Download

1 / 21
210 likes | 407 Views
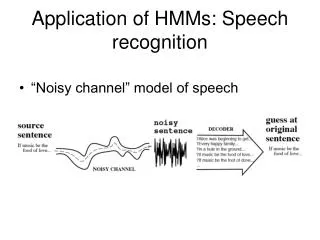
An Examination of Audio-Visual Fused HMMs for Speaker Recognition. David Dean*, Tim Wark* † and Sridha Sridharan* Presented by David Dean. Why audio-visual speaker recognition.

E N D
An Examination of Audio-Visual Fused HMMs for Speaker Recognition David Dean*, Tim Wark*†and Sridha Sridharan* Presented by David Dean
Why audio-visual speaker recognition Bimodal recognition exploits the synergy between acoustic speech and visual speech, particularly under adverse conditions. It is motivated by the need—in many potential applications of speech-based recognition—for robustness to speech variability, high recognition accuracy, and protection against impersonation. (Chibelushi, Deravi and Mason 2002)
A1 A1 V1 V1 A2 A2 V2 V2 A3 A3 V3 V3 A4 A4 V4 V4 Visual Speaker Models Fusion Speaker Decision Acoustic Speaker Models Speaker Decision Speaker Models Early and late fusion • Most early approaches to audio-visual speaker recognition (AVSPR) used either early or late fusion (feature or decision) • Problems • Decision fusion cannot model temporal dependencies • Feature fusion suffers from problems with noise, and has difficulties in modelling the asychronicity of audio-visual speech (Chibelushi et al., 2002) Early Fusion Late Fusion
Middle fusion models can accept two streams of input and the combination is done within the classifier Most middle fusion is performed using coupled HMMs (shown here) Can be difficult to train Dependencies between hidden states are not strong (Brand, 1999) Middle fusion - coupled HMMs
Pan et al. (2004) used probabilistic models to investigate the optimal multi-stream HMM design Maximise mutual information in audio and video They found that linking the observations of one modality to the hidden states of the other was more optimal than linking just the hidden states (i.e. Coupled HMM) The fused HMM designed results in two designs, acoustic, and video biased Middle fusion – fused HMMs Acoustic Biased FHMM
Choosing the dominant modility • The choice of the dominant modality (the one biased towards) should be based upon which individual HMM can more reliably estimate the hidden state sequence for a particular application • Generally audio • Alternatively, both versions can be used concurrently and decision fused (as in Pan et al., 2004) • This research looks at the relative performance of each biased FHMM design individually • If recognition can be performed using only one FHMM, decoding can be done in half the time compared to decision fusion of both FHMMs
Training FHMMs • Both biased FHMM (if needed) are trained independently • Train the dominant (audio for acoustic-biased, video for video-biased) HMM independently upon the training observation sequences for that modality • The best hidden state sequence of the trained HMM is found for each training observation using the Viterbi process • Calculate the coupling parameters between the dominant hidden state sequence and the training observation sequences for the subordinate modality • i.e. estimate the probability of getting certain subordinate observation whilst within a particular dominant hidden state
Decoding FHMMs • The dominant FHMM can be viewed as a special type of HMM that outputs observations in two streams • This does not affect the decoding lattice, and the Viterbi algorithm can be used to decode • Provided that it has access to observations in both streams
Experimental setup HMM Decision Fusion Acoustic HMM Decision Fusion Speaker Decision Acoustic Feature Extraction Visual HMM Visual Feature Extraction Acoustic-Biased FHMM Acoustic Biased FHMM Speaker Decision Video-Biased FHMM Visual Biased FHMM Speaker Decision Lip Location & Tracking
Lip location and tracking • Lip tracking performed as by Dean et al., 2005.
Audio MFCC – 12 + 1 energy, + deltas and accelerations = 43 features Video DCT – 20 coefficients + deltas and accelerations = 60 features Isolated speech from CUAVE (Patterson et al, 2002) 4 sequences for training, 1 for testing (for each of 36 speakers) Each sequence is ‘zero one two … nine’ Testing was also performed on noisy data Speech-babble corrupted audio versions Poorly-tracked lip region-of-interest video features Feature extraction and datasets Well tracked Poorly tracked
Fused HMM design • Both acoustic- and visual-biased FHMMs are examined • Underlying HMMs are speaker-dependent word-models for each digit • MLLR adapted from speaker-independent background word-models • Trained using HTK Toolkit (Young et al, 2002) • Secondary models are based on discrete vector-quantisation codebooks • Codebook is generated from secondary data • The number of occurrences of each discrete VQ value within each state was recorded to arrive at an estimate of . • Codebook size of 100 was found to work best for both modalities
Fused HMM performance is compared to decision fusion of normal HMMs in each state Weight of each stream is based upon audio weight parameter α, which can range from 0 (video only), to 1 (audio only) Two decision fusion configurations were used α = 0.5 Simulated adaptive fusion Best α for each noise level α Decision Fusion × + × 1 - α Decision Fusion
Tier 1 recognition rate Video HMM, video-biased FHMM, and Decision-Fusion are all performing at 100% Audio-biased FHMM performs much better than the HMM only, but not as well as video at low noise levels Speaker recognition: well tracked video
Video is degraded through poor tracking Video FHMM has no real improvement on video HMM Audio FHMM is better than all for most audio-noise levels Even better than simulated adaptive fusion Speaker recognition: poorly tracked video
Video vs. Audio-Biased FHMM • Adding video to audio HMMs to create an acoustic-biased FHMM provides a clear improvement over the HMM alone • However, adding audio to video HMMs provides neglibile improvement • Video HMM provides poor state alignment
Acoustic-biased FHMM vs. Decision Fusion • FHMMs can take advantage of the relationship between modalities on a frame-by-frame basis • Decision fusion can only compare two scores over an entire utterance • FHMM even works better than simulated adaptive fusion for most noise levels • Actual adaptive fusion would require estimation of noise levels • FHMM is running with no knowledge of noise
Conclusion • Acoustic biased FHMM provide a clear improvement on acoustic HMMs • Video biased FHMM do not improve upon video HMMs • Video HMMs are unreliable at estimating state sequences • Acoustic biased FHMM performs better than simulated adaptive decision fusion at most noise levels • With around half the decoding processing cost (more when the cost of real adaptive fusion is included)
As the CUAVE database is quite small for speaker recognition experiments at only 36 subjects, research has continued on the XM2VTS database (Messer et al., 1999), which has 295 subjects Continuous GMM models replaced the VQ secondary models Video DCT VQ couldn’t handle session variability Verification (rather than identification) allows system performance to be examined more easily System is still undergoing development Future/Continuing Work
References M. Brand, “A bayesian computer vision system for modeling human interactions,” in ICVS’99, Gran Canaria, Spain, 1999. C. Chibelushi, F. Deravi, and J. Mason, “A review of speech-based bimodal recognition,” Multimedia, IEEE Transactions on, vol. 4, no. 1, pp. 23–37, 2002. D. Dean, P. Lucey, S. Sridharan, and T. Wark, “Comparing audio and visual information for speech processing,” in ISSPA 2005, Sydney, Australia, 2005, pp. 58–61. K. Messer, J. Matas, J. Kittler, J. Luettin, and G. Maitre, “Xm2vtsdb: The extended m2vts database,” in Audio and Video-based Biometric Person Authentication (AVBPA ’99), Second International Conference on, Washington D.C., 1999, pp. 72–77. H. Pan, S. Levinson, T. Huang, and Z.-P. Liang, “A fused hidden markov model with application to bimodal speech processing,” IEEE Transactions on Signal Processing, vol. 52, no. 3, pp. 573–581, 2004. E. Patterson, S. Gurbuz, Z. Tufekci, and J. Gowdy, “Cuave: a new audio-visual database for multimodal human-computer interface research,” in Acoustics, Speech, and Signal Processing, 2002. Proceedings. (ICASSP ’02). IEEE International Conference on, vol. 2, 2002, pp. 2017–2020. S. Young, G. Evermann, D. Kershaw, G. Moore, J. Odell, D. Ollason, D. Povey, V. Valtchev, and P. Woodland, The HTK Book, 3rd ed. Cambridge, UK: Cambridge University Engineering Department., 2002.