Balancing Performance and Reliability in Couchbase: Insights on Fault Tolerance and Data Recovery
This document explores the interplay between performance and reliability in Couchbase, emphasizing fault tolerance and recoverability. It delves into the nuances of write responses, replication, and queue management to disk and to replicas within clusters. Key questions regarding the support for synchronous writes, local vs. remote data center replication, and the related performance impacts are addressed. The discussion highlights the implications of data loss during node failures and explores strategies to enhance both performance and reliability for applications relying on Couchbase Server.

Balancing Performance and Reliability in Couchbase: Insights on Fault Tolerance and Data Recovery
E N D
Presentation Transcript
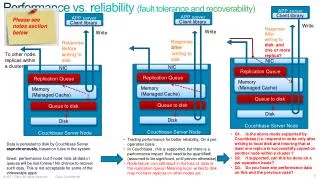
Performance vs. reliability (fault tolerance and recoverability) APP server APP server Client library APP server Client library Client library Write Response After writing to disk and one or more replica? Write Write Response After writing to disk Response Before writing to disk To other node. replicas within a cluster NIC NIC NIC Replication Queue Replication Queue Replication Queue Memory (Managed Cache) Memory (Managed Cache) Memory (Managed Cache) Queue to disk Queue to disk Queue to disk Disk Disk Disk Couchbase Server Node Please see notes section below Couchbase Server Node Couchbase Server Node • Q1. Is the above mode supported by Couchbase (i.e. respond to write only after writing to local disk and insuring that at least one replica is successfully copied on another node within a cluster ? • Q2. If supported, can this be done on a per operation basis? • Q3. Do you have any performance data on this and the previous case? • Trading performance for better reliability. On a per-operation basis . • In Couchbase , this is supported, but there is a performance impact that need to be quantified! (assumed to be significant, until proven otherwise) • Node failure, can still result in the loss of data in the replication queue! Meaning local writes to disk may not have replicas on other nodes yet. Data is persisted to disk by Couchbase Server asynchronously, based on rules in the system. Great performance, but if node fails all data in queues will be lost forever! No chance to recover such data. This is not acceptable for some of the videoscape apps
Replication vsPersistance 2 • Replication allows us to block the write while a node persists that write to the memcached layer of 2 other nodes. This is typically a very quick operation and it means we can return control back the app server near immediately instead of waiting on a write to disk App Server Server 2 2 Managed Cache Server 3 Server 1 2 2 Replication Queue Managed Cache Managed Cache Replication Queue Replication Queue Replication Queue Disk Queue Replication Queue Replication Queue Disk Queue Disk Queue Disk Disk Disk
XDCR: Cross Data Center Replication APP server Client library Write • Q4. Is this mode supported by Couchbase (i.e. respond to the client only after the replica is successfully copied on a remote datacenter node/cluster? Response After writing replica to remote DC? To other node. replicas within a cluster NIC Replication Queue • When are the replicas to other DCs put in the XDCR queue? • Based on the user manual, this is done after writing to local disk! This will obviously add major latencies. • Q5. Is there another option to accelerate this as is the case of local replicas? my understanding is that when the “replication queue” is used for local replications, couchbase puts the data in the replication queue before writing to the disk. Is this correct? Why is this different for the “XDCR queue” case, i.e. write to disk first? Memory (Managed Cache) Queue to disk NIC Disk Please see notes section below Replicas to other DCs XDCR Queue Couchbase Server Node
XDCR: Cross Data Center Replication • Q4. Is this mode supported by Couchbase (i.e. respond to the client only after the replica is successfully copied on a remote datacenter node/cluster? • As a workaround from the application side – the write operation can be overloaded so that before it returns control to the app it does 2 gets. One against the current cluster and one against the remote cluster for the item that was written to determine when that write has persisted to the remote cluster.(data center write) – see pseduo-code in notes • We will support synchronous writes to a remote datacenter from the client side in the 2.0.1 release of Couchbase Server – available Q1 2013 • Lastly, XDCR is only necessary to span AWS Regions, a Couchbase cluster without XDCR configured can span AWS zones without issue. • Q5. Is there another option to accelerate this as is the case of local replicas? my understanding is that when the “replication queue” is used for local replications, Couchbase puts the data in the replication queue before writing to the disk. Is this correct? Why is this different for the “XDCR queue” case, i.e. write to disk first? • XDCR replication to a remote DC is built on a different technology from the in-memory intra-cluster replication. XDCR is done along with writing data to disk so that it is more efficient. Since the flusher that writes to disk, de-dups data, that is only write the last mutation for the document it is updating on disk, XDCR can benefit from this. This is particularly helpful for write heavy / update heavy workloads. The XDCR queue sends less data over the wire and hence is more efficient. • Lastly – we are also looking at a prioritized disk write queue as a roadmap item for 2013. This feature could be used to accelerate a writes persistence to disk for the purposes of reducing latencies for Indexes and XDCR. • Q6. – per command Couchbase Server Node
Rack-aware replication? Data Center APP server Rack #n Rack #1 Rack #2 Client library Write File-1 Couch node3 Couch node1 Couch node2 Couch node4 Couch node5 File-1 Replica-1 Couch node6 Couch node7 File-1 Replica-2 Please see notes section below • Q6. Can couchbase support rack-aware replication (as in Cassandra)? • If we can’t control where the replicas are placed, a rack failure could loose all replicas (i.e. docs become unavailable until the rack recovers)! • Q7. How does couchbase deal with that today? We need at least one of the replicas to be on a different rack. • Note that in actual deployments we can’t always assume that Couchbase nodes will be guaranteed to be placed in different racks. • See the following link for AWS/Hadoop use case for example:http://bradhedlund.s3.amazonaws.com/2011/hadoop-network-intro/Understanding_Hadoop_Clusters_and_the_Network-bradhedlund_com.pdf
Fail Over Node App Server 1 App Server 2 COUCHBASE Client Library COUCHBASE Client Library • App servers accessing docs • Requests to Server 3 fail • Cluster detects server failed Promotes replicas of docs to active Updates cluster map • Requests for docs now go to appropriate server • Typically rebalance would follow Cluster Map Cluster Map Server 1 Server 2 Server 3 Active Active Active Server 4 Server 5 Active Active REPLICA REPLICA REPLICA Doc 1 Doc 2 Doc 4 Doc 7 Doc 5 Doc 6 Doc 3 Doc 3 Doc 1 Doc 6 Doc 8 Doc 2 Doc 5 Doc 4 Doc 7 Doc 9 Doc 8 Doc 9 Doc 2 Doc 1 Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc Doc REPLICA REPLICA Couchbase Server Cluster User Configured Replica Count = 1
Rack-aware replication. Data Center Rack #2 APP server Rack #4 Rack #1 Rack #3 Client library Vb1 Replica 3 Vb1000 Active Vb1 Active Vb256 Replica 2 Vb500 Replica3 Vb277 Active Vb1 Replica1 Vb1000 Replica1 Vb256 Active Vb1 Replica 2 Vb900 Replica1 Vb1000 Replica 2 • Couchbase supports Rack aware replication through the number of replica copies and limiting the number of Couchbase nodes in a given rack.
Availability Zone-aware replication AWS EAST Zone A • Q8. If all the nodes of a single couchbase cluster (nodes 1-9) are distributed among 3X availability zones (AZ) as shown, can couchbase support AZ-aware replication? • That is to insure that the replicas of a doc are distribute across different zones, so that a zone failure does not result in doc unavailability. Node 1 Node 2 Node 3 Zone B Node 4 Assume Inter-AZ latency ~1.5 ms Node 5 Node 6 Zone C Node 7 Node 8 Node 9
Availability Zone-aware replication AWS EAST • Couchbase currently supports zone affinity through the number of replicas and limiting the number of Couchbase nodes in a given zone. • Replica factor is applied at the bucket level and up to 3 replicas can be specified. Each replica is equal to 1 full copy of the data set that will be distributed across the available nodes in the cluster. With 3 replicas – the cluster contains 4 full copies of the data. 1 active + 3 replica • By limiting the number of Couchbase nodes in a given zone to the replica count, losing a zone does not result in data loss as there is a full copy of data still in another zone. • In the example above – in a worst case scenario. We have 3 replicas enabled. Active lives on node1, replica1 lives on node2, replica2 on node3 and replica3 on node4. If zone 1 goes down, those nodes can be automatically failed over which promotes replica3 on node4 to active • Explicit Zone aware replication(affinity) is a roadmap item for 2013. Zone A Node 1 Node 2 Node 3 Zone B Node 4 Assume Inter-AZ latency ~1.5 ms Node 5 Node 6 Zone C Node 7 Node 8 Node 9
Throughput /latency with scale • We need performance tests showing scaling from 3 nodes to 50-80 nodes in a single cluster (performance tests to show performance (throughput and latencies) in 5 or 10 nodes increments). During these tests, the following configurations/assumptions must be used: • Nodes are physically distributed in 3 availability zones (e.g. AWS EAST zones). • No data loss (of any acknowledged write) when a single node fails in any zone, or when an entire availability zone fail. Ok to loose un-acknowledged writes since clients can deal with that. To achieve this, we need: • Durable writes enabled (i.e. don’t ack client’s request to write until the write is physically done to disk on the local node and at least one more replica is written to disks of other nodes in different availability zones). • Even though the shared performance tests look great, unfortunately the test assumptions used (lack of reliable writes) are unrealistic for our videoscape deployments/use case scenarios. • We need performance test results that are close to our use case! Please see the following Netflix’s tests and write durability /multi zone assumptions which are very close to our use case (http://techblog.netflix.com/2011/11/benchmarking-cassandra-scalability-on.html) • Q9. Please advise if you are willing to conduct such tests!
Throughput /latency with scale • We need performance test results that are close to our use case! Please see the following Netflix’s tests and write durability /multi zone assumptions which are very close to our use case (http://techblog.netflix.com/2011/11/benchmarking-cassandra-scalability-on.html) • The Netflix test describes that writes can be durable across regions but does not specify if the latency and throughput they saw were from Quorum writes or Single Writes(Single writes are faster and map to a unacknowledged write). This is similar to our benchmark numbers as though we have the ability to do durable writes across regions and racks we do not specify it in the data. Can you confirm that the Netflix benchmark numbers for latency/throughput/cpuutil were done wholly with Quorum writes?