Download
1 / 1
10 likes | 186 Views
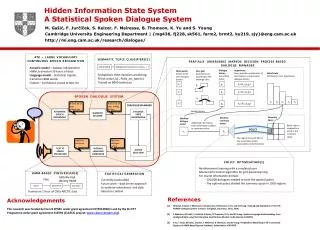
This paper discusses the development of a statistical spoken dialogue system utilizing a Partially Observable Markov Decision Process (POMDP) framework. It highlights the system’s capabilities in managing dialogue through a trained model that incorporates both acoustic and language components. Leveraging over 39 hours of data and statistical trigram analysis across 80 million words, the dialogue manager can generate a confidence-scored N-best list of user actions. Additionally, the implementation of Reinforcement Learning optimizes dialogue interaction for a tourist information domain, showcasing a promising avenue for enhancing natural language processing systems.

E N D
Hidden Information State System A Statistical Spoken Dialogue System M. Gašić, F.Jurčíček,S. Keizer,F. Mairesse, B. Thomson, K. Yu and S. Young Cambridge University Engineering Department | {mg436, fj228,sk561, farm2, brmt2, ky219, sjy}@eng.cam.ac.uk http://mi.eng.cam.ac.uk/research/dialogue/ ATK – LARGEVOCABULARYCONTINUOUSSPEECHRECOGNITION SEMANTIC TUPLECLASSIFIERS[2] Partially Observable Markov Decision Process-BASED DIALOGUE MANAGER utterance(u) dialogue act type (slot1=value1, … ) Acoustic model – Speaker independent HMM, trained on 39 hours of data Language model - Statistical trigram, trained on 80M words Output – Confidence scored N-best list Dialogue history Grounding states Hypotheses Every possible combination of observation, user goal and dialogue history Observation N-best list of user dialogue actions User goal partitions built according to the ontology rules Belief state Distribution over hypotheses Probabilistic SVM classifiers predicting: P(sloti=valuei|u) , P(dia_act_type|u) Trained on 8000 sentences ãu1 g1 h1=(ãu1,p2,g3) p1 ãu2 g2 h2=(ãu3,p2,g2) SPOKEN DIALOGUE SYSTEM p2 h2 h1 h4 h3 h5 ãuN gK hM=(ãu2,p1,gK) N-best list of user utterances N-best list of user dialog. actions DIALOGUE MANAGER AUTOMATIC SPEECH RECOGNISER SEMANTIC DECODER DIALOGUE STATEMAINTAINING Update history Summary Space Machine summary action Machine dialogue action Additional information from belief state is added to summary action Belief state is mapped to a point in the summary space am ām POLICY The region the point falls in has a summary action associated to it by the policy Machine sentence Machine dialogue action TEXT TO SPEECH SYNTHESISER NATURAL LANGUAGE GENERATOR ACTION SELECTION POLICY OPTIMISATION[1] Reinforcement learning with a simulated user Monte Carlo Control algorithm for grid-based learning For tourist information domain: - 100,000 dialogues needed to train the optimal policy - The optimal policy divided the summary space in 1500 regions HMM-BASED SYNTHESISER[3] STATISTICAL GENERATION Globally-tied density HMM Flite Currently handcrafted Future work – data driven approach to optimise naturalness and style based on context word phoneme acoustics Trained on 1 hour of CMU ARCTIC data References Acknowledgements [1] M Gašić, S Keizer, F Mairesse, J Schatzmann, B Thomson, K Yu, and SJ Young. Training and Evaluation of the HIS POMDP Dialogue System in Noise. In SigDial, Columbus, Ohio, 2008. [2] F Mairesse, M Gašić, F Jurčíček, S Keizer, B Thomson, K Yu, and SJ Young. Spoken Language Understanding from Unaligned Data using Discriminative Classification Models. Submitted to ICASSP09. [3] K Yu, T Toda, M Gašić, S Keizer, F Mairesse, B Thomson, and SJ Young. Probabilistic Modelling of F0 in Unvoiced Regions in HMM Based Speech Synthesis. SubmittedtoICASSP09. This research was funded by the UK EPSRC under grant agreement EP/F013930/1 and by the EU FP7 Programme under grant agreement 216594 (CLASSIC project: www.classic-project.org).


















