Download

1 / 49

E N D
1. HST 722 � Speech Motor Control 1
2. HST 722 � Speech Motor Control 2 CNS Speech Lab at Boston University Primary goal is to elucidate the neural processes underlying:
Learning of speech in children
Normal speech in adults
Breakdowns of speech in disorders such as stuttering and apraxia of speech
Methods of investigation include:
Neural network modeling
Functional brain imaging
Motor and auditory psychophysics
These studies are organized around the DIVA model, a neural network model of speech acquisition and production developed in our lab.
3. HST 722 � Speech Motor Control 3
4. HST 722 � Speech Motor Control 4
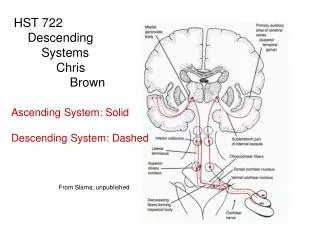
5. HST 722 � Speech Motor Control 5 Boxes in the schematic correspond to maps of neurons; arrows correspond to synaptic projections.
The model controls movements of a �virtual vocal tract�, or articulatory synthesizer. Video shows random movements of the articulators in this synthesizer.
Production of a speech sound in the model starts with activation of a speech sound map cell in left ventral premotor cortex (BA 44/6), which in turn activates feedforward and feedback control subsystems that converge on primary motor cortex.
6. HST 722 � Speech Motor Control 6 Speech Sound Map ? Mirror Neurons Since its inception in 1992, the DIVA model has included a speech sound map that contains cells which are active during both perception and production of a particular speech sound (phoneme or syllable).
During perception, these neurons are necessary to learn an auditory target or goal for the sound, and to a lesser degree somatosensory targets (limited to the visible articulators such as lips).
7. HST 722 � Speech Motor Control 7 Speech Sound Map ? Mirror Neurons After a sound has been learned (described next), activating the speech sound map cells for the sound leads to readout of the learned feedforward commands (�gestures�) and auditory and somatosensory targets for the sound (red arrows at right).
These targets are compared to incoming sensory signals to generate corrective commands if needed (blue).
The overall motor command (purple) combines feedforward and feedback components.
8. HST 722 � Speech Motor Control 8 Learning in the Model � Stage 1 In the first learning stage, the model learns the relationships between motor commands, somatosensory feedback, and auditory feedback.
In particular, the model needs to learn how to transform sensory error signals into corrective motor commands.
This is done with babbling movements of the vocal tract which provide paired sensory and motor signals that can be used to tune these transformations.
9. HST 722 � Speech Motor Control 9 Learning in the Model � Stage 2 (Imitation) The model then needs to learn auditory and somatosensory targets for individual speech sounds, and feedforward motor commands (�gestures�) for these sounds. This is done through an imitation process involving the speech sound map cells.
10. HST 722 � Speech Motor Control 10
11. HST 722 � Speech Motor Control 11
12. HST 722 � Speech Motor Control 12 Top panel:
Spectrogram of target utterance presented to the model.
Remaining panels:
Spectrograms of the model�s first few attempts to produce the utterance.
Note improvement of auditory trajectories with each practice iteration due to improved feedforward commands.
13. HST 722 � Speech Motor Control 13
14. HST 722 � Speech Motor Control 14
15. HST 722 � Speech Motor Control 15 Talk Outline
16. HST 722 � Speech Motor Control 16
17. HST 722 � Speech Motor Control 17
18. HST 722 � Speech Motor Control 18 Prediction: Auditory Error Cells The model hypothesizes an auditory error map in the higher-order auditory cortex of the posterior superior temporal gyrus and planum temporale.
Cells in this map should become active if a subject�s auditory feedback of his/her own speech is perturbed so that it mismatches the subject�s auditory target.
The model also predicts that this auditory error cell activation will give rise to increased activity in motor areas, where corrective articulator commands are generated.
19. HST 722 � Speech Motor Control 19 fMRI Study of Unexpected Auditory Perturbation During Speech To test these predictions, we performed an fMRI study involving 11 subjects in which the first formant frequency (an important acoustic cue for speech) was unexpectedly perturbed upward or downward by 30% in � of the production trials.
The perturbed feedback trials were randomly interspersed with normal feedback trials so the subject could not anticipate the perturbations.
Perturbations were applied using a DSP device developed with colleagues at MIT (Villacorta, Perkell, Guenther, 2004) which feeds the modified speech signal back to the subject in near real-time (~16 ms delay, not noticeable to subject).
Sound before shift:
Sound after shift:
20. HST 722 � Speech Motor Control 20
21. HST 722 � Speech Motor Control 21 => Auditory feedback control is right-lateralized in the frontal cortex.
22. HST 722 � Speech Motor Control 22
23. HST 722 � Speech Motor Control 23 fMRI Study of Unexpected Jaw Perturbation During Speech 13 subjects produced /aCi/ utterances while in the MRI scanner (e.g., �abi�, �ani�, �agi�).
An event-triggered paradigm was used to avoid movement artifacts and scanner noise issues:
On 1 in 7 utterances, a small balloon was rapidly inflated between the teeth during the initial vowel.
The balloon inhibits upward jaw movement for the consonant and final vowel, causing the subject to compensate with larger tongue and/or lip movements.
24. HST 722 � Speech Motor Control 24
25. HST 722 � Speech Motor Control 25 Talk Outline
26. HST 722 � Speech Motor Control 26 Feedforward Control in the Model In addition to activating the feedback control subsystem, activating speech sound map cells also causes the readout of feedforward commands for the sound to be produced.
These commands are encoded in synaptic projections from premotor cortex to primary motor cortex, including both cortico-cortical (blue) and trans-cerebellar (purple) projections.
27. HST 722 � Speech Motor Control 27
28. HST 722 � Speech Motor Control 28 Early in development, the feedforward commands are poorly tuned, so the feedback control subsystem is needed to �correct� the commands.
On each attempt to produce a sound, the feedforward controller incorporates these feedback-based corrections into the feedforward command for the next attempt, resulting in better and better feedforward control with practice.
Tuning Feedforward Commands
29. HST 722 � Speech Motor Control 29 The interactions between the feedforward and feedback control subsystems in the model lead to the following predictions:
If a speaker�s auditory feedback is perturbed consistently over many consecutive productions of a syllable, corrective commands issued by the auditory feedback control subsystem will become incorporated into the feedforward commands for that syllable.
Speakers with better hearing (auditory acuity) will adapt more than speakers with worse hearing.
If the perturbation is then removed, the speaker will show �after-effects� due to these adjustments to the feedforward command.
This was investigated by Villacorta, Perkell, & Guenther (2004).
30. HST 722 � Speech Motor Control 30 Sensorimotor Adaptation Study � F1 Perturbation In each epoch of the adaptation study, the subject read a short list of words involving the vowel �eh� (e.g., �bet�, �peck�).
After a baseline phase of 15 epochs of reading with normal feedback, a shift of F1 was gradually applied to the subject�s auditory feedback during the next 5 epochs.
The shift was then held at the maximum level (30% shift) for 25 epochs.
Finally, feedback was returned to normal in a 20-epoch post-test phase.
The entire experimental session lasted approximately 60-90 minutes.
31. HST 722 � Speech Motor Control 31 Results for 20 subjects shown by lines with standard error bars.
Shaded region is the 95% confidence interval for model simulation results (one simulation per speaker, target region size determined by speaker�s auditory acuity).
32. HST 722 � Speech Motor Control 32 Sensorimotor Adaptation Study Results Sustained auditory perturbation leads to adjustments in feedforward commands for speech in order to cancel out the effects of the perturbation.
Amount of adaptation is correlated to speaker�s auditory acuity: high acuity speakers adapt more completely to the perturbation.
When perturbation is removed, speech only gradually returns to normal values; i.e., there is an after-effect in the first few trials after hearing returns to normal (evidence for feedforward command adaptation).
The model provides a close quantitative fit to these processes.
33. HST 722 � Speech Motor Control 33 Summary The DIVA model elucidates several types of learning in speech acquisition, e.g.:
Learning of relationships between articulations and their acoustic and somatosensory consequences
Learning of auditory targets for speech sounds in the native language from externally presented examples
Learning of feedforward commands for new sounds through practice
The model elucidates the interactions between motor, somatosensory, and auditory areas responsible for speech motor control.
The model spans behavioral and neural levels and makes predictions that are being tested using a variety of experimental techniques.
34. HST 722 � Speech Motor Control 34 Reconciling Gestural and Auditory Views of Speech Production In our view, the �gestural score� is the feedforward component of speech production, stored in the projections from premotor to motor cortex, which consists of an optimized set of motor programs for the most frequently produced phonemes, syllables and syllable strings (in Levelt�s terms, the �syllabary�).
These gestural scores are shaped by auditory experience in order to adhere to acceptable auditory bounds of speech sounds in the native language(s).
They are supplemented by auditory and somatosensory feedback control systems that constantly adjust the gestures when they detect errors in performance, e.g. due to growth of the vocal tract, addition of a false palate, or auditory feedback perturbation.
35. HST 722 � Speech Motor Control 35
36. HST 722 � Speech Motor Control 36 Simulating a Hemodynamic Response from the Model Model cell activities during simulations of speech are convolved with an idealized hemodynamic response function, generated using default settings of the function �spm_hrf� from the SPM toolbox. This function was designed to characterize the transformation from cell activity to hemodynamic response in the brain.
A brain volume is then constructed with the appropriate hemodynamic response values at each position and smoothed with a Gaussian kernel (FWHM=12mm). This smoothing process approximates the smoothing carried out during standard SPM analysis of human subject fMRI data.
The resultant volume is then rendered using routines from the SPM toolbox.
37. HST 722 � Speech Motor Control 37 An event-triggered paradigm was used to avoid movement artifacts and scanner noise issues:
38. HST 722 � Speech Motor Control 38
39. HST 722 � Speech Motor Control 39 Brain regions active during cued production of 3-syllable strings
40. HST 722 � Speech Motor Control 40
41. HST 722 � Speech Motor Control 41
42. HST 722 � Speech Motor Control 42
43. HST 722 � Speech Motor Control 43
44. HST 722 � Speech Motor Control 44 Motor Equivalence in American English /r/ Production It has long been known that the American English phoneme /r/ is produced with a large amount of articulatory variability, both within a subject and between subjects. Delattre and Freeman (1968):
45. HST 722 � Speech Motor Control 45 Despite large articulatory variability, the key acoustic cue for /r/ remains relatively stable across phonetic contexts. Boyce and Espy-Wilson (1997):
46. HST 722 � Speech Motor Control 46 Motor Equivalence in the DIVA Model Model�s use of auditory target for /r/ and directional mapping between auditory and articulatory spaces leads to different articulatory gestures, and different vocal tract shapes, for /r/ depending on phonetic context:
47. HST 722 � Speech Motor Control 47 Sketch of hypothesized trading relations for /r/:
Acoustic effect of the larger front cavity (blue) is compensated by the effect of the longer and narrower constriction (red).
This yields similar acoustics for �bunched� (red) and �retroflex� (blue) tongue configurations for /r/ (Stevens, 1998; Boyce & Espy-Wilson, 1997).
All seven subjects in the EMMA study utilized similar trading relations (Guenther et al., 1999).
48. HST 722 � Speech Motor Control 48 Building Speaker-Specific Vocal Tract Models from MRI Images
49. HST 722 � Speech Motor Control 49
50. HST 722 � Speech Motor Control 50