Download

1 / 54
540 likes | 626 Views
Learn about types of network data, calculation techniques, and software applications for network analysis in the context of innovation and alliances. Explore ego-centered vs. complete network analysis approaches.

E N D
Social NetworksLecture 4:Collection of Network Data&Calculation of Network CharacteristicsU. Matzat
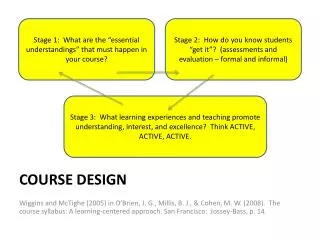
Course design • Aim: knowledge about concepts in network theory, and being able to apply them, in particular in a context of innovation and alliances • Introduction: what are they, why important … • Small world networks • Four basic network arguments • Kinds of network data (collection) & measurement • Business networks • Assignment 1
Course outlook - today 4. Methods • Kinds of network data: collection (Part I) • Typical network concepts: calculation, UCINET software, visualisation (Part II) Later: Assignments - complete network analysis - ego-centered network analysis
Part 1 – Collection of Network Data • in traditional surveys a random sample of units (e.g. managers) is interviewed • properties of individuals are correlated to analyze some phenomena (e.g., correlation of age with openness for new ideas) • focus on distributions of qualities of the individuals, not on their relations • traditional assumption: sampled units (e.g., managers) are independent of each other and not related to each other • inappropriate for SNA • traditional survey instruments had to be adjusted & new ones had to be developed
Collection of Network Data:two main approaches within SNA 1.) ego-centered network analysis: network (of a specific type) from the perspective of a single actor (ego) 2.) complete network analysis: the relations (of a specific type) between all units of a social system are analyzed • the first approach rests on an extension of traditional survey instruments • can be combined with random sampling • statistical data analyses possible with standard software (e.g., SPSS) • the second approach is new • (usually) cannot be combined with random sampling • quantitative case study • statistical data analyses with specialized software (e.g., UCINET)
Ego-centered network data random sample: • selection of units (e.g. individuals) out of a population • inclusion of one individual does not influence whether another one is also included • relationship between units is no criterion of selection • respondent (ego) mentions for a relationship of a certain type (e.g. friendship relation) other individuals (alteri) with whom he is related • usually the alteri are not within the sample • respondent gives additional information about -some characteristics of the alteri (age etc.) -the relations between the alteri crucial: specialized items for the generation of alteri: name-generator
Ego-centered network data: the generation of data via name generators name generator for reconstruction of friendship networks in a general population: first step: • "From time to time people discuss questions and personal problems that keep them busy with others. When you think about the last 6 months - who are the persons with whom you did discuss such questions that are of personal importance for you. Please mention only the first name of the individuals." • [If respondent mentions less than five names, ask once more: "Anybody else? " Write down only the first five names.] second step:-characterization of alteri (gender, age, etc) and relation between ego and alteri (e.g., strength of relation) third step: -characterization of relation between the different pairs of alter (e.g., strength of relation)
Ego-centered network data: example: reconstruction of university-company relationships • random sample of university researchers • question of interest: how does a researcher’s network look like that brings him into contact with business representatives for collaboration? • reconstruction of four parts of the network from the point of view of the researcher: • within university- within own faculty • within university- outside own faculty • outside university – within business world • [outside university – personal friends, acquaintances etc.]
example: reconstruction of university-company relationships Questionnaire items Let us suppose that you are convinced that you have an idea, a product or something similar, in which collaboration with a business firm is a sensible and reasonable option. Do you have any contacts that could be of substantial value for bringing you in touch with a business firm? 0 yes 0 no (continue with question xx)
example: reconstruction of university-company relationships From which of the employees within your faculty do you expect that they can make a substantial contribution with respect to getting you in contact with business firms that might become partners? Mention the most important persons, at most four. From which of the employees outside your faculty but within your university do you expect that they can make a substantial contribution with respect to getting you in contact with business firms that might become partners? Mention the most important persons, at most four.
Example (cont) You mentioned up to 16 names of persons. Please write down the name of the first person mentioned, the second person mentioned, the third person mentioned, etc, until every name is on this list. Make sure that each name is mentioned once and only once. Please carefully check this list. Are any persons missing of whom you feel that – given the questions – they should be included in this list? Persons who are crucial in getting cooperation between you and a business partner going? If yes, please add these persons to the list (at most two extra persons) and briefly describe your relation to this person.
Example (cont): second step We would like to know how strong your relation with the persons in this list is. A strong relation would be a relation with frequent contact and with a regular exchange of information.
Example (cont): third step Finally, we would like to ask you about the relations between the listed persons in your network. Start with the first person in the list. Consider the relation between this person and the other persons in the list. Choose between: S: strong relation D: distant relation 0: no relation Fill out an X if you cannot judge the relationship.
ego-centered network data: data matrix example: name generator for three best friends (of two respondents) gender age friend 1 existing? friend 2 existing? friend 3 existing? tie strength 1 tie strength 1-2 gender friend 1 respondent 11 30 1 1 1 0.8 1 1 respondent 22 40 1 1 0 0.7 0 2 ………… ………… …………
ego-centered network data: data matrix • standard data matrix that can be analyzed with the conventional techniques and conventional software (e.g., SPSS, STATA etc) • but special type of variables of the data set • some variables describe the respondent • some variables describe the respondent's contacts • some variables describe the relation between the respondent and his contacts • some variables describe relations between members of the respondent's (primary) network • these variables can be used to construct other variables that describe properties of the respondent’s network (size, density etc) • you have to construct these variables: e.g. via “TRANSFORM – COMPUTE” in SPSS
ego-centered network data • ego-centered network data necessary for testing of typical network theories • Example: structural holes hypothesis (ego=company) • “Innovating companies tend to profit more from new product ideas the more structural holes they have in their collaboration networks with other companies.“ • a test of this hypothesis is impossible with traditional surveys of companies
ego-centered network data: Strengths and weaknesses + random sampling possible + generalization to a well-defined population possible + for the social scientist easy to use techniques of data analysis - restriction to those parts of the network that are directly visible to the respondent: the primary network; other characteristics of the network are not taken into account
Complete network data • example: network of informal communication between employees of a project group consisting of 5 persons: • Mr Smith, Mr Jackson, Mr. White, Mrs Moneypenny, Mrs Brown • questionnaire item for Mr Smith: • "With whom of the following persons do you now and then chat during a normal working day?" Do you talk with… • Mr. Jackson 0 yes0 no Mr. White 0 yes 0 noMrs Moneypenny 0 yes 0 no Mrs Brown 0 yes 0 no • question is presented to all members of the project group • you need to have a complete list of the names of all units (e.g. individuals) of the social system (e.g. project group) beforehand
Complete network data: sociomatrix • the data matrix is different from the traditional data matrix • every cell ij in the matrix provides information about the relation between units i and j ("from row i to column j") • relation can be symmetric or asymmetric, valued or dichotomous
Complete network data: • collection of complete network data impossible for large random samples • necessary for many hypotheses that make predictions about structural effects:"In groups with a high network density the diffusion of innovations takes place more quickly than in groups with a low density." • hypothesis can only be tested with complete network data • data matrix of complete network data cannot be analyzed with the conventional data analysis techniques • specialized software that offers special techniques is needed (e.g., UCINET) • you can calculate network characteristics of actors and of the whole network • you can calculate network characteristics (within UCINET) for actors that can be exported and then combined with other data (e.g., SPSS data)
Complete network data: Strengths and weaknesses + all aspects of the structure of relationships between all actors in a social system are taken into account • no random sampling, therefore no generalizations are possible, rather: quantitative case study approach - other techniques of data analysis necessary
Part II: Calculation & visualisation of network concepts (1): in- and outdegree For complete, valued, directed network data with N actors, and relations from actor i to actor j valued as rij , varying between 0 and R. Centrality and power: outdegree (or: outdegree centrality) For each actor j: the number of (valued) outgoing relations, relative to the maximum possible (valued) outgoing relations. OUTDEGREE(i) = j rij / N.R Centrality and power: indegree (or: indegree centrality) same, but now consider only the incoming relations NOTE1: this is a locally defined measure, that is, a measure that is defined for each actor separately NOTE2: this gives rise to several global network measures, such as (in/out)degree variance NOTE3: if your network is not directed, indegree and outdegree are the same and called degree NOTE4: these measures can be constructed in SPSS; no need for special purpose software. Try this yourself!
Network measures (2): number of ties of a certain quality 1 = I do not know who this is 2 = I know who it is, but never talked to him/her 3 = I have spoken to this person once or twice 4 = I talk to this person regularly 5 = I talk to this person often Number of ties: For each network or for each actor, the number of ties above a certain threshold (say, all ties with a value above 3) Number of weak ties (remember Mark Granovetter?): For each network or for each actor, the number of ties above and below a certain threshold (say, only ties with values 2 and 3) Try creating this one yourself in SPSS (try using ‘recode’)
Network measures (3): closeness Centrality and power again: closeness = Average distance to all others in the network Note: a shortest path from i to j is called a “geodesic” Define distance Dij from i to j as: * Minimum value of a path from i to j For every actor i, average distance = j Dij / N NOTE: THIS IS NOT EASY TO DO ANYMORE IN SPSS!
Network measures (4): the most common global network property Density (J. Coleman: “Dense networks provide social capital.”) For each network: the number of (valued) relations, relative to the maximum possible number of (valued) relations. = i,j rij / N (N-1) R (directed, valued ties) NOTE: normally only of use if your data consist of multiple networks (alliance networks in different sectors or countries / friendship networks in school classes / …) NOTE: this is still doable in SPSS
Network measures (5): Subgroup Models (Cohesion) • aim: description of cohesive subgroups within the larger network • general and common idea: a subgroup has a certain degree of cohesiveness (direct ties, strong ties) • can also be used to make predictions about the diffusion of innovations according to the cohesion model (which pairs of actors influence each other?) • which companies constitute a subgroup within the network? • which companies are in many subgroups? • how many subgroups do exist?
Subgroups: Some general terminology you need to know….. reachability • if a path exists between 2 nodes then these nodes are called reachable • path length • number of lines of a path (dichotomous data) • example: path length 4213 = 3 geodesic distance between two nodes • there can be more than one path between two nodes, the different paths can have different lengths • d(i,j)=length of the shortest path between two nodes i and j • example: 4213 = 3, d(i,j)=3 if there exists no shorter path between i and j • d(i,j)= if i,j are not reachable 8
Subgroups: Terminology.... completeness of a graph • a graph is complete if all pairs of nodes (i,j) are reachable with d(i,j)=1 connectedness • a graph is connected if for every pair (i,j) d(i,j)< subgraphs • a subgraph Gs consists of a subset NsN and its lines Ls L that connect all {i,j} Ns Maximality • a subgraph is maximal with respect to some property (e.g., maximal with regard to completeness) if that property holds for the subgraph, but does no longer hold if any additional node and the lines incident with the node are added 8
Subgroups example: maximal completeness 5 7 maximal complete subgraph Gs Ns={1,2,3,4,5} and the ties between them 1 6 2 4 3
Subgroup Definitions for undirected dichotomous ties Cliques a cliques is a maximal complete subgraph that consists of at least three nodes 2 7 1 3 4 5 6 Which cliques? {1,2,3}, {1,3,5}, {3,4,5,6} cliques can overlap, a clique can not be part of a larger clique because of the maximality conditionimpossible to calculate with SPSS!
This was covered in the 3rd lecture Network measures (6): Structural holes Ron Burt: “Structural holes create value” A 1 B 7 3 2 James Robert 4 5 6 • Robert will do better than • James, because of: • informational benefits • “tertius gaudens” (entrepreneur) • autonomy 8 C
Network measures (6): Structural holes • Burt, R.S. (1995) • NOTE: structural holes can be defined on ego-networks! Burt splits his structural holes measure in four separate ones: • [1] effective size • [2] efficiency (= effective size / total size) • [3] constraint (degree to which ego invests in alters who themselves invest in other alters of ego) • [4] hierarchy (adjustment of constraint, dealing with the degree to which constraint on ego is concentrated in a single actor)
A B F E G D C Structural holes: Effective size & efficiency We calculate effective size and efficiency for actor G (note: because this is an ego-network, all would be different if we would have chosen, for instance, actor A) Or, the same but a bit easier: Effective size = size - average degree of ego’s alters in ego’s network (excluding ties to ego). Here: 6 - {3 (A) + 2(B) + 0(C) + 1(D) + 1(E) + 1(F)}/6 = 6 - 1.33 = 4.67
A B C D E F G A 0.25 0 0 0.25 0.25 0.25 B 0.33 0.0 0.33 0 0 0.33 A B C 0 0 0 0 0 1.00 F D 0 0.50 0 0 0 0.50 E G D E 0.50 0 0 0 0 0.50 F 0.50 0 0 0 0 0.50 C G 0.17 0.17 0.17 0.17 0.17 0.17 Defining constraint: actors must divide their attention The assumption is that actors can only invest a certain amount of time and energy in their contacts, and must divide the available time and energy across contacts. If not explicitly measured, we assume all contacts are invested in equally.
Constraint Actor i is constrained in his relation with j to the extent that: [a] i invests in another contact q who … [b] invests in i’s contact j Total investment of i in j = Pij + q (piq pqj) “Since this also equals i’s lack of structural holes, constraint of i in j is taken to equal” ( Pij + q (piq pqj) )2 q piq pqj i pij j
Calculating constraint using matrices (1) c1 c2 c3 c4 c5 c6 c7 r1 0 .25 0 0 .25 .25 .25 r2 .333 0 0 .333 0 0 .333 r3 0 0 0 0 0 0 1 r4 0 .5 0 0 0 0 .5 r5 .5 0 0 0 0 0 .5 r6 .5 0 0 0 0 0 .5 r7 .17 .17 .17 .17 .17 .17 0 Adjacency matrix P = (see two slides ago) all investment from i in j in 1 step c1 c2 c3 c4 c5 c6 c7 r1 .37575 .0425 .0425 .12575 .0425 .0425 .33325 r2 .05661 .30636 .05661 .05661 .13986 .13986 .24975 r3 .17 .17 .17 .17 .17 .17 0 r4 .2515 .085 .085 .2515 .085 .085 .1665 r5 .085 .21 .085 .085 .21 .21 .125 r6 .085 .21 .085 .085 .21 .21 .125 r7 .22661 .1275 0 .05661 .0425 .0425 .52411 Matrix product P2 = P*P = all investments from i in j in 2 steps
Calculating constraint using matrices (2) c1 c2 c3 c4 c5 c6 c7 r1 .37 .29 .04 .12 .29 .29 .58 r2 .38 .30 .05 .38 .13 .13 .58 r3 .17 .17 .17 .17 .17 .17 1 R4 .25 .58 .08 .25 .08 .08 .66 r5 .58 .21 .08 .08 .21 .21 .62 r6 .58 .21 .08 .08 .21 .21 .62 r7 .39 .29 .17 .22 .21 .21 .52 P + P2 = All investments from i to j in 1 or 2 steps Pij + q (piq pqj) (0.666)2 = 0.444 Etc … c1 c2 c3 c4 c5 c6 c7 r1 .141 .085 .002 .015 .085 .085 .340 r2 .151 .093 .003 .151 .019 .019 .339 r3 .028 .028 .028 .028 .028 .028 1 r4 .063 .342 .007 .063 .007 .007 .444 r5 .342 .044 .007 .007 .044 .044 .390 r6 .342 .044 .007 .007 .044 .044 .390 r7 .157 .088 .028 .051 .045 .045 .274 Hadamard matrix product (P+P2)2h = P+P2 squared element wise Constraint(i,j) can be read from this matrix
Calculating constraint using matrices (3) Total constraint for actor i = sum of all constraints Cij with ji c1 c2 c3 c4 c5 c6 c7 r1 .141 .085 .002 .015 .085 .085 .340 r2 .151 .093 .003 .151 .019 .019 .339 r3 .028 .028 .028 .028 .028 .028 1 r4 .063 .342 .007 .063 .007 .007 .444 r5 .342 .044 .007 .007 .044 .044 .390 r6 .342 .044 .007 .007 .044 .044 .390 r7 .157 .088 .028 .051 .045 .045 .274 = 0.755 <- Constraint(1) = 0.779 <- Constraint(2) = 1.173 <- Constraint(3) = 0.934 <- Constraint(4) = 0.879 <- Constraint(5) = 0.879 <- Constraint(6) = 0.691 <- Constraint(7)
Hierarchy • = degree to which constraint is concentrated in a single actor • Cij = constraint from j on i (as on previous pages) • N = number of contacts in i’s network • C = sum of constraints across all N relationships • Hierarchy (i) • Minimum = 0 (all i’s constraints are the same) • Maximum = 1 (all i’s constraint is concentrated in a single contact)