
DNA の二重らせん構造
DNA の二重らせん構造. 相補鎖. CDS 1..15 CDS complement(7..27) GenBank ファイルには、 3’-5’ 側の配列は載せられていない. 1 2 12345678901234567890123456789 5’- atgctactaacgtag tcgatgtagcatgt-3’ 3’-tacgat gattgcatcagctacatcgta ca-5’. 相補鎖配列を得る方法. 1 2
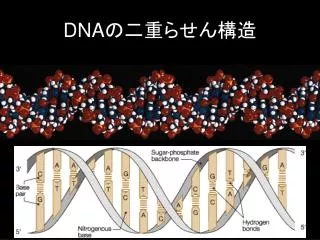

DNA の二重らせん構造
E N D
Presentation Transcript
相補鎖 • CDS 1..15 • CDS complement(7..27) • GenBankファイルには、3’-5’側の配列は載せられていない 1 2 12345678901234567890123456789 5’-atgctactaacgtagtcgatgtagcatgt-3’ 3’-tacgatgattgcatcagctacatcgtaca-5’
相補鎖配列を得る方法 1 2 12345678901234567890123456789 5’-atgctactaacgtagtcgatgtagcatgt-3’ CDS complement(7..27) 1. 配列を抽出 ctaacgtagtcgatgtagcat 2. A→T、C→G、G→C、T→Aの変換を行う gattgcatcagctacatcgta 3. 逆順にする atgctacatcgactacgttag
大腸菌ファイル /pub/sfc/dnadb/genomes/bacteria/Ecoli/ecoli.gbk
CDSの切り出し $i番目のCDS配列 塩基配列全体 $i番目のCDSの開始位置 $cds_seq[$i] = substr($seq, $cds_start_set[$i] - 1, $cds_end_set[$i] - $cds_start_set[$i] + 1); CDSの長さ
塩基配列のみのファイルの作成 sub save_sequence { my($filename, $fh) = @_; my($seq_frag); local(*SEQFILE); open(SEQFILE, "> $filename"); while(<$fh>){ if($_ =~ /^\/\//){ last; } else { $seq_frag = $_; $seq_frag =~ s/[^a-z]//g; print SEQFILE $seq_frag; } } close SEQFILE; } 呼び出し:save_sequence(“seq.tmp”, *FILE)
complementを処理するには… • CDSがcomplementか否かを記録する変数@complementを用意 • CDSの開始位置、終了位置を取得 • 1つ1つの@complementを見ていって、”1”だったら、配列を相補的にして逆にする