Optimal Strategies for Managing Invasive Species Using POMDP Framework
This document discusses the application of partially observable Markov decision processes (POMDPs) in the management of invasive species, specifically Branched Broomrape (Orobancheramosa). It highlights the challenges of observing underlying states and the importance of balancing actions that gather information with those that improve management outcomes. A detailed formulation as a POMDP explores states, actions, observations, and reward structures, offering a comparison between optimal policies for management decisions on individual farms while addressing practical complexities and potential strategies to minimize POMDP usage.


Optimal Strategies for Managing Invasive Species Using POMDP Framework
E N D
Presentation Transcript
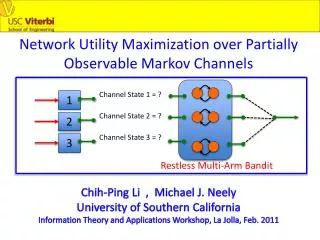
Partially-Observable Markov Decision Processes Tom Dietterich MCAI 2013
Markov Decision Processas a Decision Diagram Note: We observe before we choose All states, actions, and rewards are observed MCAI 2013
What If We Can’t Directly Observe the State? Note: We observe before we choose Only the observations are observed, not the underlying states MCAI 2013
POMDPs are Hard to Solve • Tradeoff between taking actions to gain information and taking actions to change the world • Some actions can do both MCAI 2013
Optimal Management of Difficult-to-Observe Invasive Species [Regan et al., 2011] • Branched Broomrape (Orobancheramosa) • Annual parasitic plant • Attaches to root system of host plant • Results in 75-90% reduction in host biomass • Each plant makes ~50,000 seeds • Seeds are viable for 12 years MCAI 2013
Quarantine Area in S. Australia • 375 farms; 70km x 70km area Google maps MCAI 2013
Formulation as a POMDP:Single Farm • States: • {Empty, Seeds, Plants & Seeds} • Actions: • {Nothing, Host Denial, Fumigation} • Observations: • {Absent, Present} • Detection probability • Rewards: • Cost(Nothing) Cost(Host Denial) Cost(Fumigation) • Objective: • 20-year discounted reward (discount = 0.96) State Diagram MCAI 2013
Optimal MDP Policy • If plant is detected, Fumigate; Else Do Nothing • Assumes perfect detection www.grdc.com.au MCAI 2013
Optimal POMDP Policy for • Same as the Optimal MDP Policy Action OBSERVATION ABSENT Decision State Fumigate ABSENT Nothing 1 0 After State PRESENT PRESENT MCAI 2013
Optimal Policy for ABS ... Nothing Fumigate Deny Deny ABS ABS ABS 0 1 2 16 PRESENT PRESENT PRESENT PRESENT • Deny Host for 15 years before switching to Nothing • For Deny Host for 17 years before switching to Nothing MCAI 2013
Probability of Eradication MCAI 2013
Discussion • POMDP is exactly solvable because the state space is very small • Real problem is more complex • Each farm can have many fields, each with its own hidden state • There 375 farms in the quarantine area • states if we treat each farm as a single unit • Exact solution of large POMDPs is beyond the state of the art • Notice that there is no tradeoff between acting to gather information and acting to change the world. None of the actions gain information MCAI 2013
Ways to Avoid a POMDP (1) • State Estimation and State Tracking • In many problems, we have (or can acquire) enough sensors so that we can estimate the state quite well • has low uncertainty • Let be the most likely hidden state • In such problems, we can pretend that we have an MDP and we can directly observe • We do not need to take actions to gain information, so we do not face this difficult tradeoff MCAI 2013
Ways to Avoid a POMDP (2) • Pure Information-Gathering POMDPs • Consider a medical diagnosis case for a specific disease where there are tests, that can be performed. Our goal is to decide whether the patient has the disease by choosing tests to perform • Each test has two possible outcomes and • Each test has a cost • Given any subset of the outcomes, we can compute the probability that the patient has the disease • There is a “false positive” cost for incorrectly saying that and a “false negative” cost, for saying that MCAI 2013
Formulation as an MDP • States: • starting state is • Actions • actions are the medical tests • action says “the patient does not have the disease” and terminates with cost 0 if correct and cost if incorrect • action says “the patient has the disease” and terminates with cost 0 if correct and cost if incorrect • State Transitions • When we perform test in state , the resulting state sets the th entry in the state to according to • When we perform a “declare” action, the problem transitions to a terminal state with probability 1 • If there aren’t too many tests and we know , we can enumerate the states and solve this via standard MDP methods MCAI 2013
Belief States • In general, we can think of a POMDP as being an MDP over a Belief State • In the medical diagnosis cases, the belief states have the form (0,1,?,?,0,?) • In the Broomrape case, the belief state is a probability distribution over the 3 states: weeds + seeds empty seeds MCAI 2013
Belief State Reasoning • Each observation updates the belief state • Example: observing the presence of weeds means weeds are present and seeds might also be present observe present weeds + seeds weeds + seeds empty empty seeds seeds MCAI 2013
Taking Actions • Each action updates the belief state • Example: fumigate fumigate weeds + seeds weeds + seeds empty empty seeds seeds MCAI 2013
Belief MDP • State space: all reachable belief states • Action space: same actions as the POMDP • Reward function: expected rewards derived from the underlying states • Transition function: moves in belief space • Problem: Belief space is continuous and there can be an immense number of reachable states MCAI 2013
Monte Carlo Policy Evaluation • Key Insight: It is just as easy to evaluate a policy via Monte Carlo trials in a POMDP as it is an in MDP! • Approach: • Define a space of policies • Evaluate them by Monte Carlo trials • Pick the best one MCAI 2013
Finite State Machine Policies • In many POMDPs (and MDPs), a policy can be represented as a finite state machine • We can design a set of FSM policies and then evaluate them • There are algorithms for incrementally improving FSM policies ABS ... Nothing Fumigate Deny Deny ABS ABS ABS 0 1 2 16 PRESENT PRESENT PRESENT PRESENT MCAI 2013
Summary • Many problems in AI can be formulated as POMDPs • Formulating a problem as a POMDP doesn’t help much, because they are so hard to solve (PSPACE-hard for finite horizon; undecidable for infinite horizon) • Can we do state estimation and pretend ? • Are we performing pure observation actions? • Can the policy be divided into a pure observation phase and a pure action phase? • If so, we can use MDP methods instead • Unfortunately, many problems in ecosystem management are “essential” POMDPs that mix information gathering and world-changing actions • Monte Carlo methods (based on policy space search) are one of the most practical ways of finding good POMDP solutions MCAI 2013