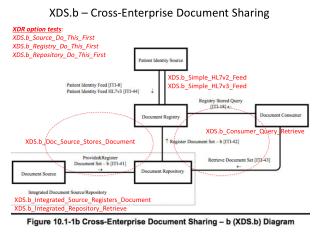
Download

1 / 65
650 likes | 774 Views
This document explores Cross-Document Coreference (CDC), a crucial NLP task recognizing how names and entities refer across various documents. It compares CDC with within-document coreference and Word Sense Disambiguation (WSD), emphasizing the challenges posed by ambiguous names. The methodologies for CDC are discussed, including event and cross-media coreference, alongside scoring methodologies. The significance of context in distinguishing entities and practical applications of CDC are demonstrated through empirical evaluations, showcasing precision and recall in identifying references within large corpora.

E N D
Introduction to Cross-Document Coreference Amit Bagga StreamSage/Comcast Amit_Bagga@cable.comcast.com
Outline • Motivation and Definition • Comparison with Within-Document Coreference, WSD and other NL tasks • Methodologies for Entity Cross-Document Coreference • Other types of Cross-Document Coreference • Concept Cross-Document Coreference • Event Cross-Document Coreference • Cross-Media Coreference • Cross-Language, Cross-Document Coreference • Scoring Methodologies
Motivation • Proper names comprise approximately 10% of news text (Coates-Stephens, 1992) • Names are often ambiguous across documents • increasingly becoming a challenge for NLP systems as collection size and generality grow • also as systems break the “document boundary”
Definition • Cross-Document Coreference (CDC) for entities, in broad terms, asks • how can one computationally disambiguate the intended referent of a name • Winchester & Lee 2002 • for example, it asks, which ‘John Smith’ is meant by a particular occurrence of the string “John Smith”
Comparison with Within-Document Coreference • Within a document • Identical or similarly named entities seldom appear in the same context • when they do, writers distinguish them explicitly • i.e. it is usually the case that we have one referent per discourse • Variant form of the same name generally obey certain regularities which are predictable • For example: Michael Jordan may be referred to by the following – Michael, Mr. Jordan, Jordan, etc.
Across documents • Assumption that same or similar names refer to same entity is not valid • Linguistics theories do not apply • The only way to distinguish between these entities is to examine context
Comparison with WSD • CDC can be thought of as disambiguating the “sense” of usage of a name • In WSD: • Usually possible to enumerate a priori all possible senses of word • Number of possible senses of word is small (1-10) • In CDC: • A large corpus can contain 10s or 100s of entities with same name which are impossible to enumerate a priori • From linguistic perspective, all entities equally plausible
The Role of Context • Similar to WSD, context is vital for CDC • context can be of different sizes • window of words centered around a name, sentence containing name, group of sentences, or even whole document • modeling context can be done in many different ways • bag of words, set of phrases, set of entities, set of relations, etc. • All CDC systems use context in one form or another
Bag of Words Approach • Bagga and Baldwin, 1998 • Within-document coreference system is used to identify all mentions of entity • Sentences containing mention are extracted from each document • “summaries” with respect to entity • Set of summaries compared using VSM (tf*idf) • Single-link clustering used • Version 2 (1999) eliminates use of within document coreference system • sentences containing any variant of name extracted
Corpus, Evaluation, and Results • 197 articles containing “John Smith” extracted from 2 years of New York Times data • 35 different John Smiths • B-CUBED algorithm used • Version 2 results • 84% F-Measure • 90% Precision, 78% Recall • < 1% F-Measure drop when compared to original system
Minimizing Context Matches • Kazi and Ravin, 2000 • Problem with Bagga and Baldwin, 1998 • Prohibitively expensive in terms of storage and n-to-n comparisons (specially in a large corpus) • Use IBM’s Nominator for named entity identification and within document coreference (non-pronominal) • CDC task is merging canonical names from different documents that refer to same entity • Context analysis done by use of a Context Thesaurus • Given a name, returns a ranked list of terms that are related to name in the corpus
E = Exclusives – i.e. no merging possible • M = Mergeables – i.e. compatible with some or all exclusives
Tables are created by analyzing two lists sorted by ambiguity • PERS names • George Walker Bush > George W. Bush > George Bush > G. Bush > Bush • PLACE names • Albany, NY > Albany • Merging steps • Merge identical canonical strings >= 2 words • Merges 28 George Bush, 2 President Bush 7 Vannevar Bush articles into 3 equivalence classes • Between mergeables and exclusives, combine if any variants share a common prefix • Merges E3, M1 and M3 (common prefix = President) • Reduces # of context matches from 58x58 to 7x4
Corpus, Evaluation, and Results • Corpus – 1998 editions of New York Times • 15 name families • For example: Berger, Black, Brown, Bush, Clinton, Gore, etc. • B-CUBED algorithm for scoring • Without context comparisons: • Avg Precision = 98.5% • Avg Recall = 72.85% • No results reported when context comparisons are used (Ravin and Kazi, 1999)
3 Models of Similarity • Gooi and Allan, 2004 • Methodology similar to Bagga and Baldwin • extract 55 word snippets centered at name or its variant • Problem with Bagga and Baldwin • sharp drop off in F-Measure around threshold • 3 different models of similarity • Incremental Vector Space • tf*idf, but with average link clustering • KL divergence • snippets are represented as probability distribution of words • similarity = “distance” between two probability distributions • Agglomerative Vector Space • tf*idf with bottom-up, complete-link clustering
Corpus • John Smith corpus (Bagga and Baldwin) • Person-x corpus • created by querying TREC collection with queries like arts, business, sports, etc. • BBN’s IdentiFinder used for named entity recognition • one name (and its corresponding variants) randomly replaced with phrase Person-x • 34,404 documents; 14,767 actual unique entities
Evaluation and Results • B-CUBED algorithm used for scoring • Agglomerative VS best • 88.2% F-Measure for John Smith corpus • 83% F-Measure for Person-x corpus • When run on each sub-corpus (arts, sports, etc.) of Person-x corpus • F-Measure drops to 77% • shows that a more homogenous corpus is more difficult • Results for Agglomerative VS degrade much more smoothly around threshold than others
Second Order Co-Occurrence • Three methods – independently published • Bagga, Baldwin, and Ramesh, 2001 - 2-pass algorithm • First pass: as before • Second pass: • for each chain, compute set of most frequent overlapping words in chain (signature words for chain) • for each singleton document after pass 1, compare to each chain • use signature words to extract additional sentences • compare enhanced summary to every summary in chain • merge if similarity > threshold • if not merged with any chain, remains singleton
Winchester and Lee, 2001 • named entity detection and conflation within documents is done as pre-processing step • based on Schutze’s (1998) algorithm for context-group discrimination • 3 types of vectors are created • Term Vectors – formed for each name occurring in context of entity of interest and its variants • stores co-occurrence stats for term across whole corpus • Context Vectors – formed for entity of interest by summing all term vectors associated with its context • term vectors are weighted with their idf scores before sum • Entity Vectors – for each entity, it is centroid of set of context vectors • entity disambiguation is done by comparing Entity Vectors using VSM with single-link clustering
Corpus, Evaluation, Results • Bagga, Baldwin, and Ramesh • John Smith corpus, B-CUBED scoring • new F-Measure 91% (+7 from before) • Winchester and Lee • 30 name sets; 10 each of PER, LOC, ORG • from 6000 WSJ articles • B-CUBED scoring • discovered that selective creation of 3 types of vectors boosts performance • for example, LOC helps disambiguate other LOC • Birmingham, Alabama vs UK; John Smith associated with Pocahontas • overall F-Measure 78.5% • NAM – 90.3%, LOC – 79.2%, ORG – 72.5%
Guha and Garg, 2004 • mine descriptions associated with entity of interest (sketch) • descriptions are other entities + professions that are in close proximity • comparing descriptions • different weights given to different descriptions given type of entity of interest and entity-type of description • for example: location is more likely to be disambiguated by another location than by the name of a person • Corpus and Evaluation • 26 entities (names + places), 2-6 instances identified of each • sent as queries to search engines, top 150 results collated and manually tagged for truth • best F-Measure = 90.3%
Maximum Entropy Model • Fleischman and Hovy, 2004 – use ME to determine if two concept/instance pairs are same entity • concept/instance pairs – ACL dataset (2M pairs) • John Edwards/lawyer and John Edwards/politician • Name features: NAME-COMMON (census), NAME-FAME (ACL dataset), WEB-FAME (Google) • Web features: based on # of Google hits with name plus headwords of concepts used as queries • Overlap features: based on # words overlapping in context of names and concepts • Semantic features: based on semantic relatedness of concepts (WordNet) • for example: lawyers are more likely to become politicians • Estimated Statistics features: probabilities that a name is associated with a particular concept (computed over entire ACL dataset) • Disambiguation using group-average agglomerative clustering • Tested on set of 31 concept/instance pairs (1875 used for training) • 20 had a single referent • F-Measure = 93.9% • baseline (all in same chain) = 92.4%
Robust Reading Approach • Li, Morie, and Roth, 2004 • a global probabilistic view of how documents are generated and how entities are “sprinkled” into them • Model 1 (simplest – no notion of author) • entities are present in a document with a prior probability, independent of other entities • mentions (references) are selected according to probability distribution P(mj|ei) • i.e. entity referenced by a mention is not dependent on other mentions • Model 2 (more expressive) • # of entities in doc and # of mentions follow uniform distribution • entities enter doc with a prior probability, independent of others • representative (canonical form) for each entity is selected according to P(rj|ei) • for each representative, mentions are selected by P(mk|rj) • i.e. entity referenced by a mention depends on other mentions in the same document
Model 3 (least relaxation) • # of entities based on uniform distribution – but not independent of each other • entities in doc viewed as nodes in a weighted directed graph with edges labeled as P(ej|ei) • entities inserted in document via a random walk starting at an entity with prior probability P(ek) • representatives and mentions follow the same probabilities as Model 2 • i.e. entity referenced by a mention depends on other mentions in same document, but also on other entities in entire corpus • Models learned using truncated EM algorithm • Evaluation • 300 NYT articles from TREC corpus • 8000 mentions corresponding to 2000 entities (people, locations, organizations) • compared to SOFT-TF-IDF and baseline (entities with identical writing are same) • overall F-Measure = 89% (model 2) • baseline = 70.7% and SOFT-TF-IDF = 79.8% • Model 3 does not perform best because • global dependencies enforces restrictions over groupings of similar mentions • because of limited document set, estimating global dependency is inaccurate
Using IE Features • 3 different methods published • Mann and Yarowsky, 2003 • use unsupervised learning to learn patterns from corpus that capture biographical features • birth day, birth year, birth place and occupation • use bottom-up centroid agglomerative clustering for disambiguation • vectors for each document are generated by using the following • all words (plain) or proper nouns (nnp) • most relevant words (mi and tf-idf) • basic biographical features (feat) • extended biographical features (extfeat)
Corpus, Evaluation, and Results • Mann and Yarowsky • Pseudoname corpus • query Google with names of 8 people • take 28 possible pairs and replace with different pseudonames • Naturally occurring corpus • query for 4 naturally occurring polysemous names • example: Jim Clark • 60 articles for each name • 3-way classification (top 2 occurring people + “others”) • Disambiguating accuracy for Pseudonames • 86.4% with nnp+feat+tf-idf • For naturally occurring corpus • using mutual information 88% Precision and 73% Recall
Niu, Li, and Srihari, 2004 - use 3 different categories of contextual features • set of 50 words centered around name (or alias) • other entities occurring in 50 word context of name (or alias) • automatic extracted relationships (25 possible) • birth day, age, affiliation, title, address, degree, etc. • features combined using Maximum Entropy Model • Evaluation using B-CUBED algorithm • 4 sets of 4 famous names mixed together using pseudonames • 88% F-Measure achieved • 2 naturally occurring sets • Peter Sutherland – 96% F-Measure • John Smith – 85% F-Measure
Dozier and Zielund, 2004 • CDC for people in legal domain • attorneys, judges, and expert witnesses • Combine IE techniques with record linkage techniques • biographical records for attorneys and judges created manually from Westlaw Legal Directory • biographical record for expert witnesses created through text mining • IE techniques extract templates associated with each type from document • record linkage part uses Bayesian network to match templates with biographical records • Evaluation • for docs with stereotypical syntax and full names – 98% precision and 95% recall • Otherwise, 95% precision and 60% recall
Baseline • Guha and Garg, 2004 • established baseline when full docs were compared using TF-IDF without considering context for 26 entities (names and places) • 2-6 instances of each entity considered • for each instance, top 10 results evaluated • 22.5% accuracy overall
Types of CDC • Named Entities • described earlier • Terms or Concept • Kazi and Ravin, 2000 • Events • Bagga and Baldwin, 1999 • Cross-Media and/or Multimedia Coreference • Between text and pictures for names (Bagga and Hu, unpublished) • Between text and video for names (Satoh and Kanade, 1997) • Between video streams (using image and text) for events (Bagga, Hu, and Zhong, 2002) • Cross-Language, Cross-Document Coreference • parallel corpus (Harabagiu and Maiorano, 2000) • non-parallel corpus – open problem, although manual results encouraging (Bagga and Baldwin, unpublished)
Term or Concept CDC • Single or multi-word terms refer to concepts occurring in domain • Multi-word terms • identified by Terminator (rule-based) • form subset of noun phrases in document • discard those that occur only once in document • for example: price rose where rose is mistakenly identified as noun • discard those that are found only as proper sub-strings • for example: dimension space (part of lower dimension space) • are seldom ambiguous and are merged across documents
Single Word Terms • Capitalized single words are most common sources of ambiguity • for example: Wired – name of magazine and an adjective that is first word in sentence • Within-doc categorization of single words • If capitalized word occurs in lowercase in document – consider as regular word • If capitalized word appears as capitalized in middle of sentence – consider as name • If no lowercase occurrences and word appears at beginning of sentence or in title/header - consider as term • All other single words not identified as part of name or multi-word terms – consider as lower-case term
Disambiguating Single Words Across Documents Unambiguous cases – no merging Ambiguous cases – merge if only name or only lower-case term found in corpus
Single occurrences of single capitalized terms can be merged with occurrences of corresponding names if names occur more than once in at least one document • No evaluation was performed
Event CDC • Bagga and Baldwin, 1999 • similar approach to entity-based CDC • Two events are coreferent iff the players, time, and location are the same • Event CDC system extracts as “summaries” sentences which contain: • main event verb (for example: resign) • nominalization of main verb (for example: resignation) • synonyms (for example: quit) • Summaries are clustered using single-link clustering and VSM similarity
Evaluation and Results • Articles chosen for 3 events: resignations, elections, and espionage • 2 years of New York Times data • B-CUBED algorithm used for scoring
Analysis • Events are harder than entities: • no within-document coreference • no explicit references • are at time spread over the entire document • Analysis of Elections event • elections are temporal in nature • disambiguating phrases largely use temporal references (for example – upcoming fall elections, elections last year, next elections, etc) • exposes weakness of using a bag of words approach • presence of sub-events • US General election consists of both Presidential elections and Congressional elections • “players” are the same due to high rate of incumbency • descriptions of events are very similar • issues in every election are similar (inflation, unemployment, economy)
Cross-Media Coreference – Between Text and Video (Names) • Satoh and Kanade, 1997 • Association of face and name in video • given unknown face, infer name or, • given name, guess faces which are likely to have that name • Use closed caption transcripts and video images for correlation
Face extraction: neural-network based face detector to locate faces in images • Name candidate extraction: use Oxford Text Archive dictionary (appx 70k words) • Word is considered to be a proper noun if • annotated as one in dictionary • not found in dictionary • Face similarity: eigenvector based method to compute distance between two faces • Face and name co-occurrence: use co-occurrence factor • captures how well name and face co-occur in time
Corpus, Evaluation, and Results • No large scale evaluation done • Problem with technique: false positives • specially for famous people • Clinton mentioned by news anchor repeatedly • name gets associated with news anchor
Between Text and Pictures (Names) • Bagga and Hu, unpublished (2004) • Algorithm • Use text and image based features to identify coreference • Tested on web pages • Text narrowed by extracting sentences containing name variants of entity • Image features computed by analyzing distribution of colors in L*a*b perceptual color space • Across URLs, first compute text similarity (VSM) and image similarity (L*a*b) and then combine
Preliminary Results Portraits of Captain John Smith Maps related to Captain John Smith’s explorations Captain John Smith as portrayed in the movie Pocahontas
Cross-Media Coreference • Goal: identify and track “important” news events in broadcast news video • Observations: • “important” stories of the day are repeated within/across stations • common footage scenes can be used as representative clips for these stories
News Story 1 Story 2 Commercial Segment 1 Story seg. 3 Story seg. 2 Story seg. 1 Scene 2 Scene 3 Scene 1 Scene 4 Scene 5 Scene 6 Scene 7 images images images sound sound sound Closed Caption Closed Caption Closed Caption Structure of Broadcast News
Methodology • For each video source, use closed caption text: • to identify segment boundaries (>> signs indicate speaker change) • identify and eliminate commercial segments (based upon text-tiling method) • cluster story segments into stories • Use complete link, hierarchical clustering to identify overlapping stories between programs • identify common footage scenes between each pair of overlapping stories
key frames Scenes from video source 1 text Visual similarity Overlapping Story Combined- Media clustering key frames Scenes from video source 2 text Text similarity Common Footages Common Footage Detection
CBS 3873 NBC 3885 NBC 5061 CBS 2829 Flood rescue -> rescue school bus NBC 20805 CBS 38805 US submarine->US submarine incident CBS 13833 NBC 16317 Topic: US/Iraq->US bombing of Iraq. CBS 4125 NBC 7377 CBS 4257 Examples – Found by System News conference On Iraqi bombing
Night at Baghdad->night bombing at Iraq. CBS 2253 NBC 4173 Iraqi map CBS 2001 NBC 3177 UN cars->UN inspectors leaving Iraq Found by algorithm, but missed by human subjects CBS 5193 NBC 30021 More Examples Same stories and similar key-frame images, but not really identical footage.
US submarine incident. Missed because weak text link and image intensity change. CBS 13305 NBC 16977 CBS 501 Missed by system False positive: Death of Dale Earnhardt