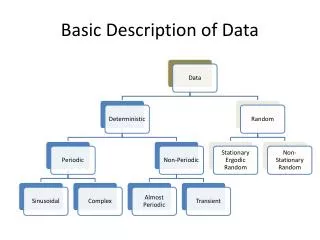
Data description
Data description. Peter Shaw. One variable or many?. In your research you will almost certainly end up measuring many different things: ‘Survey the plants’ means collecting 10-50 columns of data ‘Analyse the soil’ means 5-10 variables ‘take body measurements’ means 5-30 variables.


Data description
E N D
Presentation Transcript
Data description Peter Shaw
One variable or many? In your research you will almost certainly end up measuring many different things: ‘Survey the plants’ means collecting 10-50 columns of data ‘Analyse the soil’ means 5-10 variables ‘take body measurements’ means 5-30 variables. This lecture is essentially about how to explore each of those variables, one by one, to tell a reader about the range or distribution of values it contains. This tells a reader about how important the variable is and what sort of tests may be run on it (P or N-P?). But this does not treat your dataset as a unified object. There is a powerful branch of data description called Ordination, which is essentially asking for a description of ALL variables at the same time.
Things to do with data: • This is an infinite morass of statistical techniques, but one fundamental division is paramount and must be understood. • DESCRIPTIVE <---------------------> INFERENTIAL • Descriptive statistics aim to condense out the useful/important essence of a (usually large) body of data. • Calculate an average, plot a graph showing the range of values etc. • Inferential statistics requires that the user sets up a formal hypothesis, then invokes a procedure which ends up with a probability value by which the hypothesis may be judged.
Why bother with data descriptions? Standard format: Abstract Introduction Methods Results Discussion References I have lost count of the number of times that students have got this far then dived straight into the fancier analyses – Correlations or Anovas usually, without bothering to tell the reader anything about the data they are analysing.
Standard format: Abstract Introduction Methods Results Discussion References 1: Describe your data: units, indications of typical values + variability. 2: Analyse relationships within your data
General ground rules: Pb, ppm in white Paint exposed on a nursery door 16207 14833 29524 18436 26236 • 1: What do the data mean, • What are the units? • 2: Eyeball it! • 3: Summon up the formal procedures, by PC or calculator
Graphing data • This is a huge topic, entire books have been written. One unifying point: • A good graph is the best way to present data. I am going to show you several histograms today. These show the distribution of values within a dataset. Number of observations Size of value
What could you want to know about a dataset? • In order of decreasing likelihood: • What magnitude of numbers are you dealing with? • What sort of spread have you got? • What is the nature of the distribution of results? • ?other? (your turn!)
Magnitude summaries • In plain English, what sort of values am I dealing with? • In statspeak, you require Measures of Central Tendency • There are 3 such measures you need to learn, of which 2 are actually useful! • Mean • Median • Mode
Mode • This is simply the commonest occurrence in the data. Most real datasets don’t have a mode, as all values are different. • As such, the Mode is easily the least useful technique for data description, but is always mentioned in the books so you may as well learn it! Pb, ppm in white Paint exposed on a nursery door 16207 14833 29524 18436 26236
Median Pb, ppm in white Paint exposed on a nursery door 14833 16207 18436 median 26236 29524 • This is the middle of the dataset, defined as the point below which half the data points lie, and above which half the data lie. • How to find it: • Sort data into ascending order 1..N • If N is odd, median is the (N+1)/2th value • If N is even, median is half way between (N/2)th and ((N/2)+1)th value
Median, contd • The median is an under-rated tool, often preferable to the more widely used mean, because it gives a sensible answer whatever the shape of data distribution • It is a special case of a more general descriptive technique known as centiles. • The median is the 50th centile of a dataset, meaning that 50% of the data points lie below it.
The Mean • The ‘Mean’ is the name given by statisticians to what everyone else calls the ‘average’!Often given symbol μ. • Easy to calculate: add up the numbers and divide by N • μ=Σx/N • Your calculator should have this built in as a stats function • It is often NOT the middle of the data. This happens when data are asymmetrically distributed
Number of observations A symmetrical distribution Size of value Mean and median about the same Mean An asymmetrical distribution. Note that the mean is misleading here Size of value Median
Number of observations Two data sets. In which one are you more likely to guess the next value correctly? Distribution A Size of value Number of observations Distribution B Size of value
This leads onto..Measures of dispersion • These are indicators of how tightly clumped data are. • There is a proliferation of such indices, but they divide into 2 families: • Non-parametric, based on centiles • Parametric, based on variance and giving rise to standard deviations etc.
UNSORTED More paint Pb Data, ppm 2734 3404 5000 4641 16207 14833 1515 1667 29524 18436 26236 7255 5800 10588 9462 6368 5122 6585 6846 4143 SORTED Paint Pb Data, ppm 1: 1515 2: 1667 3: 2734 4: 3404 5: 4143 ***25th centile here 6: 4641 7: 5000 8: 5122 9: 5800 10: 6368 *** 50th centile = median here 11: 6585 12: 6846 13: 7255 14: 9462 15: 10588 ***75th centile here 16: 14833 17: 16207 18: 18436 19: 26236 20: 29524 Centiles • 1: sort data into ascending order (this is a PC job for big datasets) • 2: To get the 25th centile, find the number below which 25% of the data lie • 3: To get the 75th centile, find the number below which 75% of the data lie, etc
The inter-quartile range • Is the difference between the 25% and 75% centiles of a distribution. • This means that is is the range covered by the middle half of the data. Number of observations 50th 75th 25th Size of value Interquartile range
Boxplots 100 Highest value 75th centile • These are under-rated, but extremely helpful tools for examining the distribution of data. median 50 25th centile Lowest value 0
Standard deviations and all that.. 1000 X1 • The parametric family of measures of dispersion have messy-looking formulae, but luckily are easily obtained from calculators or PCs • They are based on a measure misleadingly called the sum of squares of the data (SS). • The origin of SS is as follows: • For each data point Xi calculate • (Xi - mean)*(Xi - mean) [This square >=0 ] • Add up all these squares = SS • Formula: SS =Σi(xi - μ)2 • Luckily there is a simpler(?) formula • SS =Σi(xi2)– (Σixi * Σixi)/N X3 500 Mean X2 0
Variance etc • Having got the Sum of Squares • Variance is the mean value of SS • Variance = SS/N • (an alternative formula also used: • Variance = SS / (N-1) • This estimates the variance of the whole population, while /N gives variance just for the sample taken. • Geographers tend to prefer • Variance = SS/N • Biologists tend to prefer • Variance = SS/(N-1)
Standard deviation • Is the square root of variance • This has the useful property that sd has the same units as the raw data and will be commensurate with the interquartile range. (Roughly, for typical data, the IQR= 2* sd) • Because there are 2 ways to calculate variance, there are 2 s.d.s • Sd = (SS/N)1/2. This is labelled σ on many calculators or Sd = (SS/(N-1))1/2. This is labelled s on many calculators
How to use your calculator • Why is he telling me this – I already know?! • OK then, what’s this hierarchy? • +- < */ < Yx < () • Use this to calculate • 123*456+789*112 • (109*256+103*876)/(22*44+89*78) • The solution to the ‘grains of rice on a chessboard’ problem is 264-1 • (ie 2*2*2………..….*2 –1), which is?
Stats modeon yourcalculator • If you have buttons saying N, Σx, sd then your machine has stats functions • This means it has special registers called N, Σx and Σx2, which keep running totals as you enter data. • Put into stat mode • Enter the number 7 by hitting the Σ or M+ or Xi button • Optional, but for your education find the contents of the special registers (Kout or recall) • N =1, Σx = 7, Σx2 = 49 • Enter the number 2 • Now you find that N =2, Σx = 9, Σx2 = 53 • Now the Mean button will give you the mean 4.5, the sd buttons the sds (2.5 sd/n, 3.53.. /n-1). Easy!
Your turn! • For the numbers listed here • Find mean, median, mode, • and interquartile range • Find both standard deviations, by your calculator’s inbuilt functions or by the formulae: • SS =Σi(xi2)– (Σixi * Σixi)/N • Then • Sd = (SS/N)1/2. or Sd = (SS/(N-1))1/2 • Water content of heathland soils, % • 8.53 • 17.53 • 39.14 • 32.00 • 20.53 • 21.07 • 26.20 • 23.80 • 12.53 • 20.80 • 31.33 • 28.87 • 14.00
Distribution shape Often real data don’t follow the Normal curve but are skewed – here organic content in heath soils Try log-transforming the data. Here the same data after calculating log of the numbers – not perfect, but clearly more symmetrical
How to decide about normality? • Inspect histogram + fitted normal curve. • Inspect a cumulative “P-P curve” with predicted normal distribution • Run the Kolgomorov-Smirnov test
The Kolmogorov-Smirnov test examines whether data can be assumed to come from a chosen distribution – here the normal. LogLOI may or may not be normal, but the test tells us that its deviations from normality would occur 7 times in 10 in randomly chosen normal data LOI is almost certainly NOT normally distributed
Kolmogorov test in SPSS Typical SPSS – does the same test in 2 ways in different bits of menu structure and uses different algorithms to assess significance. I use the basic version Analyse – non parametric stats – 1 sample KS But it also hides under Analyses – descriptive statistics – explore – plots then click the box labelled “Normality plots with tests”. This well-hidden version uses a modified significance test (Lilliefor’s correction), which really threw me the first time I met it!