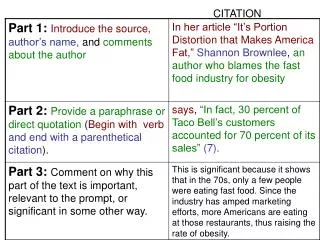
Download

1 / 64
640 likes | 659 Views
Understand the significance of digital preservation and citation for managing information objects effectively. Explore types of data loss and learn about safeguarding digital objects while ensuring usability and faithfulness to creators' intentions. Discover the importance of persistent references, object surrogates, and structured citation metadata. Dive into protocols, like Dublin Core, for structured data about primary stuff. Enhance information retrieval with surrogates and citations, ensuring efficient handling of diverse objects through uniform references.

E N D
Supporting Persistent Citation Webcast 4pm 11 December 2006 John Kunze, California Digital Library
California Digital Library • A university library with no books, students, or faculty • Central services for 10 campuses • 208,000 students • 121,000 faculty and staff • 100+ libraries and museums • Content hosting: electronic texts, web-based material, finding aids, scanned book content (OCA, Google), datasets
What’s digital preservation? Storing digital objects while retaining a balance of usability and faithfulness (truthiness) to their creators’ original intentions
What’s digital preservation? Storing digital objects while retaining a balance of usability and faithfulness (truthiness) to their creators’ original intentions Truthiness defined by the Designated Community
Kinds of loss • Hard loss - some or all data bits are missing • Soft loss - we think we have all the bits … • Syntactic loss - bits are there, but format cannot be rendered by software • Semantic loss - data renderable without apparent error, but not understandably • Legal loss - data format or data itself is legally encumbered
Digital preservation in two parts • Object: safeguarding its… • Viability (intact bit streams) • Renderability (by machines) • Understandability (by humans) • Citation: no preservation if we don’t know… • What the object is, i.e., a summary description • What flavor of support (assuming non-accidental preservation) is intended by the provider • How to get it, or its persistent actionable identifier
Our Stuff vs Their Stuff • While safeguarding objects is primary, focus now on tools for persistent reference: citations and identifiers • Persistent reference can be split into • the Our Stuff Problem • the Their Stuff Problem • No sense assigning persistent ids to Their Stuff • While Their Stuff is hugely important to Our users, we don’t control it and we cannot vouch for it • Where affordable, we might track Their Stuff (eg, PURLs) • New focus: persistent reference to Our Stuff
Citations as object surrogates Surrogates provide a time-honored way of avoiding the inconvenience of directly handling objects. • Surrogates are usually much smaller (eg, a catalog card) • Unlike the objects, surrogates may be unencumbered and in a language that you understand • Surrogates are much more uniform (for easier processing) than objects • Every system has surrogates, even if dynamically generated • A surrogate is essentially an object citation Reminder: What is a citation for? • A citation is a surrogate-based tool to help us find, use, and manage information objects, resources, or stuff.
Citation metadata Metadata definition 1: “data about data” • Too broad and too narrow, e.g., a book review? a catalog record for a statue? Metadata definition 2: “structured data about stuff” • “stuff” avoids having to say a statue is data • “structured” data assists automation by making it easy to recognize and record individual data elements • The more uniform, the more leverage for interoperation • Automation + Interoperation Protocol Citation metadata is structured data that is usually, but not always, secondary to, smaller than, and about stuff that is primary
Why citations? The identifier isn’t enough • Higher confidence through limited redundancy The object is too much • Often inconvenient to handle objects directly • Need easy handling of diverse objects through uniform surrogates
Activating citations with protocols: simplicity / functionality pendulum In the beginning, … application protocols were layered on TCP/IP • Simplicity: email set the standard (RFC 822 headers) • HTTP, NNTP, gopher, etc. followed its lead; OSI protocols withered Then: second system syndrome (expanding functionality): • Z39.50, CORBA, SOAP, and others Regret period (contracting complexity): • OpenSearch, RSS, and in DL world, SRW/SRU, OAI How are we doing? • Tues 13 June 2006: “low barrier” OAI failures attributed to errors in XML coding, schemas; poor, inconsistent, and expensive metadata; with surrogates too non-uniform to be of much use [CL & CL] Perhaps things are still too complicated?
Simple citation metadata isn’t Dublin Core metadata tried to be simple • Goal: “specification shouldn’t register on a bathroom scale” Goal achieved, but spec. was under-specified • No definition of record • No concept of minimal object description • No layout rules for author names and dates • No practical extension framework • No meta-metadata, eg, provenance, commitment statements
15 Dublin Core elements Thought to apply to almost any object – discovery as goal Despite DCMI efforts to correct known problems, the simplest protocol with the simplest metadata – OAI – reports an overall 36% failure rate, 77% due to metadata/encoding and protocol errors.
“Simple” Dublin Core metadata <?xml version="1.0"?> <!DOCTYPE rdf:RDF PUBLIC "-//DUBLIN CORE//DCMES DTD 2002/07/31//EN" "http://dublincore.org/documents/2002/07/31/dcmes-xml/dcmes-xml-dtd.dtd"> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"> <rdf:Description rdf:about=”http://www.nap.edu/books/0309064996/html/”> <dc:title>The Digital Dilemma</dc:title> <dc:creator>National Research Council</dc:creator> <dc:date>2000-06-22</dc:date> </rdf:Description> </rdf:RDF>
Same record with Dublin “Kernel” Here’s the same information, still machine-readable, as an Electronic Resource Citation (ERC) with Kernel metadata: erc: who: National Research Council what: The Digital Dilemma when: 2000 where: http://books.nap.edu/html/digital%5Fdilemma Motivators for the ERC • Meet the need for a simple and manipulable record • Direct human contact with metadata is inevitable • Record should place minimal strain on people • Succinct, transparent, trivially parseable (2 lines of Perl code)
Making it minimal: Kernel/ERC Electronic Resource Citation (ERC) − back to basics • An ERC record is a sequence of elements in email header format: label, colon, value • Long values are continued on indented lines • A blank line ends a record Based on cross-domain kernel distilled from Dublin Core • who − a responsible person or party • what − a name or other human-oriented identifier • when − a date important in the object’s lifecycle • where − a location or a machine-oriented identifier
The ERC notion of “story” The same record as before, in its most compact form: erc: National Research Council | The Digital Dilemma | 2000 | http://books.nap.edu/html/digital%5Fdilemma Either ERC form starts by telling the story of an expression of the resource, applying who-what-when-where questions to it. • All 4 kernel elements are required • Absent values must be explained; 7 flavors of “empty” • Element ordering is rigid in compact form (positional semantics) • Arbitrary additional elements may occur after the 4 elements Other segments in the ERC may introduce other stories, such as, • erc-about, erc-support, erc-from
A 2-story ERC record erc: who: Tomlinson, Richard what: Adjustable knock down chair when: (:unkn) where: http://espacenet.com/dips/bnsviewer%{ ? CY=ec & LG=en & DB=EPD & PN=US5498054 & ID=US+++5498054A1+I+ %} erc-support: who: European Patent Office what: (:permuc) Permanent, Unchanging Content # Note to ops staff: verify date. when: 20010621 where: http://ark.espacenet.com/ark:/23003/US5498054
ERC special values Controlled element values have the form, “(:ccode)” • e.g., missing: (:unkn) Anonymous, (:unas) Unassigned • e.g., general: (:791) Bee Stings Sort-friendly values keyed off of initial comma who:, van Gogh, Vincent who:, Howell, III, PhD, 1922-1987, Thurston who:, Mao Tse Tung what:, Health and Human Services, United States Government Department of, The, and their equivalents in natural word order: Vincent van Gogh Thurston Howell, III, PhD, 1922-1987 Mao Tse Tung The United States Government Department of Health and Human Services
ERC dates and expansion blocks ERC value with an “expansion” block − “%{“ and “%}” where: http://foo.bar.org/node%{ ?db= foo &start = 1 &end = 5 &buf = 2 &query = foo + bar + zaf %} is equivalent to the correct and intact URL, where: http://foo.bar.org/node?db=foo&start=1&end=5&buf=2&query=foo+bar+zaf Dates are in TEMPER format 1996-2000(range of four years) 1952, 1957, 1969(list of three years) 1952, 1958-1967, 1985(mixed list of dates & ranges) 20001229-20001231 (range of three days)
Kernel/ERC summary ERC is a cheap, general-purpose citation container • It’s kernel metadata is designed to be a low-barrier way to support orderly management of collections • Might help resource discovery and description too • Succinct, trivial to parse, extensible yet predictable in the kernel elements See http://dublincore.org/groups/kernel/ for more How to activate an ERC? One way is with THUMP.
Searching and retrieving citations with THUMP THUMP: The HTTP URL Mapping Protocol • A set of simple URL-based conventions for retrieving information and conducting searches • Can be used for focused retrievals or for broad database searches • Based on commands put in the query string after ‘?’ http://example.foo.com/?in(books)find(war and peace)show(full)
THUMP requests The HTTP URL Mapping Protocol (THUMP) • A protocol based on HTTP and URLs • A request is passed to a server with HTTP GET (or POST) Shortest request is a URL ending in `?', as in http://example.foo.com/object321? Which is shorthand for the common request: http://example.foo.com/object321?show(brief)as(anvl/erc) Naked ‘?’ and ‘??’ designed to support the known-item query convention arising in the ARK persistent id scheme
THUMP responses Responses consist of HTTP response headers, one record set header, and one or more ERC records 1 C: [opens session] C: GET http://ark.cdlib.org/ark:/13030/ft167nb0vq? HTTP/1.1 C: S: HTTP/1.1 200 OK 5 S: Content-Type: text/plain S: THUMP-Status: 0.5 200 OK S: S: set-start: California Digital Library | THUMP 0.5 | 20060606161407 S: | http://ark.cdlib.org/ark:/13030/ft167nb0vq? 10 S: | http://dublincore.org/groups/kernel/erc S: here: 1 | 1 | 1 S: S: erc: S: who: Stanton A. Glantz and Edith D. Balbach 15 S: what: Tobacco War: Inside the California Battles S: when: 20000510 S: where: http://ark.cdlib.org/ark:/13030/ft167nb0vq S: [closes session]
Broad searching in THUMP General form of broad query Key ? in(DB) find(QUERY) list(RANGE) show(ELEMS) as(FORMAT) Many details to be worked out; watch for http://www.ietf.org/internet-drafts/draft-kunze-thump-01.txt
Identifiers and citations Persistent actionable identifiers should… • Lead to citation • Lead to flavors of permanence • Lead to access (if authorized) • Not strictly an “identification” problem, but this is the “404 not found” that we need to fix • Be valid for some longish period • Be carried on, in, or with the object
Choosing an id scheme The most perfect identifier scheme will be useless in the face of service failure • All identifier persistence is purely about service • Identifier confidence depends on service access Candidate schemes: URL, PURL, URN, ARK, Handle, DOI, MD5, GUID, ISxx, … • Which of these builds in service access points? • Which may actually heighten your risk without lowering your costs?
Impact of identifier scheme choice on causes of identifier breakage
ARK identifiers at a glance An ARK (Archival Resource Key) is a URL with extra structure and conventions. A sample ARK for a digital object: http://cdlib.org/ark:/12025/654xz321 \______________/\__/ \___/ \______/ (replaceable) | | | | ARK Label | | | | | 1 Name Mapping Authority | 3 Name (NAA-assigned) | 2 Name Assigning Authority Number (NAAN) 1 = current service provider; identity inert “booster rocket” 2 = organization that originally assigned the id 3 = name originally assigned to the abstract object, often opaque
ARK usage Two ARKs accessing the same thing http://loc.gov/ark:/12025/654xz321 http://rutgers.edu/ark:/12025/654xz321 Access to metadata -- add a ‘?’ http://loc.gov/ark:/12025/654xz321? Access to support statement -- add ‘??’ http://loc.gov/ark:/12025/654xz321?? Three minimal requirements to be an ARK • An archive that can’t do all 3 -- trustworthy? • Is an ARK persistent? Maybe. Have to ask.
Transparency vs opaqueness • Do ARKs have to be this ugly (opaque)? http://foobar.zaf.org/ark:/12025/654xz321/s3/f8.05v.tiff \___________________/ \__/ \___/ \______/ \____________/ NMAH Label NAAN Name Qualifier • No, but they encourage it. Persistence is all about managing associations between strings and things • And the landscape is littered with links that were required to die for political, legal, or social reasons • the appearance, deliberate or even accidental, of once-true assertions that are now misleading, infringing, offensive makes it hard for our descendants to continue managing • Pain of managing opaque ids mitigated by strong metadata • But opacity makes for ids that age and travel well • Hybrid: opaque ids name abstract preservation objects, and semantic/transient extensions address sub-objects
ARK lexical goodies Hyphens ignored • Neutralizes harm done by typesetters Too many search results? Providers may disclose (or not)… • Sub-object hierarchy using reserved ‘/’ • Variant objects using reserved ‘.’ • Usual %hh (hex encoding) as an escape
Revealing hierarchy in ARKs Sub-object hierarchy using reserved x/y • Meaning x is containing object for y, for some defined containment relationship • Works for chapters, sections, pages, etc • Persistence of that relationship? Saying ark:/12025/654/xz/321 implies also • ark:/12025/654/xz • ark:/12025/654
Revealing variants in ARKs Sub-object hierarchy using reserved x.y • Meaning x is an object basename with variant y, for some defined variant relationship • Works for formats, versions, languages, etc • Persistence of that relationship? Saying ark:/12025/654.20v.78gimplies also • ark:/12025/654.20v • ark:/12025/654
ARK namespaces reserved 12025 National Library of Medicine 12026 Library of Congress 12027 National Agriculture Library 13030 California Digital Library 13960 Internet Archive 13038 World Intellectual Property Organization 20775 University of California San Diego 29114 University of California San Francisco 28722 University of California Berkeley 15230 Rutgers University Libraries 64269 UK Digital Curation Centre 62624 New York University Libraries 67531 University of North Texas Libraries 27927 Portico/Ithaka Electronic-Archiving Initiative 12148 National Library of France 78319 Google Book Search Reserve a namespace by email to ark@cdlib.org
Opaque identifier tools Non-opaque identifier strings are chosen deliberately to assert some things that are true at the time of assignment Opaque identifier strings are best chosen by automated means, such as • NOID (nice opaque identifier) • Or UUID/GUID (universally unique identifier) • Sequence of hex encodings of your computer’s MAC address, current time, and sometimes a random number • No need to ask permission or register yourself, but based on IEEE and hardware vendor registries
Nice opaque identifiers (NOID) • A noid minter is a lightweight database for generating, tracking, and binding unique ids • The noid tool creates minters and accepts commands that operate them • Open source, available at www.cpan.org • Can mint in random or sequential order, with or without a check character guaranteeing against the most common transcription errors • Anyone can run a noid minter, maintain associations via bindings to arbitrary elements (assertions), and set up a resolver (including rule-based)
Using NOID • Identifiers minted according to a template: noid dbcreate f5.reedeedk long 13030 which produces as first minted id 13030/f54x54g11 • Noid is scheme-independent • Can be used to mint DOIs, URNs, URLs, lotto numbers, etc. • We (at CDL) use it to mint sequential transaction ids and randomized ARKs with check chars
Documentation • ARK specification http://www.ietf.org/internet-drafts/draft-kunze-ark-11.txt • NOID http://www.cdlib.org/inside/diglib/ark/noid.pdf
Persistent citation next steps Thinking through how to express when you’re citing a snapshot vs a stage that enacts a thematically consistent thing Persistent citation for small organizations • Their objects are served from at-risk hostnames and servers • They need a Name-to-Thing resolver
N2T “Entity” – persistent identifiers for smaller organizations Establish a consortium and a small web server. Each member publishes URLs under n2t.info: http://n2t.info/12345/foo/bar.zaf …which redirects to the member server URL. Why? It solves the same persistent identifier problem as URN, DOI, and Handle systems, but more fully, and at lower costand risk.
Persistent identification Persistent identifiers? We have them. • But still need persistent actionable ids Actionable “with widely available tools” • Which really means “with URLs” URNs, ARKs, Handles, DOIs, etc. become actionable (practically speaking) when embedded in URLs • All these ids have similar maintenance costs, and they all break for the usual reasons
The usual reasons Whatever the string, what matters is the thing • If the thing’s unavailable, the id’s broken Broken, for URLs, means either • The hostname is broken • Server down, gone, or renamed * • Domain name lost, provider out of business • Or the pathname to the thing is broken • Thing down, gone, or renamed * * No global fix for these, only the provider can fix.
Hostname instability Domain name lost, provider out of business • We can help this case Smaller organizations most vulnerable • The comfort of not seeing your hostname • The comfort of seeing your hostname • Traditional solutions: PURL, URN, Handle, DOI • Solutions tied to special-purpose technology, sometimes complex and proprietary