Download

1 / 21
210 likes | 307 Views
Discussing time hierarchies with advice and the generic time hierarchy theorem for probabilistic algorithms. Examining the impact of advice length, probabilistic algorithms, and diagonalization failure in separating algorithmic classes.

E N D
Time Hierarchieswith One Bit of Advice Konstantin Pervyshev Steklov Mathematics Institute, St. Petersburg, Russia joint work with Dieter van Melkebeek
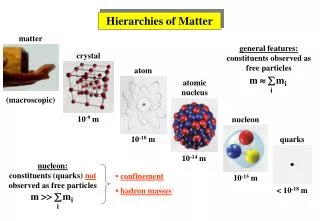
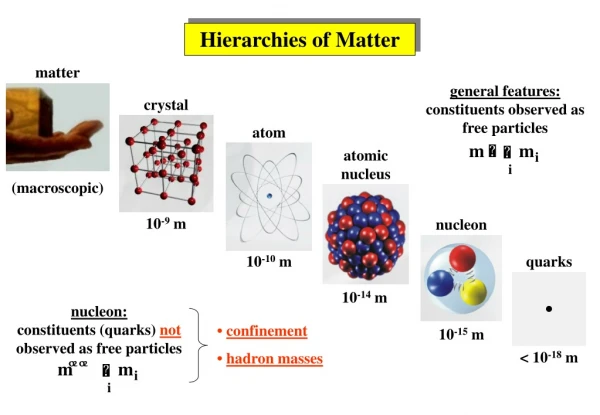
O(n3) O(n2) Time Hierarchy An open question for probabilistic algorithms: is there a time hierarchy ? O(n) (we still can’t disprove this)
Our result • Previous results • [Barak 02] uses a modified notion of algorithm • (algorithms with small advice) • Under the modified notion of algorithm, a time hierarchy for the probabilistic algorithms exists • Our result • Under the same modified notion of algorithm, a time hierarchy exists for any class of algorithms • various classes of probabilistic algorithms • Arthur-Merlin and Merlin-Arthur games, other kinds of IP • NP ∩ co-NP
Outline • Why standard techniques don’t work • Where advice helps • How to prove the generic time hierarchy
Diagonalization • To separate deterministic time na+e from time na, consider a machine M such that • M(k) := not Nk(k), where na steps of Nk are simulated • M runs in time na+ • M recognizes some languages L • L can’t be recognized in time na • (!) deterministic algorithms are recursively enumerable
Probabilistic Algortithmsand Diagonalization • Probabilistic Algorithms • Probabilistic Turing machines that satisfy some condition on the error probability • Two-sided error (BPP) • Pr[M(x) = 1] > 2/3 or Pr[M(x) = 0] > 2/3 • “machine M is good on input x” • “machine M is good at length n” • Need to enumerate only good machines • M(k) := not Nk(k) • Pr[Nk(k) = 1] = 1/2 => Pr[M(k) = 1] = 1/2 • It’s not possible
More Failures • Various classes of probabilistic algorithms • bounded probability of error • BPP – two-sided error • RR – one-sided error • ZPP – zero-sided error • NP ∩ co-NP • two machines solve the same language • Generally speaking, semantic classes • Diagonalization fails • Nk(k) is bad => M(k) is bad • To overcome this, M needs advice on whether Nk is good
Algorithms with Advice • Turing machine M on input x of length n is provided with • some advice a(n) of length l(n) • Advice is the same for every input of length n • Depending on the advice provided, • M may recognize several languages • M may satisfy the promise or not • Advice of length 1 bit • helps with time hierarchies
Time Hierarchies with Advice • A time hierarchy exists for probabilistic algorithms with advice of length • O(log log n) bits – [Barak 02] • 1 bit – [Fortnow, Santhanam 04] • Time hierarchy for any class of algorithms with advice of length • O(log n * log log n) bits – [Fortnow, Santhanam, Trevisan 05] • 1 bit – our result
Generic Time Hierarchy • To separate na+e from na, it’s sufficient to prove that • for any 1 ≤ a, there exists a language L solvable in probabilistic polynomial timewith 1 bit of advice • machine M with advice a(n) not solvable in probabilistic time na with 1 bit of advice • any machine Nk with any advice b(n)
A Failed Approach • Construct M with advice a(n) so that • for some inputsx(0)and x(1)of the same length n M(x(0),a(n)) := not Nk(x(0),0) M(x(1),a(n)) := not Nk(x(1),1) • Both Nk(x,0) and Nk(x,1) may be bad => M needs 2 bits of advice in order to diagonalize safely
Another Failed Approach • M can safely simulate Nk via deterministic simulation • needs exponentially more time • To get exponentially more time, we use delayed diagonalization
A Step of Delayed Diagonalization y(0) Advice on whether N/0 is good on x’s N/0 is bad N/1 is good M(y(0)) = “no” x(0) x(1) z(1) Advice on whether N/1 is good on x’s M(z(1)) = N(x(1),1)
Tree-Like Delayed Diagonalization y(00,01) N/0 is bad N/1 is good M(y(00)) = “no” M(y(01)) = “no” x(00-11) N/0 is good N/1 is bad v(01) z(10,11) M(v(01)) = N(z(01),0) w(11) M(z(01)) = N(x(01),1) M(z(11)) = N(x(11),1) M(w(11)) = “no”
Assume for some advice b(n), N is good and solves the same language as M Then N(v(s),b(|v|)) = M(v(s) ,a(|v|)) = N(z(s),b(|z|)) = M(z(s) ,a(|z|)) = N(x(s),b(|x|)) = M(x(s) ,a(|x|)) Therefore, N(v(s) ,b(|v|)) = M(x(s),a(|x|)) for some s So let M(x(s),a(|x|)) := not N(v(s),b(|v|)) this can be done deterministically thus a contradiction x(s) v(s) z(s) Towards a Contradiction |x| ~ 2|v|a
We need parent’s length is polynomial in children’s length so that M runs in poly-time for any leaf v, roots length is greater than 2|v|a so that M can deterministically simulate N at leaves It’s possible to satisfy these conditions QED x(s) v(s) z(s) Choice of the Input Lengths
Summary • A time hierarchy exists for virtually any kind of algorithms with one bit of advice • The probabilistic time hierarchy with advice is a property of algorithms with advice
Thank you! Dieter van Melkebeek, Konstantin Pervyshev “A Generic Time Hierarchy for Semantic Models with One Bit of Advice” (CCC’06)
Generic Time Hierarchy • Theorem • for any 1 ≤ a < b, there exists a language L solvable in probabilistic time nb with 1 bit of advice not solvable in probabilistic time na with 1 bit of advice • Only basic properties of algorithms are needed • Approach • Construct probabilistic M with 1-bit advice a(n) that • works in time nb • is good • Prove that for any probabilistic N with any 1-bit advice b(n) that • works in time na • is good • There exists x such that M(x,a(|x|)) ≠ N(x,b(|x|))
Non-Uniform World • Previous results • [Barak02, FS04, FST05] a time hierarchy exists for 1 bit non-uniform probabilistic algorithms with two- and one-sided error • Our result • a time hierarchy exists for any classof 1 bit non-uniform algorithms • various classes of probabilistic algorithms • Arthur-Merlin and Merlin-Arthur games, other kinds of IP • NP ∩ co-NP
Non-deterministic time M can copy (simulate) N M can’t negate N Our case M can copy N(x,b(|x|)) We have no idea of how to negate N trivially Delayed diagonalization y(0) x(0) x(1) z(1) Recall Non-deterministicTime Hierarchy