAPACK. • PETSc es para resolver ecuaciones diferenciales en derivadas parciales lineales y no lineales (incluye varios solvers iterativos para matrices dispersas). • UCSparseLib es para resolver sistemas lineales dispersos (incluye varios solvers iterativos, directos y técnicas multinivel).
Computación Paralela: Tips • Los códigos paralelos rápidos requieren un eficiente uso del escalamiento del hardware • No todos los algoritmos escalares pueden ser paralelizados bien, puede ser necesario repensar el problema • Comunicación: Necesidad de minimizar el gasto del tiempo de comunicación • Balanceo de Carga: Todos los procesadores deben hacer aprox. el mismo trabajo • Ley de Amdahl’s: Limite fundamental de la computación paralela
Rendimiento Escalar • Un código paralelo bien entendido es un buen código escalar. • Si un código escala a 256 procesadores pero sólo se obtiene un 1% de rendimiento pico, éste es un mal código paralelo. • Noticia buena: Cada cosa que usted sabe acerca de la computación serial es útil en la computación paralela! • Noticia mala: Es difícil obtener un buen rendimiento de procesadores y memoria en máquinas paralelas. Se necesita un uso efectivo de caché.
Rendimiento Serial En este caso, el código paralelo ejecuta un perfecto escalamiento, pero es a partir de 32 proc. cuando se supera al serial.
Uso efectivo de la cache Una jerarquía de memoria simplificada • La cache de datos fue diseñada con dos conceptos claves: • Localidad espacial - la cache es cargada con una linea entera (4-32 palabras) para tomar ventaja del hecho de que si un posición de memoria es requerida, posiciones cercanas probablemente también serán requeridas. • Localidad Temporal - una vez que una palabra es cargada en cache, ésta probablemente será utilizada muy pronto. CPU cache pequeña y rápida main memory grande y lenta
Aspectos a considerar • Existen otros aspectos a considerar para obtener un buen rendimiento serial: • Reducciones, ej., reemplazar divisiones por multiplicaciones inversas • Evaluar y reemplzar expresiones comunes • Colocar bucles en subrutinas para minimizar llamadas a subrutinas • Opciones de compilación • Ejecutar análisis interprocedimientos para eliminar operaciones redundantes
Algoritmos Paralelos • El algoritmo debe ser naturalmente paralelo! • Ciertos algoritmos seriales no se paralelizan bien. El desarrollo de nuevos algoritmos paralelos para reemplazar un algoritmo serial puede ser una de las tareas más dificiles en la computación paralela. • Mantener en mente que el algoritmo paralelo puede envolver más trabajo o más operaciones.
Algoritmos Paralelos • Mantener en mente que el algoritmo deberá: • Mínima comunicación • Balance de carga • Afortunadamente, muchos investigadores han desarrollado algoritmos paralelos, particularmente en el área de algebra computacional. No hay que reinventar la rueda, hay que tomar ventaja del trabajo hecho por otra gente: • Usar librerías paralelas desarrolladas, si es posible! • usar ScaLAPACK, PETSc, UCSparseLib, etc. cuando sea aplicable
Tiempo trabajando Tiempo ocioso PE 0 PE 1 Balanceo de Carga La figura abajo, muetsra el tiempo de ejecución para un código paralelo usando dos procesadores. En ambos casos, la cantidad total de trabajo hecho es el mismo, pero en el segundo caso el trabajo está distribuido más efectivamente entre los dos procesadores resultando un tiempo más corto para obtener la solución. PE 0 PE 1 t Puntos de sincronización
Comunicaciones • Dos parámetros claves en las redes de comunicación son: • Latencia: tiempo requerido para inicializar un mensaje. Este es un parámetro critico en los códigos grano fino, el cual requiere mucha comunicación entre procesadores. • Ancho de Banda: porcentaje de sostenibilidad el cual los datos pueden ser enviados a través de la red. Este es un parámetro critico en códigos grano grueso, el cual requiere comunicación de grandes cantidades de datos.
Más sobre Comunicaciones • El tiempo que se gasta ejecutan una comunicación es considerado overhead. Minimizar el impacto de la comunicación: • Minimizar el efecto de la latencia combinando grandes números de pequeños mensajes dentro de pequeños números de grandes mensajes. • Comunicación y cálculo no tiene que hacerse secuencialmente, se pueden solapar. Sequential: t = t(comp) + t(comm) Overlapped: t = t(comp) + t(comm) - t(comp) t(comm)
Combinando pequeños mensajes dentro de uno más grande El siguiente ejemplo de “teléfono” ilustra la importancia de combinar muchos mensajes pequeños en una más grande. • dial • “Hola máma” • hang up • dial • “Como están las cosas?” • hang up • dial • “en Venezuela.?” • hang up • dial • …… • dial • “Hola máma. Como están las cosas en Venezuela.?. Bla ..Bla...” • hang up Transmitiendo un mensaje grande, se Tiene que pagar el precio de la latencia Una sóla vez. Se transmite más Información en menos tiempo.
Solapando Comunicación y Cálculo En el siguiente ejemplo, una operación es ejecutada sobre un arreglo 10 x 10 que ha sido distribuido en dos procesadores. Asumiendo condiciones periódicas en la frontera. PE1 PE0 operación: y(i,j)=x(i+1,j)+x(i-1,j)+x(i,j+1)+x(i,j-1) • Inicializar comunicación • Ejecutar cálculo en los elementos internos • Esperar que las comunicaciones finalicen • Ejecutar cálculo en los elementos frontera Elementos frontera – requieren datosdel procesador vecino Elementos internos
Ley de Amdahl’s La Ley de Amdahl’s coloca un limite estricto a la aceleración que puede ser alcanzada usando multiples procesadores. Dos expresiones equivalentes para la Ley de Amdahl’s son dadas a continuación: tN = (fp/N + fs)t1 Efecto de multiples proc. en el tiempo de ejecución S = 1/(fs + fp/N) Efectos de múltiples proc. en la aceleración donde: fs = fracción serial fp = fracción paralela = 1 - fs N = número de procesadores
Ilustración de la Ley de Amdahl’s La fracción serial contenida en un código paralelo degrada el rendimiento. Esto esencialmente determina el escalamiento del código paralelo.
Ley de Amdahl’s Vs. Realidad La Ley de Amdahl’s provee un limite teórico de la aceleración asumiendo que no hay costos de comunicación. En realidad, la comunicación (y I/O) degradan el rendimiento.
Ley de Gustafson’s • La Ley de Amdahl’s predice que existe un máximo de escalabilidad para una aplicación, determinada por la fracción paralela, y este limite, generalmente, no es muy grande. • Existe un manera de solucionar esto: el tamaño del problema crezca • los problemas más grandes tienen mallas más grandes o más particulas: arreglos más grandes. • El número de operaciones seriales generalmente permanece constante; el número de operaciones paralelas crecen: crece la fracción paralela
La 1ra. Pregunta a Responder antes de Paralelizar • Detenerse a pensar • La cantidad de CPU disponibles justifican la paralelización? • Se necesita una máquina paralela para obtener suficiente memoria agregada? • El código va aser usado una sóla vez o se usará para una mayor producción? • El tiempo es valioso, se puede consumir mucho tiempo para escribir, depurar, y probar un código paralelo. Mucho tiempo se gasta en escribir un código paralelo.
La 2da. Pregunta a Responder antes de Paralelizar • Cómo se debe descomponer el problema? • Los computos consisten de un gran número de pequeños e independientes problemas - trayectorias, parámetros del espacio estudiado, etc? Se puede considerar un esquema en el cual cada procesador realiza el cálculo para diferentes conjuntos de datos • Cada computo requiere mucha memoria y CPU? Probablemente hay que distribuir un simple problema hacia multiples procesadores