
一、常態分配:
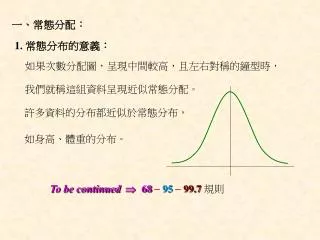
一、常態分配:. 1. 常態分布的意義:. 如果次數分配圖,呈現中間較高,且左右對稱的鐘型時,. 我們就稱這組資料呈現近似常態分配。. 許多資料的分布都近似於常態分布,. 如身高、體重的分布。. To be continued 68 95 99.7 規則. 常態分配有一個特性,它們都遵循 68 95 99.7 規則,. 約有 68% 的資料值落在距 平均數 1 個標準差範圍內,. 約有 95% 的資料值落在距 平均數 2 個標準差範圍內,. 約有 99.7% 的資料值落在距 平均數 3 個標準差範圍內,. 如右圖所示。.

一、常態分配:
E N D
Presentation Transcript
一、常態分配: 1. 常態分布的意義: 如果次數分配圖,呈現中間較高,且左右對稱的鐘型時, 我們就稱這組資料呈現近似常態分配。 許多資料的分布都近似於常態分布, 如身高、體重的分布。 To be continued 68 95 99.7規則
常態分配有一個特性,它們都遵循 68 95 99.7規則, 約有 68%的資料值落在距平均數1個標準差範圍內, 約有 95%的資料值落在距平均數2個標準差範圍內, 約有 99.7%的資料值落在距平均數3個標準差範圍內, 如右圖所示。 68%的資料 95%的資料 99.7%的資料 3 2 +2 +3 +
令平均數為 ,標準差為 ,則 約有 68%的資料值,在區間[ , +] 內, 約有 95%的資料值,在區間[2 , +2]內, 約有 99.7%的資料值,在區間[3 , +3] 內。 注意: (1) 常態分布曲線是對稱的, 故平均數與中位數 都落在曲線的中間位置, 即尖峰所在。 68%的資料 (2) 常態分布的平均數、 95%的資料 中位數與眾數全都相同。 99.7%的資料 3 2 +2 +3 + 本段結束
2. 範例:某校有學生 1000 名,此次數學段考成績呈常態分配, 平均成績 70 分,標準差 10 分, 則:(1) 不及格的學生約有幾名? (2) 成績超過 90 分的有幾名? (3) 成績 80 的校排約第幾名? 解:(1) 約 68% 的資料,在區間 [7010 , 70+10 ] 內,即 [60 , 80] 內。 60 分以下及 80 分以上,共佔 32%, 68%的資料 60 分 以下及 80分 以上,各佔 16%, + 不及格有 100016% = 160 名。 60 70 80 To be continued (2) (3)
68%的資料 + 60 70 80 (1)不及格有 100016% = 160 名。 解:(2) 約 95% 的資料值,在區間 [7020 , 70+20 ]內, 50 分以下及 90 分以上,共佔 5%, 50 分以下及 90 分以上,各佔 2.5%, 90 分以上有 10002.5% = 25 名。 95%的資料 +2 2 50 90 70 (3) 由(1)知,80 分以上約有 160 名, 故 80 分的校排約第 160 名。 Let’s do an exercise !
馬上練習:某校學生 500 名,此次數學段考成績呈常態分配, 平均成績 65.24 分,標準差 5.24 分, 則全校約有多少人不及格? Ans:80人。 解:約 68% 的資料,在區間 [ , +] 內,即 [60 , 70.48] 內。 60 分以下及 70.48 分以上,共佔 32%, 60 分以下及 70.48 分以上,各佔 16%, 不及格有 50016% = 80 人。 #
33% 24% 20% N 12% 6% 5% 30 35 40 45 50 55 60 65 70 75 808590 95 100 體重(公斤) 3. 範例:右圖為 100 婦女體重的直方圖,(圖中百分比為各體重區間 的相對次數)其中各區間不包含左端點而包含右端點。 該 100 名婦女平均體重為 55 公斤,標準差為 12.5 公斤。 曲線 N代表一常態分布,其平均數與標準差與樣本值相同。 在此樣本中,若定義「體重過重」 的標準為體重超過樣本平均數 2 個 標準差以上。下列敘述那些正確? (1) 曲線 N中,在 55 公斤以上 所佔的比例約為50%。 (2) 曲線 N中,在 80 公斤以上 所佔的比例約為2.5%。 (3) 該樣本中,體重的中位數大於 55 公斤。 (4) 該樣本中,體重的第一四分位數大於 45 公斤。 (5) 該樣本中,「體重過重」的比例大於或等於 5% 。 To be continued 詳 解。
33% 24% 20% N 12% 6% 5% 30 35 40 45 50 55 60 65 70 75 808590 95 100 體重(公斤) 解:(1)常態分布平均數55以上佔 50% 55以上約佔 50% 。 (2)常態分布約有 95% 的資料值, 在區間 [2 , +2] 內, 即 [30 , 80] 內。 80 以上佔約佔 2.5% 。 (3) 樣本中,(20%+33%) > 50% Me在 45~55 這組 Me < 55。 (4) 樣本中,20% < 25% < 50% Q1在 45~55 這組 Q1 > 45。 (5) 樣本中,85 ~ 95 佔 5% 過重(80 以上)的比例 5% 。 故正確為 (1) (2) (4) (5)。 #
4. 範例:設已知常態分配累積機率表如下所示。 數據 x 介於 與 +t 之間的機率為 p, 其中 為算術平均數, 為標準差,t 為一正實數, 設某次檢定考有8000人應考,考試成績接近態分配, 算術平均數 = 44.5分,標準差標 = 2.6分,則: (1) 設成績合格標準訂為 38 分,求此次檢定合格的人數約有多少? (2) 設成績優等標準訂為 51 分,求此次檢定優等的人數約有多少? To be continued 詳 解。
數據 x介於 與 + t之間的機率為 p, 38分與平均數(=44.5), 解:(1) (44.538)2.6=2.5 位於相距 2.5 個標準差(+2.5)的位置。 P(x38) = P(38x44.5) + P(x44.5) = 0.4938 + 0.5 = 0.9938。 x + +2 2 +3 3 所求 = 80000.9938 7950人。 44.5 47.1 51 38 = 44.5 , = 2.6 (2) (5144.5)2.6 = 2.5 P(x51) = P(x44.5) P(44.5x51) = 0.50 0.4938 = 0.0062。 所求 = 80000.0062 50人。 #
5. 標準化: 證明: X + +2 +3 2 3 1 3 2 Z 2 0 1 3 本段結束 注意:(1) 算術平均數為 0,標準差為 1的常態分布稱為標準常態分布。 (2) 每個常態分布經由標準化皆可轉化為標準常態分布。
6. 標準常態分配的機率表: 特性:(1) P(zZ0) = P(0Zz)。 (2) P(Z0) = P(Z0) = 0.5。 (3) 若 為一定值,則 P(Z=) = 0。 例如:(1) P(0Z2) = 0.4772。 X + +2 +3 2 3 1 3 2 Z 2 0 1 3 (2) P(Z2) = 1 P(Z2) = 1 [ P(Z0) + P(0Z2)] 本段結束 = 1 (0.5+0.4772) = 0.0228。
7. 範例:某校有學生 1000 名,某次數學段考成績呈常態分配, 平均成績 72 分,標準差 6 分, 利用標準常態分配機率表,求此次及格的學生約有幾名? 解:設此次考試的常態分配為變數 X, P(X 60) = P(Z2) 54 X 84 72 90 60 78 66 Z 3 2 1 1 2 3 0 = P(0Z) + P(0Z2) = 0.5 + 0.4772 = 0.9772。 所求 = 10000.9772 977 人。 #
To be continued 二、信賴區間與信心水準: 1. 信賴區間:做民調時,當我們從母群體中抽取 n個人 組成一個樣本時 (n需足夠大), 若重複抽取樣本(均為 n人)當抽取次數足夠多時, 68%的資料 95%的資料 P為真正的百分率(見附錄) 99.7%的資料 p p+2 p3 p+3 p2 p+ p
To be continued 68%的資料 95%的資料 99.7%的資料 p p+2 p3 p+3 p2 p+ p 由常態分配的概念可知, 之 68 95 99.7
68%的資料 95%的資料 99.7%的資料 同理可得以下結果: p p+2 p3 p+3 p2 p+ p To be continued 信賴區間
一般我們並不知道真正的 p 值,但當抽取的樣本 n很大時, 其標準差會很小,此時,大部分樣本的 68%的資料 因此,我們用 95%的資料 99.7%的資料 p p+2 p3 p+3 p2 p+ p 而 68% , 95%, 99.7% 等,則為對於 p值會落入 本段結束 上述相對區間的信心水準。
2. 信心水準: (1)「95%的信心水準」是說:如果我們抽樣多次, 每次得到一個信賴區間 那麼多的區間中,約有 95%的區間會涵蓋真正的 p 值。 註: (2) 信心水準 95%所對應的最大誤差為 (3) 使用標準常態分配機率表可得 P(1.96Z1.96) = 0.95。 To be continued 注意
注意:「95%信心水準」與「95% 機率」的差異。 本段結束
3. 範例:某高中對全校學生家長調查「夜間輔導贊成的支持度」, 回收有效問卷共 400 張,其中贊成者 320 張, 求 (1) 在 95% 的信心水準下,正負誤差為多少百分點? (2) 計算 95% 信賴區間。 解: (1) 95%信心水準的最大誤差為 正負誤差為 4 個百分點。 故所求為 [0.76 , 0.84]。 To be continued 注意。
[0.76 , 0.84]。 注意: 所求為 [0.7608 , 0.8392]。 Let’s do an exercise !
馬上練習:某報政府推動的「民生方案」做滿意度調查,馬上練習:某報政府推動的「民生方案」做滿意度調查, 成功訪問了1600位公民,其中有1024位表示不滿意, 求此次調查:(1) 在 95% 的信心水準下,正負誤差為多少百分點? (2) 計算 95% 信賴區間。 Ans:(1) 2.4個百分點(2) [0.616 , 0.664]。 解: (1) 95% 信心水準的最大誤差為 正負誤差為 2.4 個百分點。 故所求為 [0.616 , 0.664]。 #
4. 範例:某報對市長施政滿意度進行調查,結果為 「成功訪問1000 位已成年市民,滿意度為四成三, 在 95% 信心水準下,抽樣誤差為正負 3 個百分點。」 求此次調查的信賴區間。 解: 即 [0.4 , 0.46]。 注意: Let’s do an exercise !
馬上練習:某報對交通滿意度進行調查,結果為:馬上練習:某報對交通滿意度進行調查,結果為: 「成功訪問 1200 位有駕照市民,滿意度為二成三, 在 95% 信心水準下,抽樣誤差為正負 2.4 個百分點。」 求此次調查的信賴區間。 Ans: [ 0.206 , 0.254 ]。 解: 即 [0.206 , 0.254]。 #
5. 範例:某彩卷宣稱中獎率為 36%,若想檢驗此說法是否屬實, 在 95% 信心水準及抽樣誤差為 3.84 個百分點的條件下, 應隨機採多少張樣本? 解: 所求n為 625 張。 Let’s do an exercise !
馬上練習:某公司調查發現:「約有 64% 的人過去一年中 曾買過樂透彩卷,且有 95% 的信心認為 其誤差在正負 3.2% 個百分點之內」。 求樣本中有多少人曾買過樂透彩卷? Ans:576人。 解: 所求 90064% = 576人。 #
6. 範例:抽樣調查學生的購物情形,在 95% 信心水準, 約有 72% ~ 76% 的學生曾有過網路購物, 求此次抽樣的人數是多少? 解:由72% ~ 76%知: 所求 n 為 1924 人。 Let’s do an exercise !
馬上練習:抽樣調查接過詐騙電話的情形,在 95% 信心水準, 約有 70% ~ 76% 的人曾接過詐騙電話, Ans:約 639人。 求樣本中有多少人曾接過詐騙電話? 解:由70% ~ 76%知: 所求 87673% = 639人。 #
7. 範例:某抽樣調查,得一個 95% 信賴區間為 [a , b], (1) 若改用 99.7% 的信心水準,求此調查 99.7% 的信賴區間。 (2) 若想縮小信賴區間為原來的一半,信心水準一樣 95%, 求抽樣人數應為原來的幾倍? 解: Let’s do an exercise !
馬上練習:抽樣 n 個樣本,得 95% 信賴區間為 [0.36 , 0.58]。 若改抽 4n 個樣本, 求其 95% 信賴區間為何? Ans:[0.415 , 0.525]。 解:區間[0.36 , 0.58]知: 即 [0.415 , 0.525]。 #
8. 範例:希望滿足 95% 信心水準下,且誤差不超過 3%, 至少要抽取多少個樣本? 解: Let’s do an exercise ! 即不論p值為何,抽取樣本數 n 大於等於 1112 時,即可滿足要求。
馬上練習:希望滿足 95% 信心水準下,且誤差不超過 2%, 至少要抽取多少個樣本? Ans:2500人。 解: #
9. 範例:某報對交通滿意度進行調查,結果為: 「成功訪問 300 位駕車的市民,表示滿意的有75人, 求此次調查在90%信心水準下的信賴區間。 已知標準常態分配機率 P(1.645Z1.645) = 0.9。 解: 即 [ 0.21 , 0.29 ]。 #
10. 範例:某廠商委託民調機構在甲、乙兩地調查聽過某項產品 的居民佔當地居民之百分比(以下簡稱為「知名度」)。 結果如下:在95%信心水準之下,該產品在甲、乙兩地 的知名度之信賴區間分別為 [0.50 , 0.58]、[0.08 , 0.16]。 下列哪些選項是正確的? (1) 甲地本次的參訪者中,54% 的人聽過該產品。 (2) 此次民調在乙地的參訪人數少於在甲地的參訪人數。 (3) 此次調查結果可解讀為: 甲地全體居民中有一半以上的人聽過該產品的機率大於95%。 (4) 若在乙地以同樣方式進行多次民調, 所得知名度有 95% 的機會落在區間 [ 0.08 , 0.16 ]。 (5) 經密集廣告宣傳後,在乙地再次進行民調,並增加參訪人數 達原人數的四倍,則在 95% 信心水準之下該產品的知名度 之信賴區間寬度會減半 (即 0.04 )。 To be continued 詳解
甲、乙 之 95% 信賴區間分為 [0.50 , 0.58]、[0.08 , 0.16] (1) 甲地本次的參訪者中,54% 的人聽過該產品。 (1) 正確。 解: (2) 此次民調在乙地的參訪人數少於在甲地的參訪人數。 解: (2) 正確。 To be continued (3) (4) (5)
(3) 此次調查結果可解讀為: 甲地全體居民中有一半以上的人聽過該產品的機率大於95%。 解: (3) 錯誤。 (4) 若在乙地以同樣方式進行多次民調, 所得知名度有 95% 的機會落在區間 [ 0.08 , 0.16 ]。 解: (4) 錯誤。 To be continued (5) 注意:
(5) 經密集廣告宣傳後,在乙地再次進行民調,並增加參訪人數 達原人數的四倍,則在 95% 信心水準之下該產品的知名度 之信賴區間寬度會減半 (即 0.04 )。 解: 若 n變為 4 倍, (5) 錯誤。 故所求為 (1) (2)。 Let’s do an exercise !
(4) 如果不區分性別,此次抽樣贊成此議題的比例 介於 0.52 與 0.59之間。 (5) 如果不區分性別,此次抽樣 介於 0.02 與 0.04 之間。 馬上練習:想了解台灣的公民對某議題支持的程度所作的 (99學測) 抽樣調查,依性別區分,所得結果如下表: Ans:(2) (4)。 請問此次抽樣結果可以得到下列哪些推論? (1) 全台灣男性公民贊成此議題的比例大於女性公民贊成此議題的比例。 (2) 在 95% 的信心水準之下,全台灣女性公民贊成此議題之比例的 信賴區間為 [0.48 , 0.56] ( 計算到小數點後第二位,以下四捨五入)。 (3) 此次抽樣的女性公民數少於男性公民數。 To be continued 詳解
(1) 全台灣男性公民贊成此議題的比例大於女性公民贊成此議題的比例。 (1) 錯誤。 解:實際支持度 p無法得知,才使用抽樣調。 (2) 在 95% 的信心水準之下,全台灣女性公民贊成此議題之比例的 信賴區間為 [0.48 , 0.56] ( 計算到小數點後第二位,以下四捨五入)。 解:女性贊成比例的 95% 信賴區間為 (2) 正確。 (3) 此次抽樣的女性公民數少於男性公民數。 解: (3) 錯誤。 To be continued (4) (5)
(4) 如果不區分性別,此次抽樣贊成此議題的 介於 0.52 與 0.59之間。 解: (4) 正確。 (5) 如果不區分性別,此次抽樣 介於 0.02 與 0.04 之間。 解: (5) 錯誤。 故所求為 (2) (4)。 本節結束
Let’s do an exercise ! To be continued 另 解。 # 本段結束
(3) 此次調查結果可解讀為: 甲地全體居民中有一半以上的人聽過該產品的機率大於95%。 解: (3) 錯誤。 (4) 若在乙地以同樣方式進行多次民調, 所得知名度有 95% 的機會落在區間 [ 0.08 , 0.16 ]。 解: (4) 錯誤。 To be continued (5) 注意:
(2) 在 95% 的信心水準之下,全台灣女性公民贊成此議題 之比例的信賴區間為 [0.48 , 0.56] ( 計算到小數點後第二位,以下四捨五入)。 解:女性贊成比例的95%信賴區間為 (2) 正確。 (3) 此次抽樣的女性公民數少於男性公民數。 解: (3) 錯誤。
馬上練習:想了解台灣的公民對某議題支持的程度所作的抽樣馬上練習:想了解台灣的公民對某議題支持的程度所作的抽樣 (99學測) 調查,依性別區分,所得結果如下表: 請問此次抽樣結果可以得到下列哪些推論? Ans:(2) (4)。 (1) 全台灣男性公民贊成此議題的比例大於女性公民贊成此議題的比例。 解:使用抽樣調查議題支持度,就是因為實際的支持度 p無法得知。 (1) 錯誤。
(2) 在 95% 的信心水準之下,全台灣女性公民贊成此議題 之比例的信賴區間為 [0.48 , 0.56] ( 計算到小數點後第二位,以下四捨五入)。 解:女性贊成比例的95%信賴區間為 (2) 正確。 (3) 此次抽樣的女性公民數少於男性公民數。 解: (3) 錯誤。
(4) 如果不區分性別,此次抽樣贊成此議題的 介於 0.52 與 0.59之間。 解: (4) 正確。 (5) 如果不區分性別,此次抽樣 介於 0.02 與 0.04 之間。 解: (5) 錯誤。 故所求為 (2) (4)。
