A User-Programmable Vertex Engine
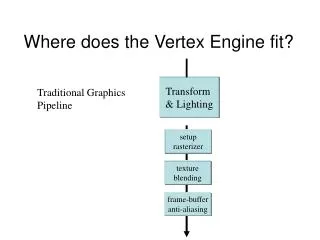
A User-Programmable Vertex Engine. Erik Lindholm Mark Kilgard Henry Moreton NVIDIA Corporation Presented by Han-Wei Shen. Where does the Vertex Engine fit? . Transform & Lighting. Traditional Graphics Pipeline. setup rasterizer. texture blending. frame-buffer anti-aliasing.


A User-Programmable Vertex Engine
E N D
Presentation Transcript
A User-Programmable Vertex Engine • Erik Lindholm • Mark Kilgard • Henry Moreton • NVIDIA Corporation • Presented by Han-Wei Shen
Where does the Vertex Engine fit? Transform & Lighting Traditional Graphics Pipeline setup rasterizer texture blending frame-buffer anti-aliasing
GeForce 3 Vertex Engine Vertex Program Transform & Lighting setup rasterizer texture blending frame-buffer anti-aliasing
API Support • Designed to fit into OpenGL and D3D API’s • Program mode vs. Fixed function mode • Load and bind program • Simple to add to old D3D and OpenGL programs
Programming Model • Enable vertex program • glEnable(GL_VERTEX_PROGRAM_NV); • Create vertex program object • Bind vertex program object • Execute vertex program object
Create Vertex Program • Programs (assembly) are defined inline as • character strings static const GLubyte vpgm[] = “\!!VP1. 0\ DP4 o[HPOS].x, c[0], v[0]; \ DP4 o[HPOS].y, c[1], v[0]; \ DP4 o[HPOS].z, c[2], v[0]; \ DP4 o[HPOS].w, c[3], v[0]; \ MOV o[COL0],v[3]; \ END";
Create Vertex Program (2) • Load and bind vertex programs similar to texture objects glLoadProgramNV(GL_VERTEX_PROGRAM_NV, 7, strelen(programString), programString); …. glBindProgramNV(GL_VERTEX_PROGRAM_NV, 7);
Invoke Vertex Program • The vertex program is initiated when a vertex is given, i.e., when • glBegin(…) • glVertex3f(x,y,z) • … • glEnd()
Let’s look at the sample program static const GLubyte vpgm[] = “\!!VP1. 0\ DP4 o[HPOS].x, c[0], v[0]; \ DP4 o[HPOS].y, c[1], v[0]; \ DP4 o[HPOS].z, c[2], v[0]; \ DP4 o[HPOS].w, c[3], v[0]; \ MOV o[COL0],v[3]; \ END"; O[HPOS] = M(c0,c1,c2,c3) * v - HPOS? O[COL0] = v[3] - COL0? Calculate the clip space point position and Assign the vertex with v[3] as its diffuse color
Programming Model V[0] … V[15] VertexSource Program Constants c[0] … c[96] 16x4 registers O[HPOS] O[COL0] O[COL1] O[FOGP] O[PSIZ] O[TEX0] … O[TEX7] Vertex Program 96x4 registers R0 … R11 Temporary Registers 128 instructions 12x4 registers Vertex Output 15x4 registers All quad floats
Input Vertex Attributes • V[0] – V[15] • Aliased (tracked) with conventional per-vertex attributes (Table 3) • Use glVertexAttribNV() to explicitly assig values • Can also specify a scalar value to the vertex attribute array - glVertexAttributesNV() • Can change values inside or outside glBegin()/glEnd() pair
Program Constants • Can only change values outside glBegin()/glEnd() pair • No automatic aliasing • Can be used to track OpenGl matrices (modelview, projection, texture, etc.) • Example: • glTrackMatrix(GL_VERTEX_PROGRAM_NV, 0, GL_MODELVIEW_PROJECTION_NV, GL_IDENTIGY_NV) • - track 4 contiguous program constants starting with c[0]
Program Constants (cont’d) • DP4 o[HPOS].x, c[0], v[OPOS] • DP4 o[HPOS].y, c[1], v[OPOS] • DP4 o[HPOS].z, c[2], v[OPOS] • DP4 o[HPOS].w, c[3], v[OPOS] • What does it do?
Program Constants (cont’d) • glTrackMatrixNV(GL_VERTEX_PROGRAM_NV, 4, GL_MODEL_VIEW, GL_INVERSE_TRANPOSE_NV) • DP3 R0.x, C[4], V[NRML] • DP3 R0.y, C[5[, V[NRML] • DP3 R0.z, C[6], V[NRML] • What doe it do?
Hardware Block Diagram Vertex In Vertex Attribute Buffer (VAB) Vector FP Core Vertex Out
Vertex Attribute Buffer (VAB) 128 ( 32 x 4 ) … VAB dirty bits 128 IB 0 1 14 15 ….
Data Path X Y Z W X Y Z W X Y Z W Swizzle Swizzle Swizzle Negate Negate Negate FPU Core Write Mask X Y Z W
Instruction Set: The ops • 17 instructions total • MOV, MUL, ADD, MAD, DST • DP3, DP4 • MIN, MAX, SLT, SGE • RCP, RSQ, LOG, EXP, LIT • ARL
Instruction Set: The Core Features • Immediate access to sources • Swizzle/negate on all sources • Write mask on all destinations • DP3,DP4 most common graphics ops • Cross product is MUL+MAD with swizzling • LIT instruction implements phonglighting
Dot Product Instruction • DP3 R0.x, R1, R2 • R0.x = R1.x * R2.x + R1.y * R1.y + R1.z * R2.z • DP4 R0.x, R1, R2 • 4-component dot product
MUL instruction • MUL R1, R0, R2 (component-wise mult.) • R1.x = R0.x * R2.x • R1.y = R0.y * R2.y • R1.z = R0.z * R2.z • R1.w = R0.w * R2.w
MAD instruction • MAD R1, R2, R3, R4 • R1 = R2 * R3 + R4 • *: component wise multiplication • Example: • MAD R1, R0.yzxw, R2.zxyw, -R1 • What does it do?
Cross Product Coding Example # Cross product R2 = R0 x R1 MUL R2, R0.zxyw, R1.yzxw; MAD R2, R0.yzxw, R1.zxyw, -R2;
Lighting instruction • LIT R1, R0 (phong light model) • Input: R0 = (diffuse, specular, ??, shiness) • Output R1 = (1, diffuse, specular^shininess, 1) • Usually followed by • DP3 o[COL0], C[21], R1 (assuming using c[21]) • where C[xx] = (ka, kd, ks, ??)
Previous Work: Geometry Engine • High bandwidth + lots of Flops • Low clock rate • No architectural continuity • VERY hard to program • Some high-level language support (maybe) • A compromise solution (vtx,prim,pix,…)
Alternative: The CPU • Low bandwidth + reasonable Flops • High clock rate • Excellent architectural continuity • VERY hard to use efficiently • Excellent high-level language support • Flexible, but often too slow
New Design: The Vertex Engine • Simple hardware for a commodity GPU • Allows user to manipulate vertex transform • Simple to use programming model • Superset of fixed function mode
Why Vertex Processing? • Very parallel • Use single vertex programming model • Hardware can batch or interleave • KISS
Why Not Primitive Processing? • Face culling and clipping break parallelism • Complicates memory accesses • Inefficient (control takes time) • Let hardware designers optimize
Programming Model: Vertex I/O • Streaming vertex architecture • Source data converted to floats • Source data loaded • Run program • Destination data drained • Destination data re-formatted for hw
Hardware Implementation • Vector SIMD Unit + Special Function Unit • Multithreaded and pipelined to hide latency • Any one instruction/cycle • All instructions equal latency • Free swizzling/negate/write mask support
Conclusion • Very simple, efficient implementation • Allows vertex programming continuity • Stanford Imagine Architecture • A work in progress, lots more to come… • We welcome your feedback