Download

1 / 26
260 likes | 550 Views
Classifying Unknown Proper Noun Phrases Without Context. Joseph Smarr & Christopher D. Manning Symbolic Systems Program Stanford University April 5, 2002. The Problem of Unknown Words. No statistics are generated for unknown words problematic for statistical NLP

E N D
Classifying Unknown Proper Noun Phrases Without Context Joseph Smarr & Christopher D. Manning Symbolic Systems Program Stanford University April 5, 2002
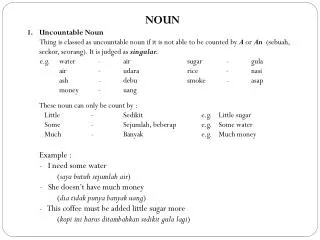
The Problem of Unknown Words • No statistics are generated for unknown words problematic for statistical NLP • Same problem for Proper Noun Phrases • Also need to bracket entire PNP • Particularly acute in domains with large number of terms or new words being constantly generated • Drug names • Company names • Movie titles • Place Names • People’s Names
Proper Noun Phrase Classification • Task: Given a Proper Noun Phrase (one or more words that collectively refer to an entity), assign it a semantic class (e.g. drug name, company name, etc) • Example: MUC ENAMEX test (classifying PNPs in text as organizations, places, and people) • Problem: How do we classify unknown PNPs?
Existing Techniques for PNP Classification • Large, manually constructed lists of names • Includes common words (Inc., Dr., etc.) • Syntactic patterns in surrounding context • … XXXX himself … person • … [profession] of/at/with XXXX organization • Machine learning with word-level features • Capitalization, punctuation, special chars, etc.
Limitations of Existing Techniques • Manually constructed lists and rules • Slow/expensive to create and maintain • Domain-specific solutions • Won’t generate to new categories • Misses valuable source of information • People often classify PNPs by how they look Cotrimoxazole Wethersfield Alien Fury: Countdown to Invasion
What’s in a Name? • Claim: If people can classify unknown PNPs without context, they must be using the composition of the PNP itself • Common accompanying words • Common letters and letter sequences • Number and length of words in PNP • Idea: Build a statistical generative model that captures these features from data
Common Words and Letter Sequences oxa : John Inc field
Generative Model Used for Classification • Probabilistic generative model for each category • Parameters set from • statistics in training data • cross-validation on held-out data (20%) • Standard Bayesian Classification Predicted-Category(pnp) = argmaxc P(c|pnp) = argmaxc P(c)a*P(pnp|c)
Generative Model for Each Category Length n-gram model and word model P(pnp|c) = Pn-gram(word-lengths(pnp)) *Pword ipnp P(wi|word-length(wi)) Word model: mixture of character n-gram model and common word model P(wi|len) = llen*Pn-gram(wi|len)k/len + (1-llen)* Pword(wi|len) N-Gram Models: deleted interpolation P0-gram(symbol|history) = uniform-distribution Pn-gram(s|h) = lC(h)Pempirical(s|h) + (1- lC(h))P(n-1)-gram(s|h)
Walkthrough Example: Alec Baldwin • Length sequence: [0, 0, 0, 4, 7, 0] • Words: “____Alec ”, “lec Baldwin$” Cumulative Log Probability
Walkthrough Example: Baldwin Note: Baldwin appears both in a person’s name and in a place name
Experimental Setup • Five categories of Proper Noun Phrases • Drugs, companies, movies, places, people • Train on 90% of data, test on 10% • 20% of training data held-out for parameter setting (cross validation) • ~5000 examples per category total • Each result presented is average/stdev of 10 separate train/test folds • Three types of tests • pairwise: 1 category vs. 1 category • 1-all: 1 cateory vs. union of all other categories • n-way: every category for itself
Experimental Results: Classification Accuracy pairwise 1-all n-way
Experimental Results:Confusion Matrix Predicted Category drug nyse movie place person drug nyse movie place person Correct Category
Sources of Incorrect Classification • Words that appear in one category drive classification in other categories • e.g. Delaware misclassified as company because of GTE Delaware LP, etc. • Inherent ambiguity • e.g. movies named after people/places/etc: ● Nuremberg ● John Henry ● Love, Inc. ● Prozac Nation
Examples of Misclassified PNPs • Errors from misleading words • Calcium Stanley • Best Foods (24 movies with Best, 2 companies) • Bloodhounds, Inc. • Nebraska (movie: One Standing: Nebraska) • Chris Rock (24 movies with Rock, no other people) • Can you classify these PNPs? • R & C • Randall & Hopkirk • Steeple Aston • Nandanar • Gerdau
Contribution of Model Features • Character n-gram is best single feature • Word model is good, but subsumed by character n-gram • Length n-gram helps character n-gram, but not much
Effect of Increasing N-Gram Length character n-gram model length n-gram model • Classification accuracy of n-gram models alone • Longer n-grams are useful, but only to a point
Effect of Increasing Training Data • Classifier approaches full potential with little training data • Increasing training data even more is unlikely to help much
Compensating for Word-Length Bias • Problem: Character n-gram model places more emphasis on longer words because more terms get multiplied • But are longer words really more important? • Solution: Take (k/length)’th root of each word’s probability • Treat each word like a single base with an ignored exponent • Observation: Performance is best when k>1 • Deviation from theoretical expectation
Generative Models Can Also Generate! • Step 1: Stochastically generate word-length sequence using length n-gram model • Step 2: Generate each word using character n-gram model movie Alien in Oz Dragons: The Ever Harlane El Tombre place Archfield Lee-Newcastleridge Qatad drug Ambenylin Carbosil DM 49 Esidrine Plus Base with Moisturalent nyse Downe Financial Grp PR Host Manage U.S.B. Householding Ltd. Intermedia Inc. person Benedict W. Suthberg Elias Lindbert Atkinson Hugh Grob II
Acquiring Proficiency in New Domains • Challenge: quickly build a high-accuracy PNP classifier for two novel categories • Example: “Cheese or Disease?” • Game show on MTV’s Idiot Savants • Results: 93.5% accuracy within 10 minutes of suggesting categories! • Not possible with previous methods
Conclusions • Reliable regularities in the way names are constructed • Can be used to complement contextual cues (e.g. Bayesian prior) • Not surprising given conscious process of constructing names (e.g. Prozac) • Statistical methods perform well without the need for domain-specific knowledge • Allows for quick generalization to new domains
Bonus: Does Your Name Look Like A Name? • Ron Kaplan • Dan Klein • Miler Lee • Chris Manning / Christopher D. Manning • Bob Moore / Robert C. Moore • Emily Bender • Ivan Sag • Chung-chieh Shan • Stu Shieber / Stuart M. Shieber • Joseph Smarr • Mark Stevenson • Dominic Widdows