Decision Trees
340 likes | 359 Views
This text explores decision tree induction, including the ID3 algorithm, handling overfitting, and converting decision trees into rules. It also discusses issues such as continuous attributes, missing attribute values, and attributes with different costs.

Decision Trees
E N D
Presentation Transcript
Root • Outlook!, humidity, wind, temp
Version Space VS Decision Tree • ID3 searches a complete hypothesis space (any finite-valued discrete function). It searches incompletely using hill climbing with the heuristic: Preferring shorter trees with high information gain attributes closer to the root (Inductive bias) • Version spaces search an incomplete hypothesis space completely. Inductive bias arises from the bias in the hypothesis representation
Issues • How deep? • Continuous attributes? • Missing attribute values? • Attributes with different costs?
Overfitting • Tree grows deep enough to perform well on training data. But • There may be noise in the data • Not enough examples • Over-fitting: h overfits the data if h’ does worse on training examples but does better over all instances
Handling Overfitting • Stop growing tree earlier • Post pruning (works better in practice)
Methods • Construct tree then use a validation set – a separate set of examples, distinct from training set to evaluate the utility of post-pruning nodes • Construct Tree with all available data then use statistical tests to determine whether expanding or pruning a node is likely to produce an improvement only on the training example or the entire instance distribution
Training and validation • 2/3 used for training • 1/3 used for validation (Should be a large enough sample) • Validation set is a safety check • Validation set is unlikely to contain the same random errors and coincidental regularities as the training set.
Reduced error pruning • Pruning a node: Remove subtree rooted at that node – make it a leaf node, and give it the most common classification of training examples at that node • Consider each node for pruning • Remove node only if the pruned tree performs no worse than original • Iterate and stop when further pruning decreases decision accuracy on validation set
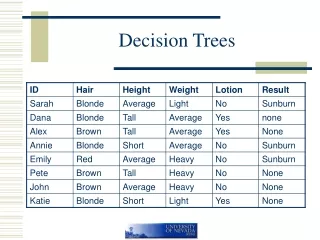
From Trees to Rules • Traverse DT from root to each leaf • Each such path defines a rule • Example • If • ?x hair color is blonde • ?x uses lotion • Then • Nothing happens
If ?x hair color is blonde ?x uses no lotion Then ?x turns red If ?x hair color is red Then ?x turns red If ?x hair color is blonde ?x uses lotion Then Nothing happens If ?x hair color is dark Then Nothing happens Rules from DT
Rule Pruning • Eliminate unnecessary antecedents. Consider: • If ?x hair color is blonde • ?x uses lotion • Then nothing happens • Suppose we eliminate the first antecedent (blonde) • The rule triggers for each person who uses lotion • If ?x uses lotion Then nothing happens • Data shows that nothing happens to anyone using lotion! • Might as well drop the first antecedent since it makes no difference!
Contingency tables • Formalizing the intuition. For those who used lotion: • For those who used lotion, it does not matter if they are blonde or not blonde, they do not get sunburned.
Contingency tables • Formalize the intuition. For those who are blonde: • For those who are blonde, it does matter whether or not they use lotion. Two of those who use lotion get sunburned and two do not.
Contingency tables • If ?x is blonde and does not use lotion then ?x turns red • Eliminate ?x is blonde if ?x does not use lotion then ?x turns red • For those who do not use lotion: • Looks like ?x is blonde is important
Contingency tables • If ?x is blonde and does not use lotion then ?x turns red • Eliminate ?x does not use lotion if ?x is blonde then ?x turns red • For those who are blonde: • Looks like ?x does not use lotion is important
Contingency tables • If ?x is redhead Then ?x turns red • Eliminate ?x is redhead Rule always fires! • Look at Everyone: • Evidently red hair is important
Contingency tables • If ?x is dark haired Then Nothing happens • Eliminate ?x is dark haired Rule always fires! • Look at Everyone: • Is being dark haired important?
Contingency tables • If ?x is dark haired Then Nothing happens • Eliminate ?x is dark haired Rule always fires! • Look at Everyone: • Is being dark haired important?
Eliminate Unnecessary rules • If ?x is blonde; ?x uses no lotion Then ?x is sunburned • If ?x uses lotion Then ?x Nothing happens • If ?x is redhead Then ?x is sunburned • If ?x is dark haired Then Nothing happens • Can we come up with a default rule that eliminates the need for some of the above rules?
Eliminate Unnecessary rules • If ?x uses lotion Then ?x Nothing happens • If ?x is dark haired Then Nothing happens • If no other rule applies • Then Nothing happens
Default rules • If ?x is blonde; ?x uses no lotion Then ?x is sunburned • If ?x is redhead Then ?x is sunburned • If no other rule applies • Then ?x gets sunburned
Eliminate rules using defaults • Heuristic 1: Choose the default rule that eliminates/replaces as many other rules as possible • Both default rules eliminate 2 other rules cannot use this heuristic • Heuristic 2 (to choose among rules identified by heuristic 1): Choose the default rule that covers the most common consequent • 5 not sunburned, 3 sunburned • Choose: If no other rule applies Then nothing happens
General Procedure: Fisher’s exact test cab be used to do this check
Why rules? • Distinguish between different contexts: • Each rule can be considered separately for antecedent pruning. Contrast this with DT. You can remove a node or not? • But there may be many contexts through that node. That is, there may be many rules that go through that node and removing the node means you remove ALL rules that go through that node • If we consider each rule separately, we can consider all contexts of a DT node separately.
Why Rules? • In DTs nodes near root are more “important” than nodes near leaves. • Rules avoid the distinction between attribute tests near the root and those later on. • We can avoid thinking about re-organizing the tree if we have to remove the root node!
Why rules? • Rules may be more readable
Continuous valued attributes • Sort examples according to continuous values • Identify adjacent examples that differ in target values (play?) • Pick one of (48 + 60)/2 and (90 + 80)/2 by evaluating disorder of the new feature “tempGT54” and “tempGT85” • Can also come up with multiple intervals. Use both above?
Feature selection • Search through space of feature subsets for a subset that maximizes performance




















