Lecture 8: Modern Dynamic Instruction Scheduling
180 likes | 403 Views
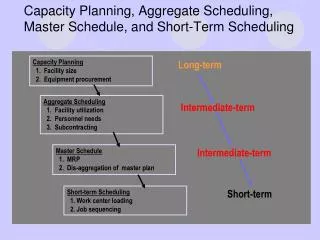
Lecture 8: Modern Dynamic Instruction Scheduling. Tomasulo weakness, data forwarding, reg mapping table, generic superscalar models, examples. Observe at the EX stage, how many cycles to execute this code? LW R2,45(R3) ADD R6,R2,R4 SUB R10,R0,R6 ADD R10,R10,R12

Lecture 8: Modern Dynamic Instruction Scheduling
E N D
Presentation Transcript
Lecture 8: Modern Dynamic Instruction Scheduling Tomasulo weakness, data forwarding, reg mapping table, generic superscalar models, examples
Observe at the EX stage, how many cycles to execute this code? LW R2,45(R3) ADD R6,R2,R4 SUB R10,R0,R6 ADD R10,R10,R12 Assume load takes 1 cycle, ALU 1 cycle Tomasulo Performance IM Fetch Unit Reorder Buffer Decode Rename Regfile S-buf L-buf RS RS DM FU1 FU2
How many cycles on the 5-stage MIPS pipeline? Why does the simple pipeline run faster? Tomasulo vs MIPS Pipeline IF ID EX MEM WB Stall check Data forwarding
Modern processors employ deep pipeline => Can the rename stage be finished in one fast cycle? => How are register content storages? Tomasulo Complexity and Efficiency IM Fetch Unit Reorder Buffer Decode Rename Regfile S-buf L-buf RS RS DM FU1 FU2
Review Tomasulo Inst Scheduling Both in RS, no contention on CDB or FU ADD R2,R2,45 # R2=>tag p, result = A SUB R6,R2,R4 # R4 is ready, = B Cycle 1: ADD starts at FU, producing A Cycle 2: ADD broadcast p + A SUB matches on p and accepts A Cycle 3: SUB starts execution, FU calc A-B A is produced at cycle 1, but consumed at cycle 3 -- unavoidable?
MIPS pipeline data forwarding: FU/MEM => FU Why not in Tomasulo? Cycle 2: forward A from FU output to FU input… But tag broadcasting has one cycle delay!! When is it known that A will be ready? Cycle 1: A is to be ready Cycle 2: A and its tag are broadcast If tag is broadcast one-cycle earlier … Review Data Forwarding REG/ROB FU bypass ROB
RS1: ADD R6,R2,R4 RS2: SUB R10,R0,R6 RS3: ADD R12,R10,R6 ADD(1) has been ready and selected - ADD(1)’s tag is broadcast, and operands are sent to FU; - SUB is waken up and selected; - SUB’s tag is broadcast, operands are sent to FU; - forwarding logic replace 2nd FU operand with FU output; - ADD(2) is waken up and accepts FU output, and is selected So on and so forth… RS can be centralized or distributed Revise Scheduling* RS 1 RS 2 RS 3 RS 4 RS 5 SELECT FU One cycle earlier *Updated How to address CDB contention?
FETCH ISSUE EXE WB COMMIT Revise Pipeline Stages FETCH RENAME REG/ROB Rd SCHEDULE EXE WB ISSUE: decode, rename, allocate RS and ROB, and read REG/ROBEX: Wakeup and select inst, then fu-execute COMMIT
Examples: Intel P6 … Decode Decode Rename ROB Rd … • 40-entry ROB • 20-entry RS station • Register Alias Table
Data broadcasting to RS stations: Broadcasting saves reg-write to reg-read delay n child instructions can receive data simultaneously However, Data forwarding can be used Not all n child instructions may fu-execute next cycle RS and ROB may store duplicate values Rethink RS and ROB design
Physical Register Physical register p1 RS entry p2 op Qj Qk busy Vj Vk p3 ROB entry i-type dest PC valid result p_n Physical register: collection of all temporary register contents
Rename architectural register to physical register NO real architectural registers (now virtual register) RS => issue queue Rename stage: allocate issue queue entry, allocate ROB, allocate physical register What is tag now? Register Mapping Approach ra rb rc pc Mapping Table pa pb p1 alloc p2 pa p3 pb free list p_n vala valb
RS+ROB: no changes to arch. registers, so just clear pipeline and re-fetch Fundamental issue: software does not see wrong register contents Recovery for mapping approach: Roll back mapping table to the mis-speculation point Architectural registers => virtual registers Mis-speculation Recovery Committed mapping p1 p2 mapping 1 p3 ROB mapping 2 p_n mapping table status How to implement mapping table supporting recovery?
Change of pipeline FETCH IM Fetch Unit RENAME Decode Rename ROB SCHEDULE issue queue REG phy. regfile EXE WB S-buf L-buf FU1 FU2 COMMIT DM
Example: Intel Pentium 4 Alloc Rename Rename Queue Schd Schd Schd Disp Disp Reg Reg Ex 128entries
Generic Superscalar Processor Models Issue queue based FU Wakeup select Regfile bypass Fetch Rename Schedule D-cache FU commit execute Reservation based Reg FU bypass Fetch Rename Schedule D-cache ROB Wakeupselect FU commit execute Source: Paracharla PhD thesis 1998
Pipeline stages Renaming (in-order) Schedule Commit (in-order) Two organizations Mapping table + phy reg + issue queue + ROB;REN => SCHD => REG Reg alias table + RS + ROB, reg in RS and ROB;REN => REG => SCHD Scheduling methods Tag broadcasting vs. scoreboarding (later) CDC6600: introduces scoreboarding Tomasulo: introduces renaming and tag broadcasting Reorder buffer: provides in-order commit Real OOO processors very complicated (like a vehicle) bring impl variants but all root in those basic designs Summary of Dynamic Scheduling