Understanding the Cocke-Kasami-Younger Algorithm for Bottom-Up Parsing of CFG in CNF
The Cocke-Kasami-Younger (CKY) Algorithm is a dynamic programming approach used for parsing context-free grammars (CFG) in Chomsky Normal Form (CNF). This example illustrates how to efficiently derive the substring divisions of a given string using a parsing table, where non-terminals are filled based on production rules. This method provides a systematic way to determine whether a string belongs to the language generated by the CFG, operating within a time complexity proportional to n³. Understanding the CKY algorithm is crucial for automating syntax analysis in compilers and interpreters.

Understanding the Cocke-Kasami-Younger Algorithm for Bottom-Up Parsing of CFG in CNF
E N D
Presentation Transcript
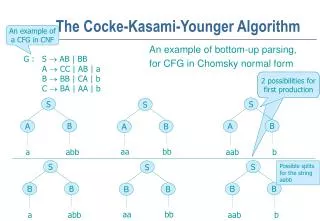
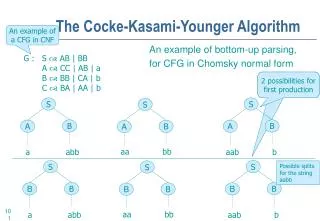
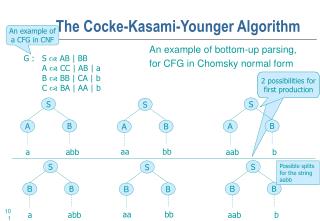
The Cocke-Kasami-Younger Algorithm An example of a CFG in CNF An example of bottom-up parsing, for CFG in Chomsky normal form G : S AB | BB A CC | AB | a B BB | CA | b C BA | AA | b 2 possibilities forfirst production S S S B B A A B A aa bb a abb aab b S S S Possible splits for the string aabb B B B B B B aa bb a abb aab b
The CKYounger Algorithm Provides an efficient way of generating substring devisions and checking whether each substring can be legally derived Thus if the cell (4,1) contains S, string L(G) A non terminal will be placed in the cell (i,j) if it can derive i consecutive symbolsof the string starting at jth position If the cell (i,j) contains the nonterminal A1 and the cell (i’,i+j) contains the nonterminal A2 and there is a production A A1 A2 then the cell (i+i’,j) will contain the nonterminal A
The CKYounger Algorithm Provides an efficient way of generating substring devisions and checking whether each substring can be legally derived G : S AB | BB A CC | AB | a B BB | CA | b C BA | AA | b A nonterminal will be placed in the cell (i,j) if it can derive i consecutive symbolsof the string starting at jth position
The Cocke-Kasami-Younger Algorithm Relation derivation tree and pyramid S S S B A B A B A aa bb aab b a abb
S S S B B B B B B aa bb a abb aab b
The Cocke-Kasami-Younger Algorithm Builds up the pyramid in a bottom-up fashion G : S AB | BB A CC | AB | a B BB | CA | b C BA | AA | b Step 1, fill the cell at row 1 Because of A a Because of B b, and C b
The Cocke-Kasami-Younger Algorithm Builds up the pyramid in a bottom-up fashion G : S AB | BB A CC | AB | a B BB | CA | b C BA | AA | b B is in cell (2,3) Because of B BB and B is in cell (1,3) and B is in cell (1,4) Step 2, fill the cell at row 2 C is in cell (2,1) Because of C AA and A is in cell (1,1) and A is in cell (1,2) A is in cell (2,2) Because of A AB and A is in cell (1,2) and B is in cell (1,3) S is in cell (2,3) Because of S BB and B is in cell (1,3) and B is in cell (1,4)
The Cocke-Kasami-Younger Algorithm Builds up the pyramid in a bottom-up fashion G : S AB | BB A CC | AB | a B BB | CA | b C BA | AA | b C is in cell (3,1) Because of C AA and A is in cell (1,1) and A is in cell (2,2) Step 3, fill the cell at row 3 ? is in cell (3,1) Because of ? XY X is in cell (1,1) Y is in cell (2,2) or X is in cell (2,1) Y is in cell (1,3) or A is in cell (3,1) Because of C CC and C is in cell (2,1) and C is in cell (1,3)
The Cocke-Kasami-Younger Algorithm Builds up the pyramid in a bottom-up fashion G : S AB | BB A CC | AB | a B BB | CA | b C BA | AA | b Since S is at the top, aabb L(G) Step 4, fill the cell at row 4 S General rule ? is in cell (i,j) Because of ? XY X is in cell (m,j) Y is in cell (i-m,j+m) with 1 m i-1 Step i B A b C C A A b a a
Theorem The CKY algorithm is correct Given a grammar (T, N, P, S) in Chomsky normal form and w = x1...xn T* then A N is in cell (i,j) of the CKY pyramid if and only if A xj...xj+i-1 Proof by induction on the row number Base step i= 1 in row 1 we get the nonterminals from which length 1 substrings of the string to parse can be derived. This is only possible by using productions of type A a. Thus if A is in cell (1,i), 1 i n, then A xi P, thus A xi Induction hypothesis theorem applies for all rows < i, i.e. all substrings of length < i. * *
Induction step we first prove Assume a derivation of a substring of length i, i>1, A BC xj...xj+i-1, then for some m > 0there must hold that B xj...xj+m-1 andC xj+m...xj+i-1. Thus by the induction hypothesis if B is in cell (m,i) and C in the cell (i-m, j+m). Since there is a production A BC, A is in the cell (m,i). We now prove Assume A is in the cell (i,j), then form A we can derive a string xj...xj+i-1, with length i > 1, therefore there must be a production of the form A BC with B,C N, and for some m, 1 m i-1, B is in cell (m,j) and C in the cell (i-m, j+m). By the induction hypothesis we have B xj...xj+m-1 and C xj+m...xj+i-1. Therefore we can write A BC xj...xj+i-1 and conclude A xj...xj+i-1 * * * * * Both cells have a lower row #, so induction hypothesis applies
The complexity of the CKY algorithm The time complexity for wL(G)? • Let G = (T, N, P, S) be a CFG in Chomsky normal form, with k = #N. • Then using the CKY algorithm, wL(G) can be decided in time proportional to n3 , • where n = |w|. • Proof • First notice that • the number of entries in a cell is at most k. • maximum number of productions is k3, • I Complexity for row 1 cells • For each A N, we have to check if it can be placed in cell(1,i), i.e. if A derives (in 1 step) • the terminal on position i. There are k nonterminals, thus cost per cell is k X 1. • There are n row 1 cells, thus total cost for row 1 = kn. Each nonterminal can only occur once in a cell A BC Cfr. 3
II Complexity for cell in a row > 1 The content of a cell is the result of at most n-1 pairings of lower cells. For each paring at most k nonterminals are paired with at most k other nonterminals, and each pairing is checked against at most k3 productions. Thus for each cell : cost k X k X k3 X1X(n-1) =k5 X(n-1) There are (n-1)+ (n-2) + …. + 1 = n(n-1)/2 cells in rows 2 to n, thus total cost for these rows is bounded above by n(n-1)/2 Xk5 X(n-1) To conclude : The total cost is bounded above by : kn + n(n-1)/2 Xk5 X(n-1) See slide 119 Cfr. 1 and 2 Since k is independent of n the conclusion is O(n3)
Some remarks • Not really of practical use since • O(n3) is to slow • the grammar must be converted to CNF • only tests membership, this is not the complexity for building the derivation tree See course on compilers for faster algorithms Semantics!!!! To think about : CKY and unambiguous grammars.