Download

1 / 29
310 likes | 454 Views
The GBIF Information Architecture Technological integration at the global level. Donald Hobern GBIF Program Officer for Data Access and Database Interoperability March 2005. GBIF and TDWG. GBIF – Global Biodiversity Information Facility

E N D
The GBIF Information ArchitectureTechnological integration at the global level Donald Hobern GBIF Program Officer for Data Access and Database Interoperability March 2005
GBIF and TDWG • GBIF – Global Biodiversity Information Facility • Megascience activity involving 43 countries/economies and 28 international organisations • Secretariat based in Copenhagen, Denmark • Mission • Free and universal access to world’s biodiversity data via Internet • Sharing primary biodiversity data for society, science and a sustainable future • Products • Registry of biodiversity data resources • Index of biodiversity data • Software tools • Web portals (http://www.gbif.net) and data services • TDWG – Taxonomic Databases Working Group • Not-for-profit scientific and educational association • Affiliated to the International Union of Biological Sciences • Mission • To provide an international forum for biological data projects • To develop and promote the use of standards • To facilitate data exchange • Products • Standards/guidelines for recording/exchanging data about organisms • Promotion of use of these standards • Forum for discussion (especially annual meeting)
Biodiversity data Class: Insecta Taxonomic Names Sequence Data Order: Lepidoptera Synonym: Pyralis nubilalis Hübner, 1796 Locus: AAL35331Definition: acyl-CoA Z/E11 desaturase 1 mvpyattadg hpekdecfed... Family: Pyralidae Genus: Ostrinia Hübner, 1825 Taxonomic Descriptions Species: Ostrinia nubilalis (Hübner, 1796) Diagnosis: Wingspan 26-30mm; sexually dimorphic;male: forewings ochreous to dark brown; female: forewings pale yellow; … Vernacular (EN): European Corn-borer Vernacular (DE): Maiszünsler Vernacular (ES): Piral del maíz Vernacular (FR): Pyrale du maïs Digital Literature and Web Resources Family: Gramineae Pheromones of Ostrinia http://www.nysaes.cornell.edu/fst/faculty/acree/pheronet/phlist/ostrinia.html Foodplant: Zea mais L. 1753 Ecological Interactions Collection: DGH Lepidoptera Record id: DGHEUR_003217 Country: France Coordinates: 03.047˚E 48.730˚N Date: 28 June 2003 Collector: Donald Hobern Specimens and Observations Abiotic Data Average Rainfall Location: 48.82°N 2.29°E Jan Feb Mar Apr ... 182.3 120.6 158.1 204.9 ...
Data resources • Resources vary in interoperability and scope for dynamic integration • Images, audio, etc. • Require text (metadata) for interpretation • Very hard for software to interpret automatically • (Normally) link to resource as a unit (e.g. via URL in web page) • Unstructured text documents (including e.g. PDF, Word, HTML) • Can be indexed for full-text search (Google) • Hard for software to interpret automatically • Normally link to document as a unit (e.g. URL in web page) • Structured XML documents • Can be indexed for full-text search • Can be parsed and interpreted by software tools (for known schemas) • Can link to document as a unit or to fragments of a document • Can use structure to develop highly-specific searches • Normally process whole documents (not random-access) • Databases • Can be exposed as structured XML documents • Can process any subset of the data (random-access selection of specific records)
June 2003 S M T W T F S 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Structured XML data <?xml version="1.0" encoding="UTF-8"?> <response> <record> <darwin:DateLastModified>2003-06-08</darwin:DateLastModified> <darwin:InstitutionCode>DGH</darwin:InstitutionCode> <darwin:CollectionCode>DGH Lepidoptera</darwin:CollectionCode> <darwin:CatalogNumber>DGHEUR_0002976</darwin:CatalogNumber> <darwin:ScientificName>Dichomeris marginella (Fabricius, 1781)</darwin:ScientificName> <darwin:BasisOfRecord>O</darwin:BasisOfRecord> <darwin:Kingdom>Animalia</darwin:Kingdom> <darwin:Order>Lepidoptera</darwin:Order> <darwin:Family>Gelechiidae</darwin:Family> <darwin:Genus>Dichomeris</darwin:Genus> <darwin:Species>marginella</darwin:Species> <darwin:ScientificNameAuthor>(Fabricius, 1781)</darwin:ScientificNameAuthor> <darwin:IdentifiedBy>Donald Hobern</darwin:IdentifiedBy> <darwin:Collector>Donald Hobern</darwin:Collector> <darwin:YearCollected>2003</darwin:YearCollected> <darwin:MonthCollected>06</darwin:MonthCollected> <darwin:DayCollected>08</darwin:DayCollected> <darwin:ContinentOcean>Europe</darwin:ContinentOcean> <darwin:Country>Denmark</darwin:Country> <darwin:County>Københavns Amt</darwin:County> <darwin:Locality>Merianvej, Hellerup</darwin:Locality> <darwin:Longitude>12.538</darwin:Longitude> <darwin:Latitude>55.737</darwin:Latitude> <darwin:CoordinatePrecision>100</darwin:CoordinatePrecision> <darwin:IndividualCount>1</darwin:IndividualCount> <darwin:Notes>1 in Skinner trap</darwin:Notes> </record> </response> Observation record formatted using the Darwin Core
Some TDWG Data Standards • Darwin Core • Simple XML data model to represent taxon occurrence records (only core attributes) • Extensions to handle e.g. curation details, microbial data, image data • ABCD Schema – Access to Biological Collection Data • More complex XML data model to represent collection or observation data • Detailed document structure including features for different communities • DiGIR – Distributed Generic Information Retrieval • XML protocol for searching remote data resources • Suitable for use with a wide range of different data models • BioCASe Protocol • XML protocol for searching remote data resources with more complex schema (e.g. ABCD) • Derived from DiGIR – new unified DiGIR/BioCASe protocol being developed (”TAPIR”) • Taxon Concept Schema • XML data model currently under development for exchange of nomenclatural/taxonomic data • First version to be used for implementation in 2005 • SDD Schema – Structured Descriptive Data • XML data model for descriptive data relating to taxa or specimens (highly generalised) • Suitable for representation of character tables, diagnostic keys, etc.
DiGIR Protocol <?xml version="1.0" encoding="UTF-8"?> <request xmlns="http://digir.net/schema/protocol/2003/1.0" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:darwin="http://digir.net/schema/conceptual/darwin/2003/1.0"> <header> <version>1.0.0</version> <sendTime>2004-07-20T09:56:00-0500</sendTime> <source>127.0.0.1</source> <destination resource="HDS">http://any.net/digir/DiGIR.php</destination> <type>search</type> </header> <search> <filter> <and> <equals> <darwin:Collector>Thomas, J.</darwin:Collector> </equals> <equals> <darwin:Genus>Rubus</darwin:Genus> </equals> </and> </filter> <records limit="3" start="0"> <structure> <xsd:element name="record“ minOccurs="0“ maxOccurs="unbounded"> <xsd:complexType> <xsd:sequence> <xsd:element ref="darwin:InstitutionCode"/> <xsd:element ref="darwin:CollectionCode"/> <xsd:element ref="darwin:CatalogNumber"/> <xsd:element ref="darwin:ScientificName"/> <xsd:element ref="darwin:Latitude"/> <xsd:element ref="darwin:Longitude"/> </xsd:sequence> </xsd:complexType> </xsd:element> </structure> </records> <count>true</count> </search> </request> Request <?xml version="1.0" encoding="utf-8" ?> <response xmlns="http://digir.net/schema/protocol/2003/1.0"> <header> <version>$Revision: 1.96 $</version> <sendTime>2004-07-20T09:56:03-0500</sendTime> <source resource="HDS">http://any.net/digir/DiGIR.php</source> <destination>127.0.0.1</destination> <type>search</type> </header> <content xmlns:darwin="http://digir.net/schema/conceptual/darwin/2003/1.0"> <record> <darwin:InstitutionCode>INS</darwin:InstitutionCode> <darwin:CollectionCode>COL</darwin:CollectionCode> <darwin:CatalogNumber>27694</darwin:CatalogNumber> <darwin:ScientificName>Rubus brasiliensis</darwin:ScientificName> <darwin:Latitude>-23.6625</darwin:Latitude> <darwin:Longitude>-46.7738</darwin:Longitude> </record> <record> <darwin:InstitutionCode>INS</darwin:InstitutionCode> <darwin:CollectionCode>COL</darwin:CollectionCode> <darwin:CatalogNumber>27907</darwin:CatalogNumber> <darwin:ScientificName>Rubus brasiliensis</darwin:ScientificName> <darwin:Latitude>-23.412</darwin:Latitude> <darwin:Longitude>-46.7899</darwin:Longitude> </record> <record> <darwin:InstitutionCode>INS</darwin:InstitutionCode> <darwin:CollectionCode>COL</darwin:CollectionCode> <darwin:CatalogNumber>27908</darwin:CatalogNumber> <darwin:ScientificName>Rubus urticaefolius</darwin:ScientificName> <darwin:Latitude>-23.412</darwin:Latitude> <darwin:Longitude>-46.7899</darwin:Longitude> </record> </content> <diagnostics> <diagnostic code="STATUS_INTERVAL" severity="info">3600</diagnostic> <diagnostic code="STATUS_DATA" severity="info">191,1,1</diagnostic> <diagnostic code="MATCH_COUNT" severity="info">26</diagnostic> <diagnostic code="RECORD_COUNT" severity="info">3</diagnostic> <diagnostic code="END_OF_RECORDS" severity="info">false</diagnostic> </diagnostics> </response> Response
BioCASe Provider BioCASe Provider MaNIS Provider OBIS Provider IPGRI Banana Provider IPGRI Soy Bean Provider Taxon Occurrence Taxon Occurrence Taxon Occurrence Taxon Occurrence Taxon Occurrence Taxon Occurrence Darwin Core Darwin Core Darwin Core Darwin Core Darwin Core Darwin Core ABCD ABCD Curatorial Marine IPGRI Passport IPGRI Passport Banana Descriptor Soy Bean Descriptor DiGIR-BioCASe Protocol and Nested Networks Get DiGIR-style records each with a set of Darwin Core descriptors and a complete ABCD Unit Get full set of Soy Bean crop descriptors. User Get standard plant genetic resource Passport data for all crop types. Get complete ABCD documents from each BioCASe provider Get Darwin Core records where darwin:ScientificName equals Puma concolor from any provider.
Data navigation Author Name Collector Name Taxon Concept Name Type material Publication Title, Year Sequence Data Specimen Catalogue Number Identified as XML Barcode Data Identified as XML Taxon Concept Name Type material Specimen Catalogue Number Barcode Data Referenced material Publication Title, Year Synonymy Relationship Character Data Barcode Data Character Data Type material Specimen Catalogue Number Taxon Concept Name Character Data Identified as Publication Title, Year Collector Name PDF Author Name
Integration strategies • Different approaches to integrating distributed information: • Data Warehouse • Bring all data together • Data owners can still maintain control over their data • Single agreed central data model • All data in one place any complex query can be constructed • Federated Network • Data remain with original owners • Data owners can manage data as best suits them • Agreed data models for exchange • Queries can become expensive as number of resources increases • Indexed Network • Data remain with original owners • Data owners can manage data as best suits them • Agreed data models for exchange • Most frequently-issued queries can be handled in index • Selection may be influenced by community culture • Network may include warehouses/indices for specific areas • Key driver should be user requirements (use cases)
Central services • GBIF plans to offer the following central services: • Service Registry • – discover data resources • Data Index and Aggregated Data Services • – find distributed data • Schema Repository • – interpret structured data • Feedback Mechanisms • – add value by connecting users to providers • Data Validation Services • – report potential inconsistencies within data • Usage Reporting Mechanisms • – recognise providers for sharing data • Globally Unique Identifier Services • – provide persistent references to data records
GBIF Network Networked data resources Specimens: Flowering Plants of Africa Observations: Birds of Central America Specimens: Proteaceae of the World Museum A Observations: Butterflies of Belize Observer Network B Taxon Names: Proteaceae of the World Checklist: Birds of Belize Specimens: Bacteria Cultures Specimens: Mammals of North Europe Taxon Names: Mammals of the World Taxon Names: Bacteria Further Links: Mammals Further Links: Bacteria Museum C University D
Specimen Data Specimen Data Specimen Data Specimen Data Specimen Data Specimen Data Specimen Data Specimen Data Specimen Data Name Lists Observation Data Links to other data Data index User requests GBIF Data Nodes Biodiversity Data Access Biodiversity Data Index Taxonomic Name Service (ECAT) Catalogue of Life
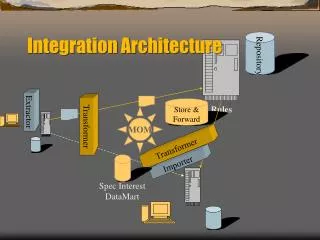
XML URL XML TCS XML SDD URL URL Image Distributed data access GBIF Global Portal Thematic Portal Regional Portal Software Applications Presentation & Analysis GBIF Data Index Entrez OBIS Indexing GBIF Service Registry Network-specific Registries CGIAR Discovery Access XML ABCD DwC XML TaXMLit Taxonomy / Nomenclature Specimens Descriptive Data Sequences / Barcodes Struc-tured XML HTML web page PDF Resources Databases Documents Structured Unstructured
Handling of unstructured data – a possible approach • Develop set of keywords to classify web pages • Need standard classification of biodiversity information (probably with varying levels of granularity) • Register pages under { taxonName, url, keywords, audience, language, ... } • Sufficient immediately to construct tables of links as part of taxon-specific web pages • Develop corresponding XML tags to mark up sections of web text (<description>, <habitat>, etc.) • See TaXMLit from Biologia Centrali-Americana project for related approach • Possible to extract sections for re-use elsewhere • Example: a web site requires a description of common garden birds • Find suitable text by audience and language for each taxon? • Maximise benefits from effort expended in developing content • All information developed in any format can be indexed and discovered • All resources can contribute to the global data pool • Can develop plug-and-play taxonomic/regional/thematic portals based on the entire network of registered data elements, structured and unstructured
Specimen Indexing Service Data Input Database Researcher Web Server Validation Service Administrator Data validation • Validation service: • Extensible framework for checking XML data • Basic checks for XML validity (e.g. UTF-8) • Validation against schema • Checks that element content has expected structure or uses expected values • Geospatial checks – coordinates in expected countries or on land / in sea • Taxonomic checks – is name known? does it appear in referenced authority list? is higher taxonomy consistent? Internet
1.1 Schema repository – version history .xsd Schema A .xsd 1.0 • Elements • Datatypes • Cardinality • Enumerated values • Annotations .dtd Schema B 1.0 1.1 1.2 .dtd .??? • Structured store of data models for each schema • Modelling of version history for each schema • Single location from which to generate new machine-readable formats • Should such a tool also provide an environment in which to develop new data models?
1.1 Schema repository – documentation Schema A 1.0 Schema B 1.0 1.1 1.2 • Automated generation of standardised HTML, PDF and other human readable documentation for each standard • Can easily generate documentation e.g. of inter-version differences
1.1 Schema repository – conceptual mappings Schema A .xslt 1.0 .java ? Schema B 1.0 1.1 1.2 .pl ? • Identify relationships between elements in different versions of the same schema or different schemas (need interfaces to allow these linkages to be defined) • Generate software products to automate transformation between different versions and schemas • How should we handle different content models for related concepts? • Should mappings simply be between different imported schemas, or should they all be made against some central set of concepts?
Problems to solve – data served from multiple locations Museum A DiGIR provider Global Provider Registry Aggregator DiGIR provider Global Data Index Import by aggregator Museum B DiGIR provider • Different networks of providers will serve up the same records through different routes, and software tools will not be able to detect all duplicate records • Aggregator nodes may in many cases themselves be the sole provider for other important records • The same situation will also occur e.g. if a taxonomist serves data for all specimens from many institutions for a single genus, including some that may also have been digitised by the institutions themselves • No reliable mechanism to relate Agg:MusA/CollX to MusA:CollX or Agg:MusA/CollX:1001 to MusA:CollX:1001
Aenetus virescens Distribution Auckland (see 1001) Wellington (see 1002) Problems to solve – referring to data from outside network Revision of the genus Aenetus Material examined Museum A, Collection X 1001, 1002 Museum A DiGIR provider http://www.museumA.org/digir.php ? Global Data Index http://www.gbif.net/data/digir.jsp ? • Data records have no stable URLs on the network (even using constructed DiGIR queries) • Provider endpoints may change, and specimens may move to different institutions • There needs to be a reliable way to reference each data record from other web sites and in external media • The solution needs to handle situations in which data providers move to new locations • It should ideally also be possible to refer to a particular version of each record in case of modifications
Problems to solve – referring to taxon concepts What is the relationship between the concepts from Taxonomy Server A and Taxonomy Server B? Taxonomy Server A Concept: Aus bus sensu Smith, 2003 == Aus bus sensu Jones, 1965 == Aus cus bus sensu Black, 1926 > Aus bus sensu Brown, 1949 > Aus dus sensu Brown, 1949 User Taxonomy Server B Concept: Xus bus sensu J. Owen, 2002 == Aus bus sensu P. Brown, 1949 Concept: Yus dus sensu J. Owen,2002 == Aus dus sensu P. Brown, 1949 • No standardised way to reference taxonomic publications or taxon concepts to allow reliable machine processing of the relationships between them (is ”P. Brown, 1949” the same as ”Brown, 1949”?) • Need mechanisms to allow data providers to refer to taxon concepts in a reliable and consistent way
Globally unique identifiers – requirements • Universal reusable mechanism which can be applied to any type of biodiversity data record (specimen, collection, institution, taxon concept, taxonomic publication, image, etc.) • Identifiers must refer uniquely to a single data element • Users must be able to resolve each identifier to locate the data to which it relates • Identifiers must be resolvable even if data changes ownership or the server is moved to a new endpoint • Identifiers must be suitable for use by the wider life science community and others • It should be as simple as possible for researchers • to create new identifiers • to discover existing identifiers associated with data items • to resolve identifiers to retrieve the associated data
Potential model – Life Science Identifiers (LSIDs) Format urn:lsid:<domainName>:<namespace>:<objectId>[:<revisionId>] Example: referencing a PubMed article urn:lsid:ncbi.nlm.nih.gov:pubmed:12571434 Example: referencing first version of the 1AFT protein in the Protein Data Bank urn:lsid:pdb.org:pdb:1AFT:1 Potential example: referencing specimen record in GBIF Network (identifiers assigned centrally) urn:lsid:gbif.net:Specimen:2706712 Potential example: name record from IPNI urn:lsid:ipni.org:TaxonName:82090-3:1.1 • Specification for Uniform Resource Name model from EMBL, IBM, I3C and OMG • ”A straightforward approach to naming and identifying data resources stored in multiple, distributed data stores in a manner that overcomes the limitations of naming schemes in use today” • All LSIDs are formed from 5 or 6 colon-delimited components: urn, lsid, the domain name of the authority for the identifier, a namespace for the identifier, the identifier for the object within the namespace, and an optional revision number
Image Web-based taxonomy? Taxonomist input GBIF Global Portal Thematic Portal Revision Taxonomic Collaboration Environment Presentation & Analysis Literature Sequences / Barcodes Group data GBIF Data Index Indexing Taxonomy / Nomenclature Network data Specimens Group resources GBIF Registry Characters Discovery Network resources Taxonomy / Nomenclature Specimens Descriptive Data Sequences / Barcodes Struc-tured XML HTML web page PDF Resources Databases Documents Structured Unstructured
Image What is Species Bank? User Browser / Client Tool Regional Portal GBIF Data Portal Species Bank ? Taxon Portal Species Bank ? HTML web pages GBIF Data Index Map Service Taxonomy / Nomenclature Specimens Descriptive Data Sequences / Barcodes Struc-tured XML HTML web page PDF
Links Global Biodiversity Information Facility http://www.gbif.org/ Communications Portal http://www.gbif.net/ Data Portal http://circa.gbif.net/Public/irc/gbif/dadi/library?l=/architecture Architecture documents Taxonomic Databases Working Group http://www.tdwg.org/ Including access to working groups