General Purpose Processor
General Purpose Processor. Introduction. General-Purpose Processor Processor designed for a variety of computation tasks Low unit cost, in part because manufacturer spreads NRE over large numbers of units Motorola sold half a billion 68HC05 microcontrollers in 1996 alone


General Purpose Processor
E N D
Presentation Transcript
Introduction • General-Purpose Processor • Processor designed for a variety of computation tasks • Low unit cost, in part because manufacturer spreads NRE over large numbers of units • Motorola sold half a billion 68HC05 microcontrollers in 1996 alone • Carefully designed since higher NRE is acceptable • Can yield good performance, size and power • Low NRE cost for Embedded system designer, short time-to-market/prototype, high flexibility • User just writes software; no processor design
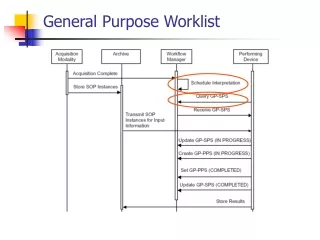
Processor Control unit Datapath ALU Controller Control /Status Registers PC IR I/O Memory Basic Architecture • Control unit and datapath • Similar to single-purpose processor • Key differences • Datapath is general • Control unit doesn’t store the algorithm – the algorithm is “programmed” into the memory
+1 Datapath Operations • Load • Read memory location into register Processor Control unit Datapath ALU • ALU operation • Input certain registers through ALU, store back in register Controller Control /Status Registers • Store • Write register to memory location 10 11 PC IR I/O ... Memory 10 11 ...
Processor Control unit Datapath ALU Controller Control /Status Registers PC IR R0 R1 I/O ... Memory 100 load R0, M[500] 500 10 101 inc R1, R0 501 ... 102 store M[501], R1 Control Unit • Control unit: configures the datapath operations • Sequence of desired operations (“instructions”) stored in memory – “program” • Instruction cycle – broken into several sub-operations, each one clock cycle, e.g.: • Fetch: Get next instruction into IR • Decode: Determine what the instruction means • Fetch operands: Move data from memory to datapath register • Execute: Move data through the ALU • Store results: Write data from register to memory
Processor Fetch ops Store results Control unit Datapath Fetch Decode Exec. ALU Controller Control /Status Registers 10 PC IR R0 R1 load R0, M[500] I/O ... Memory 100 load R0, M[500] 500 10 101 inc R1, R0 501 ... 102 store M[501], R1 Instruction Cycles PC=100 clk 100
Processor Control unit Datapath ALU Controller +1 Control /Status Registers Fetch ops Store results Fetch Decode Exec. 11 PC IR R0 R1 inc R1, R0 I/O ... Memory 100 load R0, M[500] 500 10 101 inc R1, R0 501 ... 102 store M[501], R1 Instruction Cycles PC=100 Fetch ops Store results Fetch Decode Exec. clk PC=101 clk 10 101
Processor Control unit Datapath ALU Controller Control /Status Registers PC IR R0 R1 store M[501], R1 Fetch ops Store results Fetch Decode Exec. I/O ... Memory 100 load R0, M[500] 500 10 101 inc R1, R0 501 11 ... 102 store M[501], R1 Instruction Cycles PC=100 Fetch ops Store results Fetch Decode Exec. clk PC=101 Fetch ops Store results Fetch Decode Exec. clk 10 11 102 PC=102 clk
Processor Control unit Datapath ALU Controller Control /Status Registers PC IR I/O Memory Architectural Considerations • N-bit processor • N-bit ALU, registers, buses, memory data interface • Embedded: 8-bit, 16-bit, 32-bit common • Desktop/servers: 32-bit, even 64 • PC size determines address space
Processor Control unit Datapath ALU Controller Control /Status Registers PC IR I/O Memory Architectural Considerations • Clock frequency • Inverse of clock period • Must be longer than longest register to register delay in entire processor • Memory access is often the longest
ARM Introduction
ARM RISC Design Philosophy • Smaller die size • Shorter Development time • Higher performance • Insects flap wings faster than small birds • Complex instruction will make some high level function more efficient but will slow down the clock for all instructions
ARM Design philosophy • Reduce power consumption and extend battery life • High Code density • Low price • Embedded systems prefer slow and low cost memory • Reduce area of the die taken by embedded processor • Leave space for specialized processor • Hardware debug capability • ARM is not a pure RISC Architecture • Designed primarily for embedded systems
Instruction set for embedded systems • Variable cycle execution for certain instructions • Multi registers Load-store instructions • Faster if memory access is sequential • Higher code density – common operation at start and end of function • Inline barrel shifting – leads to complex instructions • Improved code density • E.g. ADD r0,r1,r1, LSL #1
Instruction set for embedded systems • Thumb 16 bit instruction set • Code can execute both 16 or 32 bit instruction • Conditional execution • Improved code density • Reduce branch instructions • CMP r1,r2 • SUBGT r1,r1,r2 • SUBLT r2,r2,r1 • Enhanced instructions – DSP Instructions • Use one processor instead of traditional combination of two
Peripherals • ALL ARM Peripherals are Memory Mapped • Interrupt Controllers • Standard Interrupt Controller • Sends a interrupt signal to processor core • Can be programmed to ignore or mask an individual device or set of devices • Interrupt handler read a device bitmap register to determine which device requires servicing • VIC- Vectored interrupt controller • Assigned priority and ISR handler to each device • Depending on type will call standard Int. Hand. Or jump to specific device handler directly
ARM Datapath • Registers • R0-R15 General Purpose registers • R13-stack pointer • R14-Link register • R15 – program counter • R0-R13 are orthogonal • Two program status registers • CPSR • SPSR
ARM’s visible registers r0 usable in user mode r1 r2 r3 system modes only r4 r5 r6 r7 r8_fiq r8 r9_fiq r9 r10_fiq r10 r1 1_fiq r1 1 r13_und r12_fiq r13_irq r12 r13_abt r13_svc r14_und r13_fiq r14_irq r13 r14_abt r14_svc r14_fiq r14 r15 (PC) SPSR_und SPSR_irq SPSR_abt CPSR SPSR_svc SPSR_fiq svc abort irq undefi ned fiq user mode mode mode mode mode mode
BANK Registers • Total 37 registers • 20 are hidden from program at different time • Also called Banked Registers • Available only when processor in certain mode • Mode can be changed by program or on exception • Reset, interrupt request, fast interrupt request software interrupt, data abort, prefetch abort and undefined instruction • No SPSR access in user mode
CPSR • Condition flags – NZCV • Interrupt masks – IF • Thumb state- T , Jazelle –J • Mode bits 0-4 – processor mode • Six privileged modes • Abort – failed attempt to access memory • Fast interrupt request • Interrupt request • Supervisor mode – after reset, Kernel work in this mode • System – special version of user mode – full RW access to CPSR • Undefined mode – when undefined or not supported inst. Is exec. • User Mode
3 Stage pipeline ARM Organization • Fetch • The instruction is fetched from the memory and placed in the instruction pipeline • Decode • The instruction is decoded and the datapath control signals prepared for the next cycle. In this stage inst. ‘Owns’ the decode logic but not the datapath • Execute • The inst. ‘owns’ the datapath; the register bank is read, an operand shifted, the ALU result generated and written back into a destination register.
PC Behavior • R15 increment twice before an instruction executes • due to pipeline operation • R15=current instruction address+8 • Offset is +4 for thumb instruction
To get Higher performance • Tprog=(Ninst X CPI ) / fclk • Ninst – No of inst. Executed for a program–Constant • Increase the clock rate • The clock rate is limited by slowest pipeline stage • Decrease the logic complexity per stage • Increase the pipeline depth • Improve the CPI • Instruction that take more than one cycle are re-implemented to occupy fewer cycles • Pipeline stalls are reduced
Typical Dynamic Instruction usage Statistics for a print preview program in an ARM Inst. Emulator
Memory Bottleneck • Von Neumann Bottleneck • Single inst and data memory • Limited by available memory bandwidth • A 3 stage ARM core accesses memory on (almost) every clock • Harvard Architecture in higher performance arm cores
The 5 stage pipeline • Fetch • Inst. Fetched and placed in Inst. Pipeline • Decode • Inst. Is decoded and register operand read from the register file • Execute • An operand is shifted and the ALU result generated. For load and store memory address is computed • Buffer/Data • Data Memory is accessed if required otherwise ALU result is simply buffered • Write Back • The results are written back to register file
Data Forwarding • Read after write pipeline hazard • An instruction needs to use the result of one of its predecessors before that result has returned to the register file • e.g. Add r1,r2,r3 • Add r4,r5,r1 • Data forwarding is used to eliminate stall • In following case even with forwarding it is not possible to avoid a pipeline stall • E.g LDR rN, [..] ; Load rN from somewhere • ADD r2,r1,rN ; and use it immediately • Processor cannot avoid one cycle stall
Data Hazards • Handling data hazard in software • Solution- Encourage compiler to not put a depended instruction immediately after a load instruction • Side effects • When a location other than one explicitly named in an instruction as destination operand is affected • Addressing modes • Complex addressing modes doesn’t necessarily leads to faster execution • E.g. Load (X(R1)),R2 • Add #X,R1,R2 • Load (R2),R2 • Load (R2),R2
Data Hazards • Complex addressing • require more complex hardware to decode and execute them • Cause the pipeline to stall • Pipelining features • Access to an operand does not require more than one access to memory • Only load and store instruction access memory • The addressing modes used do not have side effects • Register, register indirect, index modes • Condition codes • Flags are modified by as few instruction as possible • Compiler should be able to specify in which instr. Of the program they are affected and in which they are not
Complex Addressing Mode Load (X(R1)), R2 T ime Clock c ycle 1 2 3 4 5 6 7 Load F D X + [R1] [X + [R1]] [[X + [R1]]] W F orw ard Ne xt instruction F D E W (a) Complex addressing mode
Simple Addressing Mode Add #X, R1, R2 Load (R2), R2 Load (R2), R2 Add F D X + [R1] W Load F D [X + [R1]] W Load F D [[X + [R1]]] W Ne xt instruction F D E W (b) Simple addressing mode
Instruction hazards - Overview • Whenever the stream of instructions supplied by the instruction fetch unit is interrupted, the pipeline stalls. • Cache miss • Branch
Branch Timing - Branch penalty - Reducing the penalty
Instruction Queue and Prefetching Instruction fetch unit Instruction queue F : Fetch instruction D : Dispatch/ E : Ex ecute W : Write Decode instruction results unit Figure 8.10. Use of an instruction queue in the hardware organization of Figure 8.2b.
Branch Timing with Instruction Queue T ime Clock c ycle 1 2 3 4 5 6 7 8 9 10 Queue length 1 1 1 1 2 3 2 1 1 1 Branch folding F D E E E W I 1 1 1 1 1 1 1 F D E W I 2 2 2 2 2 F D E W I 3 3 3 3 3 F D E W I 4 4 4 4 4 F D I (Branch) 5 5 5 F X I 6 6 F D E W I k k k k k F D E I k+ 1 k+ 1 k+ 1 k+ 1 Figure 8.11. Branch timing in the presence of an instruction queue. Branch target address is computed in the D stage.
Branch Folding • Branch folding – executing the branch instruction concurrently with the execution of other instructions. • Branch folding occurs only if at the time a branch instruction is encountered, at least one instruction is available in the queue other than the branch instruction. • Therefore, it is desirable to arrange for the queue to be full most of the time, to ensure an adequate supply of instructions for processing. • This can be achieved by increasing the rate at which the fetch unit reads instructions from the cache. • Having an instruction queue is also beneficial in dealing with cache misses.
Conditional Braches • A conditional branch instruction introduces the added hazard caused by the dependency of the branch condition on the result of a preceding instruction. • The decision to branch cannot be made until the execution of that instruction has been completed. • Branch instructions represent about 20% of the dynamic instruction count of most programs.
Delayed Branch • The instructions in the delay slots are always fetched. Therefore, we would like to arrange for them to be fully executed whether or not the branch is taken. • The objective is to place useful instructions in these slots. • The effectiveness of the delayed branch approach depends on how often it is possible to reorder instructions.
Delayed Branch LOOP Shift_left R1 Decrement R2 Branch=0 LOOP NEXT Add R1,R3 (a) Original program loop LOOP Decrement R2 Branch=0 LOOP Shift_left R1 NEXT Add R1,R3 (b) Reordered instructions Figure 8.12. Reordering of instructions for a delayed branch.
Delayed Branch T ime Clock c ycle 1 2 3 4 5 6 7 8 Instruction Decrement F E Branch F E Shift (delay slot) F E Decrement (Branch tak en) F E Branch F E Shift (delay slot) F E Add (Branch not tak en) F E Figure 8.13. Execution timing showing the delay slot being filled during the last two passes through the loop in Figure 8.12.
Branch Prediction • To predict whether or not a particular branch will be taken. • Simplest form: assume branch will not take place and continue to fetch instructions in sequential address order. • Until the branch is evaluated, instruction execution along the predicted path must be done on a speculative basis. • Speculative execution: instructions are executed before the processor is certain that they are in the correct execution sequence. • Need to be careful so that no processor registers or memory locations are updated until it is confirmed that these instructions should indeed be executed.
Incorrectly Predicted Branch T ime 1 2 3 4 5 6 Clock cycle Instruction I (Compare) F D E W 1 1 1 1 1 I (Branch>0) F D /P E 2 2 2 2 2 I F D X 3 3 3 I F X 4 4 I F D k k k Figure 8.14. Timing when a branch decision has been incorrectly predicted as not taken.
Branch Prediction • Better performance can be achieved if we arrange for some branch instructions to be predicted as taken and others as not taken. • Use hardware to observe whether the target address is lower or higher than that of the branch instruction. • Let compiler include a branch prediction bit. • So far the branch prediction decision is always the same every time a given instruction is executed – static branch prediction.