Download

1 / 17
170 likes | 195 Views
Explore how the Lombard effect influences speech enhancement systems using deep learning methods. Discover the benefits of incorporating visual information and compare systems trained on Lombard speech with non-Lombard speech.

E N D
Effects of Lombard Reflex on Deep-Learning-Based Audio-Visual Speech Enhancement Systems Daniel Michelsanti1, Zheng-Hua Tan1, Sigurdur Sigurdsson2 and Jesper Jensen1,2 1Centre for Acoustic Signal Processing Research (CASPR), Aalborg University 2Oticon A/S {danmi,zt,jje}@es.aau.dk {ssig,jesj}@oticon.com
About Us Daniel Michelsanti is a PhD Fellow at the Centre for Acoustic Signal Processing Research (CASPR), Aalborg University, Denmark, under the supervision of Zheng-Hua Tan, Sigurdur Sigurdsson and Jesper Jensen. His research interests include speech processing, computer vision and deep learning. Zheng-Hua Tan is a Professor in the Department of Electronic Systems at Aalborg University, Denmark. He is also a co-founder of CASPR. His research interests include machine learning, deep learning, speech and speaker recognition, noise-robust speech processing, multimodal signal processing, and social robotics. Sigurdur Sigurdsson is a Senior Specialist with Oticon A/S, Copenhagen, Denmark. His research interests include speech enhancement in noisy environments, machine learning and signal processing for hearing aid applications. Jesper Jensen is a Senior Principal Scientist with Oticon A/S, Copenhagen, Denmark, and a Professor in the Department of Electronic Systems, at Aalborg University. He is also a co-founder of CASPR. His main interests include signal retrieval from noisy observations, coding, intelligibility enhancement and signal processing for hearing aid applications. Aalborg University
Instructions • This is a demonstration regarding the impact of the Lombard effect on speech enhancement. • To navigate the demo you can: • Click on the blue bar on the right to go to the next page. • Click on the blue bar on the left to go to the previous page. • Click on the media to play the content. The media in this demonstration are playable if they have a red square on the bottom left corner. Aalborg University
Speech Enhancement Speech enhancement is the task of estimating the clean speech of a target speaker immersed in an acoustically noisy environment, where different sources of disturbance are present, e.g. competing speakers, background music, and reflections from the walls. Usually this estimation is done by performing a manipulation of the time-frequency representation of the signal. Time-Frequency Domain Time Domain Icons designed by Freepik Aalborg University
Lombard Effect • In presence of background noise, speakers instinctively change their speaking style to maintain their speech intelligible. This reflex is known as Lombard effect [1], and it is characterized by: • an increase in speech sound level [2]. • a longer word duration [3]. • modifications of the speech spectrum [2]. • a speech hyper-articulation [4]. • It has been shown that the mismatch between the neutral and the Lombard speaking styles can lead to sub-optimal performance of speaker [5] and speech recognition [2] systems. Aalborg University
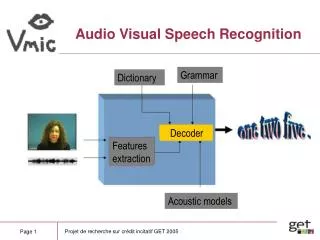
Architecture We use a neural network architecture inspired by [6] and identical to [7]. For the single-modality systems, one of the encoders is discarded. Aalborg University
Goal The purpose of this demo is two-fold: Showing the benefit of using visual information of speakers to enhance their speech. Comparing systems trained on non-Lombard (NL) speech with systems trained on Lombard (L) speech. We trained six deep-learning-based systems: The systems were trained on the utterances from the Lombard GRID corpus [8], to which speech shaped noise is added at several signal to noise ratios (SNRs). The following videos are from speakers observed during training (seen speakers). For more details, refer to [9]. • AO-L – Audio-only trained on Lombard speech. • VO-L – Video-only trained on Lombard speech. • AV-L – Audio-visual trained on Lombard speech. • AO-NL – Audio-only trained on non-Lombard speech. • VO-NL – Video-only trained on non-Lombard speech. • AV-NL – Audio-visual trained on non-Lombard speech. Aalborg University
Speech Enhancement (-20 dB SNR) Comparison between audio-only (AO), video-only (VO) and audio-visual (AV) systems. UNPROCESSED AO-L VO-L AV-L “Lay blue by G zero soon” “Bin green by Q zero again” “Bin blue in Z seven please” Aalborg University
Speech Enhancement (-10 dB SNR) Comparison between audio-only (AO), video-only (VO) and audio-visual (AV) systems. UNPROCESSED AO-L VO-L AV-L “Lay blue by G zero soon” “Bin green by Q zero again” “Bin blue in Z seven please” Aalborg University
Speech Enhancement (0 dB SNR) Comparison between audio-only (AO), video-only (VO) and audio-visual (AV) systems. UNPROCESSED AO-L VO-L AV-L “Lay blue by G zero soon” “Bin green by Q zero again” “Bin blue in Z seven please” Aalborg University
Estimated Speech Quality and Intelligibility The performance of the models are evaluated in terms of PESQ and ESTOI, because they are good estimators of speech quality and intelligibility, respectively. PESQ ranges from -0.5 to 4.5, where high values correspond to high speech quality. For ESTOI, whose range is practically between 0 and 1, higher scores correspond to higher speech intelligibility. Aalborg University
Speech Enhancement (-20 dB SNR) Comparison between non-Lombard (NL) and Lombard (L) systems. AO-NL AO-L VO-NL VO-L AV-NL AV-L “Lay blue by G zero soon” “Bin green by Q zero again” “Bin blue in Z seven please” Aalborg University
Speech Enhancement (-10 dB SNR) Comparison between non-Lombard (NL) and Lombard (L) systems. AO-NL AO-L VO-NL VO-L AV-NL AV-L “Lay blue by G zero soon” “Bin green by Q zero again” “Bin blue in Z seven please” Aalborg University
Speech Enhancement (0 dB SNR) Comparison between non-Lombard (NL) and Lombard (L) systems. AO-NL AO-L VO-NL VO-L AV-NL AV-L “Lay blue by G zero soon” “Bin green by Q zero again” “Bin blue in Z seven please” Aalborg University
Estimated Speech Quality and Intelligibility The performance of the models are evaluated in terms of PESQ and ESTOI, because they are good estimators of speech quality and intelligibility, respectively. PESQ ranges from -0.5 to 4.5, where high values correspond to high speech quality. For ESTOI, whose range is practically between 0 and 1, higher scores correspond to higher speech intelligibility. Aalborg University
References [1] H. Brumm and S. A. Zollinger, “The evolution of the Lombard effect: 100 years of psychoacoustic research,” Behaviour, vol. 148, no. 11-13, pp. 1173–1198, 2011. [2] J.-C. Junqua, “The Lombard reflex and its role on human listeners and automatic speech recognizers,” The Journal of the Acoustical Society of America, vol. 93, no. 1, pp. 510–524, 1993. [3] A. L. Pittman and T. L. Wiley, “Recognition of speech produced in noise,” Journal of Speech, Language, and Hearing Research, vol. 44, no. 3, pp. 487–496, 2001. [4] M. Garnier, L. Ménard, and B. Alexandre, “Hyper-articulation in Lombard speech: An active communicative strategy to enhance visible speech cues?,” The Journal of the Acoustical Society of America, vol. 144, no. 2, pp. 1059–1074, 2018. [5] J. H. L. Hansen and V. Varadarajan, “Analysis and compensation of Lombard speech across noise type and levels with application to in-set/out-of-set speaker recognition,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 17, no. 2, pp. 366–378, 2009. [6] A. Gabbay, A. Shamir, and S. Peleg, “Visual speech enhancement,” in Proc. of Interspeech, 2018. [7] D. Michelsanti, Z.-H. Tan, S. Sigurdsson, and J. Jensen, “On training targets and objective functions for deep-learning-based audio-visual speech enhancement,” arXiv preprint: https://arxiv.org/abs/1811.06234. [8] N. Alghamdi, S. Maddock, R. Marxer, J. Barker, and G. J. Brown, “A corpus of audio-visual Lombard speech with frontal and profile views,” The Journal of the Acoustical Society of America, vol. 143, no. 6, pp. EL523–EL529, 2018. [9] D. Michelsanti, Z.-H. Tan, S. Sigurdsson, J. Jensen, “Effects of Lombard Reflex on the Performance of Deep-Learning-Based Audio-Visual Speech Enhancement Systems”, arXiv preprint: https://arxiv.org/abs/1811.06250. Aalborg University
Back to the Title Page Aalborg University