데이타 마이닝 Data Mining
데이타 마이닝 Data Mining. Pieter Adriaans, Dolf Zantinge 저, Addison-Wesley 출판, 1996 용환승 역, 그린출판사 1998년. KDD 와 Data Mining. 남미 작가 보르게스의 작품 “바벨 도서관:관”의 예: 끝없는 책들의 창고 인간이 생각할 수 있는 모든 책들이 이 도서관에 있다. 누구도 위의 가설을 검증할 수 없다. 현재, 데이터는 무한한 반면에 정보의 부재를 상징 데이터의 양은 매년 2배씩 증가 의미있는 정보의 발견은 더욱 어려워 짐.


데이타 마이닝 Data Mining
E N D
Presentation Transcript
데이타 마이닝Data Mining Pieter Adriaans, Dolf Zantinge저, Addison-Wesley 출판, 1996 용환승 역, 그린출판사 1998년
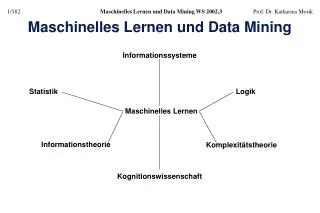
KDD와 Data Mining • 남미 작가 보르게스의 작품 “바벨 도서관:관”의 예: 끝없는 책들의 창고 • 인간이 생각할 수 있는 모든 책들이 이 도서관에 있다. • 누구도 위의 가설을 검증할 수 없다. • 현재, 데이터는 무한한 반면에 정보의 부재를 상징 • 데이터의 양은 매년 2배씩 증가 • 의미있는 정보의 발견은 더욱 어려워 짐
생산요소로서의 정보 • 정보는 중요한 생산 요소의 일부 • 데이터의 폭발적 증가는 데이터에 대한 정제, 추출, 해석 과정의 자동화 요구 • 주식 거래 시스템 • 컴퓨터가 자동으로 분석하여 거래 처리 • 컴퓨터간의 게임 • 선진국과 후진국간의 정보기술 격차 증대
학습 능력을 가진 컴퓨터 • 학습 능력은 생물체의 본질적인 특성 • 1950년대 인공지능 연구의 초점 • 60년대 민스키의 퍼셉트론의 한계 증명 • 80년대 새로운 학습 모델이 제시 • 의사 결정트리 • 다양한 신경망 구조 • 유전자 알고리즘 • 전문가 시스템 • 강력한 하드웨어의 지원
데이터 마이닝 • 데이터의 기계적 생산은 데이터의 기계적 분석 필요 • 대용량의 데이타베이스에서 정보 다이아몬드를 탐색하는 것 • KDD:Knowledge Discovery in Database • 데이터로부터 지식을 추출하는 전 과정 • 데이터 마이닝: KDD 과정에서 탐사 단계
데이터 마이닝과 질의 환경 • SQL 질의 도구 • 누가 어떤 제품을 언제 구매했나? • 7월 특정 지점의 판매 실적은? • 무엇을 검색할 것인지 알고 있는 경우만 SQL 사용 가능 • 마이닝 질의 형태 • 고객들을 분류할 때 중요한 인자는? • 고객들의 구매 동향은? • SQL을 사용하는 경우, 기준을 세우고, SQL로 확인하는 복잡한 절차 요구
마케팅에서의 데이터 마이닝 • 고객들의 15년간 구매 정보 데이타베이스 • 일반적인 광고 우편은 3%-4%의 회신율 • 고객을 분류, 가능성이 높은 고객에만 우편 발송 • 동일한 회신율 유지, 50%의 우편 비용 절감 • 실용적 응용 분야 • AT&T: 고객자료 분석 • BBC: 시청률 조사 • 많은 은행, 보험 회사들이 KDD 적용 준비 중 • 많은 도구들 등장: Integral Solution사 Clementine, IBM의 Intelligent Miner등
데이터 마이닝 프로젝트의 문제점 • 장기적인 계획의 부족 • 최신 정보로 갱신되지 않는 파일 • 부서간의 갈등: 데이터 제공 거부 • 전산 처리 부서와의 원활하지 못한 협조체제 • 법률과 사생활 보호 문제로 인한 제약 • 화일들간의 기술적인 호환문제: 표준 DB • 해석 문제: 연관성을 발견했지만, 의미 해석 • 데이터의 훼손이나, 부정행위 발견도 가능
지식의 유형 • 표층 지식(shallow knowledge) • SQL로 쉽게 파악되는 정보 • 다차원 지식(multi-dimensional knowledge) • OLAP 도구를 사용하여 데이터의 군집과 정렬을 탐색 • SQL로도 탐색 가능 • 단 OLAP은 이와 같은 탐색과 분석에 최적화됨. • 은닉 지식(hidden knowledge) • 패턴 인식, 기계-학습 알고리즘으로 발견: 수 시간내 • SQL을 사용할 경우 많은 시간 소모: 수 개월 • 심층 지식(deep knowledge) • 암호화된 정보의 경우, 해독키가 없으면 해독 불가능 • 학습으로 해결 안 되는 정보
비용 타당성 분석 • KDD 구현에는 데이타웨어하우스와 비즈니스 업무 재구축(BPR)을 수반 • 마이닝을 수작업과 컴퓨터 활용의 비교 필요 • 컴퓨터의 적용 이점 • 속도(speed) • 복잡도(complexity) • 반복(repetition) • 초기 데이터 마이닝 환경 구축 비용보다 재사용을 통한 장기적 이점 중요
세부적인 지식 탐사 절차 • 잡지 출판사의 사례 • 자동차(car), 주택(house), 스포츠(sports), 음악(music), 유머(comic)의 5개 잡지 발간 • 마케팅 전략을 위해 고객의 유형 분석 필요 • “자동차 잡지 독자들이 가지는 전형적인 신상 정보는 무엇인가?” • “자동차와 유머에 대한 관심에는 어떤 상관 관계가 있는가?”
데이타 선정(Data Selection) • 출판사의 주문 시스템의 운영 데이터에서 선정 • 선정 레코드 항목 • 고객번호(client number), • 이름(name), • 주소(address), • 구입일(date of purchase made) • 구입잡지(magazine purchased) • 그림 4.2 원본 데이터의 예
정제(cleaning) • 중복 제거가 중요 • 입력 오류, 변경 미비 등으로 한 객체가 여러 레코드에 표현 • 고의로 고객이 정보를 부정확하게 입력하는 경우 • 이름, 주소 등의 스펠링을 틀리게 함 • 예제 데이터에서 Jhonson과 Jonson의 경우 주소를 보면 동일인임을 알 수 있다. • 도메인 일관성 오류 • 구입일에 ‘01-01-01’로 입력 • 생일 입력시 비밀을 위해서 ‘11-11-11’을 입력함 • NULL값으로 대체
보강(enrichment) • 고객 정보에 추가 자료를 보강 • 생일(date of birth), • 수입(income), • 저축(amount of credit), • 자동차(car owner)와 주택 보유(house owner) 여부 등 • 데이터 구입 또는 고객과의 인터뷰 • 기존의 정보와 조인을 통해 보강
코딩(Coding) • 데이터에 대한 변환 • 레코드 삭제: 누락된 정보를 가진 레코드는 삭제 • 열 삭제: 고객의 이름은 무의미 • 코딩을 사용한 변환 • 주소: 구역으로 처리 • 나이: 10년 단위로 • 구독날짜: 월번호(month number)로 처리 • 시계열 패턴 파악 가능 • 저축이 $13,000이상으로 나이가 22에서 31세로 유머잡지를 구독한 고객은 5년 후 자동차 잡지를 구독할 것이다.
예제 데이터에서의 코딩 • 주소를 구역으로: 주소 정보의 단순화 필요 • 적절한 수의 구역으로 정해서 코드화 • 생일을 나이로 • 생일 정보를 100개의 연령 그룹으로 또는 10년 단위의 그룹으로 변환 • 수입은 1000으로 나눈다 • 수입 정보의 단순화, 나이 클래스와 유사하게 • 저축도 1000으로 나눔 • 자동차 보유 유무 등은 1/0의 이진 항목으로 표현 => 패턴 인식이 용이
코딩 • 구독일은 1990년 부터의 월번호로 변환 • 1990년 1월을 1로, 1991년 12월은 월번호가 24임 • 데이터에 대한 시계열 분석이 용이 • 날짜 단위는 시간 종속 관계 분석에 무의미 • 크리스마스 등 특별한 날의 구매 행위 분석 시는 별도 • 그림 4.8
코딩 • 잡지간의 구독 연관성 표현 미흡 • 한 독자가 구독하는 잡지를 모두 표현할 수 있도록 수정 필요 • ‘구독잡지’ 항목에 대해서 평평화(flattening) 연산 수행 • 항목의 카디널리티 수 만큼의 이진 항목 생성 • 잡지의 경우 5개가 있으므로 5개의 이진 항목으로 구성 • 그림 4.9 최종 테이블
데이터 마이닝의 기법들 • 질의 도구(query tools) • 통계적 기법(statistical technique) • 가시화(visualization) • 온라인 분석 처리(OLAP: online analytical processing) • 사례-기반 학습(Case-based learning, 최단 인접 이웃 (k-nearest neighbor)) • 의사결정 트리(decision tree) • 연관 규칙(association rule) • 신경망(neural network) • 유전자 알고리즘(genetic algorithm)
질의 도구를 사용한 분석 • 기본적인 사항 분석 • SQL로 표층 데이터 파악 • 80% 정도의 정보 파악 가능 • 그러나 나머지 20%의 숨겨진 정보가 중요 • 평균 연산 등 간단한 통계 정보 • 그림 4.10의 고객 자료 평균 값 • 그림 4.11 특정 잡지를 구입할 고객의 평균 확률 • 그림 4.12 잡지별 평균 고객 정보 • 자동차 잡지의 구독 평균 나이는 적다. • 유머 구독자의 평균 나이가 가장 적다.
질의 도구를 사용한 분석 • 한 사람이 구입하는 평균 잡지 수 (그림 4.13) • 9%의 고객이 하나도 구입 안함 • DB의 오류 파악 가능
가시화 기법 • Visualization Technique • 데이터 집합에서 패턴을 발견하는 데 유용 • 3차원 그래픽 브라우징 • 분산 다이어그램: 두 항목의 정보를 카르테시안 공간에 출력 • 수입과 나이에 따른 음악 잡지의 구독자 분포 • 수입이 낮고, 젊은 고객이 주로 음악 잡지를 구독
3차원 가시화 기법 예(나이, 수입, 저축에 따른 음악 잡지 구독)
가능성(likelihood)과 거리(distance) • 공간 은유(space-metaphor) • 레코드를 다차원 공간의 점으로 인식 • 공간적으로 가까운 레코드들은 유사(공통점이 많다) • 저차원 공간의 경우 데이터를 구름으로 가시화 • 군집(cluster) 파악 가능 • 나이/수입/저축 3차원 공간에서의 군집 분석 예 • 그림 4.20
레코드간의 거리 계산 • 레코드의 항목들들이 정규화 (단위) 되어야 함 • 나이: 1-100, 수입: $0- $100,000
OLAP 도구 • Online Analytical Processing • n개의 항목은 n차원 공간으로 간주 • 어떤 유형의 잡지가 특정 구역에서 어떤 연령층에게 판매되는 가? • 제품, 구역, 구입일, 나이의 4차원 질문 • 여러 차원의 관련성 질문 • 2차원 관계 테이블로는 제한적 • 별도의 다차원 분석 모델 및 도구 필요 • OLAP은 새로운 해결책 탐색 불가능 • 제한적인 분석만 가능
K-최단 인접(k-nearest neighbor) • 공간 은유 • 동일한 타입의 레코드는 데이터 공간에서도 가까이 이웃한다. • 기본 철학: 이웃이 하는 대로 한다. • 특정 고객의 행동 예측시, 가까운 열 명의 고객에 대한 행동을 관찰, 평균이 예측 행동이 됨. • K-최단 인접: K개의 이웃을 분석 • 2차함수 복잡도(quadratic complexity) 연산 필요 • 마이닝 알고리즘은 n (log n) 이하가 바람직 • 제한된 크기의 레코드에 적합
K-최단 인접 적용에 따른 문제 • 테이블의 독립 항목이 큰 경우 • 고차원 공간의 문제 • 백만 개의 데이터 점들이 3차원에 균등하게 분포 • 최단 인접 질의문이 효과적 • 백만 개의 데이터 점들이 20차원에 분포시 • 거의 텅 빈공간, 두 데이터 점의 거리가 거의 동일 • 해결 방안 • 각 항목의 상대적 중요성 계산 • 고객의 행동을 예측하는 데 실제로 도움이 되는 항목만으로 분석
의사 결정 트리(decision tree) • 고객 행동 예측 방안으로 고객의 특정 정보를 기준으로 다른 항목을 분류 • 예) 고객의 나이를 기준으로 자동차 잡지의 구입 여부 분류, 기준 설정 • 그림 4.22 • 44.5세 이상은 1%만이 구독, 이하는 62%가 구독 • 트리 레벨의 확장 • 수입이 높은 사람(34.5이상)은 잡지 구독을 안함 • 수입이 34.5보다 낮고, 나이가 31.5세 이하의 사람은 자동차 잡지에 대한 관심이 높다.
의사 결정 트리 기법의 특징 • 장점 • 대규모 데이터 집합으로 확장 용이 • 의사결정 과정을 직관적으로 제공 • 신경망의 경우 결론 도달 과정은 블랙박스 • 단점 • 주택 잡지 구독자 분석의 예: 그림 4.26 • 명확한 분류가 안되는 경우 발생
연관 규칙(association rule) • 데이타베이스 • 고객의 성별, 자동차의 색상과 차종, 애완동물의 종류, 구매하고자 하는 제품의 개수에 관한 정보 • 마이닝을 통한 관련성 규칙의 예 • “빨간 스포츠카와 작은 개를 가진 90%의 주부들이 Chanel No. 5를 사용한다” • 연관 규칙의 중요성 측정 척도 • 마이닝 결과는 많은 연관 규칙을 제시 • 잡음(noise) 정보와 중요 정보를 판단
연관 규칙 (계속) • 연관 규칙의 표현 • MUSIC_MAG, HOUSE_MAG => CAR_MAG • 음악과 주택 잡지 구독자는 자동차 잡지를 구독한다. • 지지율(support) • DB의 총 instance 비율 • 위의 경우, 전체 고객 중 음악/주택/자동차 잡지 구독자의 비율 • 신뢰도(confidence) • 음악/주택 잡지 구독자 중에서, 자동차 잡지 구독자 비율
단일 항목간의 연관 분석 • 유머/음악, 자동차/음악이 관련이 큼.
연관 규칙의 대화식 분석 • 자동차 잡지의 경우, 그림 4.28 • 신뢰도: 33%, 지지율 3% 이상의 결과만 제시 • 분석 결과 • SPORT_MAG => CAR_MAG (36%, 45%) • MUSIC_MAG => CAR_MAG (96%, 15%) • 신뢰도와 지지율이 상당히 높음. • COMIC_MAG => CAR_MAG (57%, 8%)
대화식 분석 결과 • 음악잡지를 포함한 연관 분석 • MUSIC_MAG, HOUSE_MAG => CAR_MAG • (97%, 9%), 의미 있는 결과 도출 • MUSIC_MAG, SPORTS_MAG => CAR_MAG • (95%, 6%) • MUSIC_MAG, COMIC_MAG => CAR_MAG • (100%, 4%) • 음악/주택을 포함한 연관 분석 • 그림 4.30