Access methods for time-evolving data
Presenters : Virag Kothari ,Vandana Ayyalasomayajula Date: 04/21/2010. Access methods for time-evolving data. Outline. Introduction to temporal databases Goal of the paper Access method costs Queries Index pagination & Data Clustering


Access methods for time-evolving data
E N D
Presentation Transcript
Presenters : Virag Kothari ,Vandana Ayyalasomayajula Date: 04/21/2010 Access methods for time-evolving data
Outline • Introduction to temporal databases • Goal of the paper • Access method costs • Queries • Index pagination & Data Clustering • Efficient method design for transaction data • References
Introduction • Based on time dimension • Transaction time database • Valid time database • Bitemporal database
Goal • Attempt to identify the implications for access method design from support of each time dimension • In this presentation, transaction time databases are considered.
Access Method Costs • Performance of an access method depends on • storage space to physically store the data records and the structures of the access method • update processing time (the time to update the method’s data structures as a result of a change) • the query time for each of the basic queries ( discussed in the next slide !)
Queries • Given a contiguous interval T, find all objects alive during this interval. • Given a key range and a contiguous time interval T, find the objects with keys in the given range that are alive during interval T. • Given a key range, find the history of the objects in this range.
Queries - Special cases ! • “transaction pure-timeslice” • A special case of class (I) occurs when interval T is reduced to a single transaction time instant t. • “transaction range-timeslice” • representative case of class (II) where the time interval is reduced to a single transaction time instant. • “transaction pure-key query” • representative case of class (III), key range is reduced to a single key
Cost parameters • In the case of transaction , Bitemporal databases, • n - > summation of insertions, deletions, and modification updates. • For Valid time databases, • L - > the number of interval objects currently stored in the method, i.e., the size of the collection • a -> to denote the answer size of a query in general.
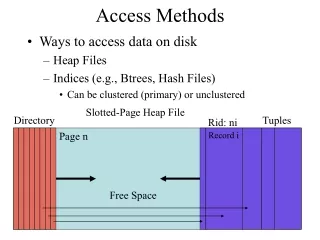
Index pagination & Data Clustering • Cost depends on IO cost ! • Performance of an index depends on how well it is ‘Paginated’ • Example: B+ trees. • Data Clustering improves performance by storing logically near data , physically close on the disk. • pure-timeslice query takes O(logBn + a/B ) page accesses. This method is more I/O efficient than another method that solves the same query in O(logBn + a) page accesses.
Efficient Method Design for Transaction • Transaction Pure-Timeslice Query • ‘copy’ approach • Stores a copy of the transaction database state s(t) (timeslice) for each transaction time that at least one change occurred • Copies are indexed by time t. • ‘log’ approach • Stores only the changes that occur in the database timestamped by the time instant on which they occurred. • Copies indexed by time t.
Transaction Pure Key • “copy” and “log” solutions could be used for the pure-key query. But they are both very inefficient !!. • A better solution is to store the history of each key separately, i.e., cluster data by key only. • Access to a key’s (transaction time) history can be implemented by a hashing function or B tree. • The list of versions of each key can be further organized in a separate array indexed by transaction time to answer a pure-key query with time predicate .
Costs – Transaction pure key • Cost to index into hash table or B tree + cost of searching in the array. • Array length can be n/B , so cost would O( log B n) .
Transaction Range-Timeslice • To answer a range query efficiently, it is best to cluster by transaction time and key within pages. • Very similar to spatial indexing concept. • Two dimensions , time & key need to be considered. • Data bounding technique • Another possibility data mapping, maps a record to three (or more) coordinates –transaction start_time, end-_time, and key(s)—and then uses a multiattribute point index.
References • Betty Salzberg, Vassilis J. Tsotras: Comparison of Access Methods forTime-Evolving Data. ACM Comput. Surv. (CSUR) 31(2):158-221 (1999)