Download

1 / 28
280 likes | 445 Views
Is ASCII the only way?. For computers to do anything (besides sit on a desk and collect dust) they need two things: 1. PROGRAMS 2. DATA. A program is a set of instructions that specify each step the computer should take to solve a problem or perform a task.

E N D
For computers to do anything (besides sit on a desk and collect dust) they need two things: 1. PROGRAMS 2. DATA A program is a set of instructions that specify each step the computer should take to solve a problem or perform a task. Data is information which is stored and processed. Data may be numeric or alphabetical ("string" in computerese) or a combination of those (alphanumeric - more computerese).
How can the computer store data? It has no eyes and hasn't been to school to learn the meaning of "4", or to understand that the symbols 4, four, and IV, represent the same idea. Can computers think, anyway?(Well, that's a discussion for another day. Possibly a research topic for someone's final paper?) (First come, first served.)) Since computers can only work with 2 states, on/off or 1/0, all data must be transmitted and stored as some combination of the 2 states. Electronically, we are talking about on/off. (That we will leave for the computer engineer majors.) In computer science, we abstract a bit, we use the 1/0 representation.
Lets focus on fixed length bit strings. “Bit”is more computerese, formed from parts of the phrase "binary digit" referring to 1 and 0. In a binary number system, only 2 digits are needed, 1and 0, unlike our decimal system which needs 10 (0,1,2....9).
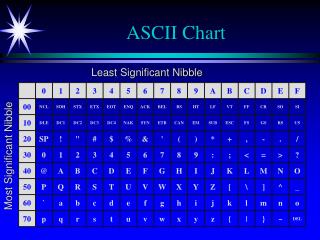
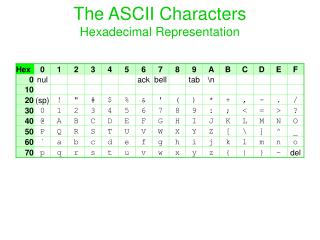
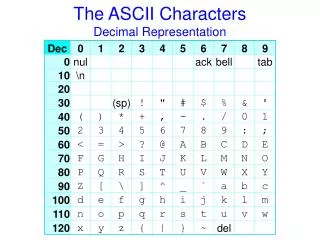
Formany years, the computer world agreed to use the American Standard Code for Information Interchange referred to as ASCII (pronounced "as ski"). Part of the code is below:
ASCII (partial table) Char 1286432168421 Dec A 0 1 0 0 0 0 0 1 65 B 0 1 0 0 0 0 1 0 66 C 0 1 0 0 0 0 1 1 67 D 0 1 0 0 0 1 0 0 68 E 0 1 0 0 0 1 0 1 69 F 0 1 0 0 0 1 1 0 70 G 0 1 0 0 0 1 1 1 71 H 0 1 0 0 1 0 0 0 72 Each string of 8 bits is called a byte. (Remember, computers don't bite!)
Question: What is the maximum number of codes that can be created using 8 bits, starting from 00000000 to 11111111 ? That is, how many characters can be represented by 1 byte? (That sounds like mathematics, Oh no! Oh yes, there is a considerable amount of discrete mathematics - that's the fun type - in computer science.)
Note: today, another coding system, entitled Unicode is used to store and transmit data. ASCII is a subset of Unicode and therefore, is still used. Unicode might be another research topic, but it is a narrow topic, which might take some creativity to make interesting and grade-worthy.
A fixed length code, such as ASCII, wastes time and space. For example, consider the following sentence: THE QUICK GREY FOX JUMPED OVER THE LAZY COWS We will use all capital letters and no punctuation for simplicity. Why is this a great sentence for studying codes? How many characters are in this sentence?
THE QUICK GREY FOX JUMPED OVER THE LAZY BROWN COWS 01010100 01001000 01000101 00100000 01010001 01010101 01001001 01000011 01001011 00100000 01000111 01010010 01000101 01011001 00100000 01000110 01001111 01011000 00100000 01001010 01010101 01001101 01010000 01000101 01000100 00100000 01001111 01010110 01000101 01010010 00100000 01010100 01001000 01000101 00100000 01001100 01000001 01011010 01011001 00100000 01000010 01010010 01001111 01010111 01001110 00100000 01000011 01001111 01010111 01010011
The code for our sentence takes 50 bytes, or 400 bits. We know where each new character starts by counting every 8 bits, since each character takes the same amount of space. This method is wasteful, and can be significantly compressed. One approach, commonly used for text, is to reduce the number of bits for the most frequent characters. In english, E is the most common letter, so it is reasonable to use the fewest number of bits for E, and to use a large number of bits for a letter seldom used, such as Z. This produces a variable length code that takes less space.
Data compression is important in many situations such as sending data over the Internet, where transmission can take a long time, especially in a dial-up connection. In a sentence such as: SUSIE SAYS IT IS EASY; E is not the most common character. In the Java language, the semi-colon (;) appears most often. Therefore, to achieve optimal compression for each message we need to create a new code. This was the method used by David Huffman in 1952. Depending on the message, 20% to 90% savings is achieved.
Here is Huffman's algorithm: 1. Make a table showing the frequency of each letter in the message Ex (for the Susie sentence) A-2 E-2 I-3 S-6 T-1 U-1 Y-2 space-4 linefeed-1
2. Set the table by frequency in descending order S-6 space-4 I-3 A-2 E-2 Y-2 T-1 U-1 linefeed-1
3.Give the smallest code to the character with the highest frequency. Starting with 2 bits, increase the number of bits as needed. One method to encode the Susie sentence is : S-10 space-00 I-110 A-010 E-1111 Y-1110 T-0110 U-01111 linefeed-01110
Encode the Susie sentence using ASCII and encode the message again using the above Huffman code. What is the % savings in the number of bits?
Solution ASCII - (8 bits)*(21 characters)=168 bits Huffman - 100111110110111100100101110100011001100011010001111010101110 = 60 bits Difference in bits = 168-60=108 % savings = (108/168)*100 = 64%
Question: How do we know where one character ends and another character begins? To decode a message, we use a device called a Huffman Tree. Trees are data structures that are used in many ways in computer science. Trees are usually drawn upside down
Here is the Huffman Tree needed to decode the Susie message 22 9 13 4(sp) 5 6(S) 7 2(A) 3 3(I) 4 1(T) 2 2(Y) 2(E) 1(lf) 1(U)
The characters of the message appear in the terminal (or leaf) nodes of the tree. The number outside the terminal node is the frequency of each character. (The number outside the non-terminal node will be explained when we learn to create a Huffman tree) In the coded message, a '0' means go left, and a '1' means go right. Use the tree to decode the Susie message. Each time a leaf is reached, record the character. Return to the root (top!) of the tree and begin following the next path.
Since a Huffman code is different for each message, the tree for that code must be transmitted with the message. (Programmers create a tree with the programming language they use, but first they must create it with paper and pencil. That is how we will do it.) 1. Make a node for each character, and list them in increasing order lf(1) U(1) T(1) Y(2) E(2) A(2) I(3) sp(4) S(6)
Here is the algorithm to create a Huffman Tree: 1. Make a node for each character, and list them in increasing order Ex: lf(1) U(1) T(1) Y(2) E(2) A(2) I(3) sp(4) S(6) 2. Remove the 2 lowest frequency nodes and create a tree with them, labeling the root node with the sum of those frequencies 2 (lf)1 U(1)
3. Re-insert the new tree in the list of nodes in the postion that keeps the list ordered. (T)1 2 (Y)2 (E)2 (A)2 (I)3 (sp)4 (S)6 (lf)1 U(1) 4. Repeat these steps until there is one large tree.
2 3 (T)12 (lf)1 U(1) 22 (Y)2 (E)2 (A)2 3 (I)3 (sp)4 (S)6 (T)12 (lf)1 U(1) Continue until you have the tree we saw earlier.
Once a Huffman tree is complete, it can be searched for each character: When “00” is read, go left then left again - ‘space’ is found. When “10” is read, go right then left - ‘S’ is found. When “010” is read, go left, then right, then left - ‘A’ is found. etc.
A Huffman tree is made for each message, but the tree is not necessarily unique. Some variations in the tree are possible for a given coding scheme. However, there is an important restriction on the coding scheme, because a Huffman code is a prefix code.
Suppose ‘01’ was used for ‘S’ and ‘11’is used for ‘space’ instead of what we used. What problem would arise in attempting to decode the ‘Susie’ message? Since ‘01’ is the beginning of the code for ‘A’ as well as the code for ’T’, the system would not work.
Assignment: Write a 4 or 5 word sentence on a sheet of paper. Code the sentence with ASCII on another sheet of paper. Code the sentence with a Hoffman code on a third paper. Include the Hoffman tree on the third paper.