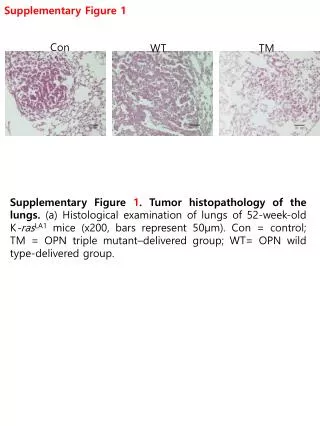
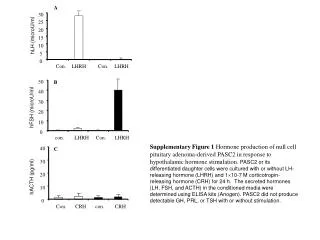
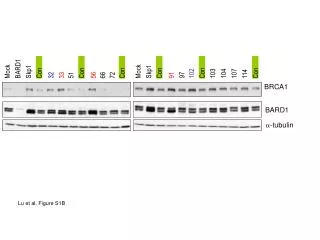
Download

1 / 24
240 likes | 377 Views
Analizzatori Lessicali con JLex. Giuseppe Morelli. Terminologia. Tre concetti sono necessari per comprendere la fase di analisi lessicale: TOKEN: rappresenta un oggetto in grado di rappresentare una specifica classe di unità lessicali. In genere è rappresentato da un nome ed un attributo.

E N D
Analizzatori Lessicali con JLex Giuseppe Morelli
Terminologia • Tre concetti sono necessari per comprendere la fase di analisi lessicale: • TOKEN: rappresenta un oggetto in grado di rappresentare una specifica classe di unità lessicali. In genere è rappresentato da un nome ed un attributo. • PATTERN o MODELLO: è una descrizione compatta delle possibili forme che una unità lessicale può assumere • LESSEMA: è una sequenza di caratteri del programma sorgente che corrisponde al pattern di un token (istanza specifica di un token)
Compiti di un analizzatore lessicale • È la prima fase del processo di compilazione ed ha il compito principale di leggere il programma sorgente (sequenza di caratteri), raggrupparli in lessemi, e produrre in uscita una sequenza di token corrispondente ai lessemi trovati, interagendo con la tabella dei simboli. • Trattando direttamente il programma sorgente l’analizzatore lessicale è in grado di svolgere ulteriori operazioni e/o compiti
Elimina e/o ignora spazi vuoi e delimitatori in genere (spazi, tabulazioni, ritorni a capo) • Associa i messaggi di errore prodotti dal compilatore al programma sorgente ( es. conta il numero di CR e lo restituisce in presenza di un errore, o si occupa di riscrivere il programma sorgente con “iniettato” il messaggio di errore nella linea corrispondente) • Se nel programma sorgente sono presenti delle macro potrebbe occuparsi della relativa espansione
Fasi analisi lessicale • A volte gli analizzatori lessicali sono visti come composizione di due distinti processi: • La scansione o scanning: eliminazione di separatori e commenti espansione di macro etc. …ovvero tutte le attività che non richiedono la tokenizzazione • L’analisi lessicale vera e propria: produzione della sequenza di TOKEN a partire dalla sequenza già “scansionata”.
Un analizzatore lessicale ha lo scopo di suddividere un “flusso” di caratteri in input in TOKEN. • Realizzare un analizzatore lessicale da zero, può risultare un lavoro alquanto complicato. • La miglior utility per la costruzione di un analizzatore lessicale è il programma Lex (generatore di analizzatori lessicali per Unix) che, dato un file di specifiche, genera il codice C di un analizzatore che soddisfa le specifiche
JLex • JLex è una utility basata sul modello Lex, prende infatti delle specifiche simili a quelle accettate da Lex, quindi, crea un sorgente Java che implementa un analizzatore lessicale soddisfacente le specifiche.
Download ed installazione • Il Link : http://www.cs.princeton.edu/~appel/modern/java/JLex/ • È possibile scaricare il sorgente del generatore: Main.java (naturalmente è scritto in Java) • Si mette in una directory JLex (il cui path sta nel PATH di ambiente) • Si compila • Si richiama su un file di specifica con :java JLex.Main source.lex • Nello stesso sito: manuale, readme, esempi.
Struttura di un file di specifica Lex • Tre sezioni separate dal simbolo “%%”: • User Code: viene ricopiata nel file java finale “as is”; fornisce “spazio” per implementare classi di supporto etc.. • JLex directives: Vengono definite le Macro e vengono dichiarati i nomi degli stati • JLex rules: vengono definite le regole per l’analisi ognuna delle quali consiste di tre parti: lista degli stati (opzionale), espressione regolare, azione User code %% Jlex directives %% JLex rules
User Code Section • Contiene le classi per: • Utilizzo del lexer (potrebbe non esserci se utilizzato in combinazione con un generatore di parser) • Funzioni, proprietà, variabili e/o costanti di supporto • La definizione degli oggetti TOKEN
Note: JLex Directives • Yylex: è la classe generata dal lexer che implementa l’analizzatore lessicale • Per l’utilizzo del lexer nella sezione user code viene istanziato un oggetto e poi utilizzato come precedentemente mostrato • Vedremo in seguito che si può inserire codice in tale classe • Inserendo metodi e/o proprietà %{ code %} • Modificandone il costruttore (con o senza gestione delle eccezioni) %init{ code %init} • Inserendo codice eseguibile quando la fine del file viene raggiunta %eof{ code %eof}
JLex Directives – Definizione di Macro • Una macro è di fatto la definizione di una espressione regolare; • Consiste di : <nome> = <definzione> dove nome è un identificatore, definizione è una espressione regolare; • Una definizione di macro può contenere l’espansione di altre macro
JLex Directives - Dichiarazione di stato • Gli stati lessicali sono utilizzati per controllare il matching di alcune espressioni regolari. • La dichiarazione avviene: %state state[0], state[1], state[2] ….. dove state[0], state[1], state[2] … sono identificatori validi • YYINITIAL è lo stato implicito di ogni lexer generato con JLex • Tali stati compaiono opzionalmente all’inizio di ogni regola per la selezione della stessa.
JLex Directives • %char permette di attivare il conteggio dei caratteri(yychar)in input (0 based) • %line permette di attivare il conteggio dei caratteri(yyline)in input (0 based) utile per la gestione e la segnalazione degli errori • La funzione Yylex.yylex() è la funzione da invocare per avere i TOKEN di tipo YytokenSi possono modificare le cose con: • %class <name> cambio Yylex in name • %function <name> cambio yylex in name • %type <name> cambio Yytoken in name
JLex Rules: Regolar Expression • Si tratta delle regole che consentono la suddivisione in TOKEN dell’input. • Si associano espressioni regolari, che rappresentano i lessemi del linguaggio, ad azioni (ovvero codice Java…. tokenizzazione) • Ogni regola ha tre parti: [<stati>] <espressione> {<azione>} • Se più di una regola è soddisfatta da una stringa di input viene eseguita la prima in ordine di apparizione (maggiore priorità)
Stati ed espressioni • <stato0, stato1,…>: elenco di stati, opzionali, che permettono di attivare una regolaSe la funzione yylex() è chiamata con il lexer che si trova nello stato X, il lexer potrà fare il matching con regole che hanno X nell’elenco degli stati • Nessuno stato -> la regola è selezionata in tutti gli stati • L’alfabeto per JLex è rappresentato dal set di caratteri Ascii (0 – 127): • Metacaratteri ? * + | ( ) ^ $ . [ ] { } “ \ • Escape \b \n \t \f \r \ddd \^C \c • Concatenazione r1r2 concatenazione di r1 ed r2 • Scelta r1 | r2 r1 oppure r2
Azione • L’azione associata ad una regola lessicale consiste in un blocco di codice Java { codice } • Tale codice dovrebbe prevedere un valore di ritorno.. Altrimenti il lexer va in loop alla ricerca di un altro lessema(coincide ad una chiamata ricorsiva a yylex()) • Attenzione alla ricorsione ed alla giusta gestione di yyline e yychar (non tail recursion vs tail recursion)
Transizione degli stati • La transizione degli stati è fatta da una azione attraverso la chiamata alla funzione yybegin(state) • state deve essere uno stato valido dichiarato nella sezione JLex Directives • YYINITIAL è l’unico stato implicito ed è lo stato in cui il lexer rimane fino a che una non viene effettuata una transizione
Il Lexer generato: note • Risiede in una classe Yylex • La funzione di accesso al lexer è Yylex.yylex() che restituisce token di tipo Yytoken • La classe Yytoken deve essere dichiarata nella USER CODE Section: • può ridefinire anche tipi primitivi • Si possono definire gerarchie di classi per token
Esempi • Riconoscitore di Numeri ed identificatori • Riconoscitore di Numeri ed identificatori evoluto • Utilizzo degli stati per il riconoscimento di “stringhe”