Download
1 / 1
10 likes | 93 Views
Explore a model for learning and classifying within strict budget constraints, focusing on cancer diagnosis using heuristic policies. This method involves purchasing feature values wisely to predict patient subtypes accurately. The research delves into decision-making processes for optimal cost-effective outcomes.

E N D
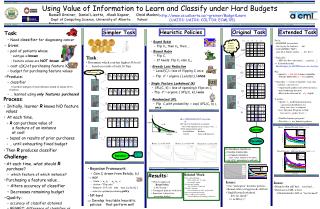
Russell Greiner, Daniel Lizotte, Aloak Kapoor, Omid Madani Dept of Computing Science, University of AlbertaYahoo! Research http://www.cs.ualberta.ca/~greiner/BudgetLearn (UAI’03; UAI’04; COLT’04; ECML’05) Using Value of Information to Learn and Classify under Hard Budgets Heuristic Policies Extended Task Original Task Simpler Task Task: • Need classifier for diagnosing cancer • Given: • pool of patients whose • subtype is known • feature values are NOT known • cost c(Xi) of purchasing feature Xi • budget for purchasing feature values • Produce: • classifierto predict subtype of novel instance, based on values of its features • … learned using only features purchased • So far, • LEARNER (researcher) has to pay for features… but • CLASSIFIER (“MD”) gets ALL feature values … for free ! • Typically… • MD also has constraints [… capitation …] • Extended model:Hard budget for BOTH learner & classifier • Eg: • spend bL= $10,000 to learn a classifier, that can spend only bC= $50 /patient… • Classifier = “Active Classifier” [GGR, 2002] • policy (decision tree) • sequentially gathers info about instance, • until rendering decision • (Must make decision by bC depth) • Learner … • spends bL gathering information, • posterior distribution P(·)[using naïve bayes assumption] • uses Dynamic Program to find best cost-bC policy for P(·) • Double dynamic program! • Too slow use heuristic policies • Round Robin • Flip C1, then C2, then ... Which feature of which instance?? Costs: 30 15 10 20 $100 • Biased Robin • Flip Ci • If heads, flip Ci; else Ci+1 • Task: • Determine which coin has highest P(head) • … based on results of only 20 flips • Greedy Loss Reduction • Loss1(Ci) = loss of flipping Ci once • Flip C* = argmini { Loss1(Ci) }once Which coin?? $95 20 • Single Feature Lookahead (k) • SFL(Ci, k) = loss of spending k flips on Ci • Flip C* = argmini { SFL(Ci, k) } once 19 $85 Process: • Initially, learner R knows NO feature values • At each time, • R can purchase value of a feature of an instance at cost • based on results of prior purchases • … until exhausting fixed budget • Then R produces classifier • Randomized SFL • Flip Ci with probability exp( SFL(Ci, k) ), once ⋮ 18 $0 17 • A is APPROXIMATION Algorithm • iff • A’s regret is bounded by a constant worse than optimal (for any budget, #coins, …) • NOT approximation alg’s: • Round Robin Random • Greedy Interval Estimation regret alg A Glass – Identical Feature Costs (bC=3) optimal Learner rA ⋮ budget 0 Classifier Beta(1,1); n=10, b=10 Beta(1,1); n=10, b=40 Beta(10,1); n=10, b=40 Use NaïveBayes classifier as… • it handles missing data • no feature interaction • Each +class instance is “the same”, … • only O(N) parameters to estimate Heart Disease – Different Feature Costs (bC=7) Selector “C7” Challenge: • At each time, what should R purchase? • which feature of which instance? • Purchasing a feature value… • Alters accuracy of classifier • Decreases remaining budget • Quality: • accuracy of classifier obtained • REGRET: difference of classifier vs optimal • Bayesian Framework: • Coin Ci drawn from Beta(ai, bi) • MDP • State = a1, b1, …, ak, bk, r • Action = “Flip coin i” • Reward = 0 if r0; else maxi { ai/(ai+bi) } • solve for optimal purchasing policy • NP-hard Develop tractable heuristic policies that perform well • Results: • Obvious approachRound robin is NOT good ! • Contingent policies work best • Important to know/use remaining budget • Related Work • Not standard Bandit: • Pure explore for “b” steps, then single exploit • Not on-line learning • No “feedback” until end • Not PAC-learning • Fixed #instances; NOT “polynomial” • Not std experimental design • This is simple active learning • General Budgeted Learning is different • … • Issues: • Use “analogous” heuristic policies • Round-robin (std approach) still bad • SingleFeatureLookahead: how far ahead? • k in SFL(k) ? • Issues: • Round-robin still bad… very bad… • Randomized SFL is best • (Deterministic) SFL is “too focused”