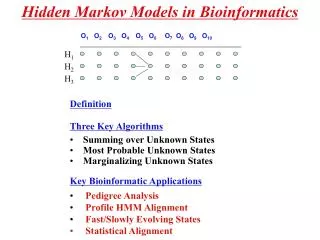
Download
1 / 28
280 likes | 549 Views
Applying Hidden Markov Models to Bioinformatics. Conor Buckley. Outline. What are Hidden Markov Models? Why are they a good tool for Bioinformatics? Applications in Bioinformatics. History of Hidden Markov Models.

E N D
Applying Hidden Markov Models to Bioinformatics Conor Buckley
Outline • What are Hidden Markov Models? • Why are they a good tool for Bioinformatics? • Applications in Bioinformatics
History of Hidden Markov Models • HMM were first described in a series of statistical papers by Leonard E. Baum and other authors in the second half of the 1960s. One of the first applications of HMMs was speech recogniation, starting in the mid-1970s. They are commonly used in speech recognition systems to help to determine the words represented by the sound wave forms captured • In the second half of the 1980s, HMMs began to be applied to the analysis of biological sequences, in particular DNA. • Since then, they have become ubiquitous in bioinformatics Source: http://en.wikipedia.org/wiki/Hidden_Markov_model#History
What are Hidden Markov Models? • HMM: A formal foundation for making probabilistic models of linear sequence 'labeling' problems. • They provide a conceptual toolkit for building complex models just by drawing an intuitive picture. Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
What are Hidden Markov Models? • Machine learning approach in bioinformatics • Machine learning algorithms are presented with training data, which are used to derive important insights about the (often hidden) parameters. • Once an algorithm has been trained, it can apply these insights to the analysis of a test sample • As the amount of training data increases, the accuracy of the machine learning algorithm typically increasess as well. Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
Hidden Markov Models • Has N states, called S1, S2, ... Sn • There are discrete timesteps, t=0, t=1 N = 3 t = 0 S2 S1 S3 Source: http://www.autonlab.org/tutorials/hmm.html
Hidden Markov Models • Has N states, called S1, S2, ... Sn • There are discrete timesteps, t=0, t=1 • For each timestep, the system is in exactly one of the available states. N = 3 t = 0 S2 S1 S3
Hidden Markov Models S1 S2 S3 • Bayesian network with time slices Bayesian Network Image: http://en.wikipedia.org/wiki/File:Hmm_temporal_bayesian_net.svg
A Markov Chain • Bayes'Theory • (statistics) a theorem describing how the conditional probability of a set of possible causes for a given observed event can be computed from knowledge of the probability of each cause and the conditional probability of the outcome of each cause • - http://wordnetweb.princeton.edu/perl/webwn?s=bayes%27%20theorem
Building a Markov Chain Concrete Example • Two friends, Alice and Bob, who live far apart from each other and who talk together daily over the telephone about what they did that day. • Bob is only interested in three activities: walking in the park, shopping, and cleaning his apartment. • The choice of what to do is determined exclusively by the weather on a given day. • Alice has no definite information about the weather where Bob lives, but she knows general trends. • Based on what Bob tells her he did each day, Alice tries to guess what the weather must have been like. • Alice believes that the weather operates as a discrete Markov chain. There are two states, "Rainy" and "Sunny", but she cannot observe them directly, that is, they are hidden from her. • On each day, there is a certain chance that Bob will perform one of the following activities, depending on the weather: "walk", "shop", or "clean". Since Bob tells Alice about his activities, those are the observations. Source: Wikipedia.org
What now? * Find out the most probable output sequence • Vertibi's algorithm • Dynamic programming algorithm for finding the most likely sequence of hidden states – called the Vertibi path – that results in a sequence of observed events.
Vertibi Results http://pcarvalho.com/forward_viterbi/
Bioinformatics Example • Assume we are given a DNA sequence that begins in an exon, contains one 5' splice site and ends in an intron • Identify where the switch from exon to intron occurs • Where is the splice site?? Sourece: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
Bioinformatics Example • In order for us to guess, the sequences of exons, splice sites and introns must have different statistical properties. • Let's say... • Exons have a uniform base composition on average • A/C/T/G: 25% for each base • Introns are A/T rich • A/T: 40% for each • C/G: 10% for each • 5' Splice site consensus nucleotide is almost always a G... • G: 95% • A: 5% Sourece: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
Bioinformatics Example We can build an Hidden Markov Model • We have three states • "E" for Exon • "5" for 5' SS • "I" for Intron • Each State has its own emission probabilities which model the base composition of exons, introns and consensus G at the 5'SS • Each state also has transition probabilities (arrows) Sourece: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
HMM: A Bioinformatics Visual • We can use HMMs to generate a sequence • When we visit a state, we emit a nucleotide bases on the emission probability distribution • We also choose a state to visit next according to the state's transition probability distribution. • We generate two strings of information • Observed Sequence • Underlying State Path Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
HMM: A Bioinformatics Visual • The state path is a Markov Chain • Since we're only given the observed sequence, this underlying state path is a hidden Markov Chain Therefore... • We can apply Bayesian Probability Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
HMM: A Bioinformatics Visual S – Observed sequence π – State Path Θ – Parameters The probability P(S, π|HMM, Θ) is the product of all emission probabilites and transition probilities. Lets look at an example... Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
HMM: A Bioinformatics Visual • There are 27 transitions and 26 emissions. • Multiply all 53 probabilities together (and take the log, since these are small numbers) and you'll calculate log P(S, π|HMM, Θ) = -41.22 Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
HMM: A Bioinformatics Visual • The model parameters and overall sequences scores are all probabilities • Therefore we can use Bayesian probability theory to manipulate these numbers in standard, powerful ways, including optimizing parameters and interpreting the signifigance of scores. Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
HMM: A Bioinformatics Visual Posterior Decoding: • An alternative state path where the SS falls on the 6th G instead of the 5th (log probabilities of -41.71 versus -41.22) • How confident are we that the fifth G is the right choice? Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
HMM: A Bioinformatics Visual We can calculate our confidence directly. • The probability that nucleotide i was emitted by state k is the sum of the probabilities of all the states paths use state k to generate i, normalized by the sum over all possible state paths Result: We get a probability of 46% that the best-scoring fifth G is correct and 28% that the sixth G position is correct. Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
Further Possibilites • The toy-model provided by the article is a simple example • But we can go further, we could add a more realistic consensus GTRAGT at the 5' splice site • We could put a row of six HMM states in place of '5' state to model a six-base ungapped consensus motif • Possibilities are not limited
The catch • HMM don't deal well with correlations between nucleotides • Because they assume that each emitted nucleotide depends only on one underlying state. • Example of bad use for HMM: • Conserved RNA base pairs which induce long-range pairwise correlations; one position might be any nucleotide but the base-paired partner must be complementary. • An HMM state path has no way of 'remembering' what a distant state generated. Source: http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1
Credits • http://www.nature.com/nbt/journal/v22/n10/full/nbt1004-1315.html#B1 • http://en.wikipedia.org/wiki/Viterbi_algorithm • http://en.wikipedia.org/wiki/Hidden_Markov_model • http://en.wikipedia.org/wiki/Bayesian_network • http://www.daimi.au.dk/~bromille/PHM/Storm.pdf