在庫管理問題の動的計画法による 解法と CUDA を用いた高速化
在庫管理問題の動的計画法による 解法と CUDA を用いた高速化. SACSIS2008 2008 年 6 月 12 日 李天 * 1 河畠工 * 1 山本有作 * 1 畝山多加志 * 2 張紹良 * 1. *1 名古屋大学大学院工学研究科 計算理工学専攻 * 2 京都大学化学研究所. もくじ. 1 . はじめに 2 . 問題設定 3 . 動的計画法による解法 4 . GPGPU のための統合環境 CUDA 5 . 動的計画法の CUDA による高速化 6 . 性能評価 7 . おわりに. 1 . はじめに.


在庫管理問題の動的計画法による 解法と CUDA を用いた高速化
E N D
Presentation Transcript
在庫管理問題の動的計画法による解法とCUDA を用いた高速化 SACSIS2008 2008年6月12日 李天*1河畠工*1山本有作*1畝山多加志*2張紹良*1 *1 名古屋大学大学院工学研究科 計算理工学専攻 *2 京都大学化学研究所
もくじ 1. はじめに 2. 問題設定 3. 動的計画法による解法 4.GPGPUのための統合環境CUDA 5. 動的計画法のCUDAによる高速化 6. 性能評価 7. おわりに
1. はじめに • GPU(Graphics Processing Unit)の高速化 • CPUを大きく上回るペースで演算性能が向上 • グラフィックスメモリも大容量化・高速化 nVIDIA社 GeForce8800GTX ・ 128個のストリーミングプロセッサ ・ 演算性能: 345GFLOPS(単精度) ・ メモリ: 768MB ・ メモリバンド幅: 86.4GB/s GPUを汎用の数値計算に使うGPGPU(General-Purpose GPU)が注目を集める
従来のGPGPUの問題点 • 特殊なプログラミング手法が必要 • グラフィックスAPI • ストリーム言語 • GPUの内部構造に関する情報が乏しい • データアクセス(特に書き込み)に関する強い制限 プログラム開発者にとって敷居が高い
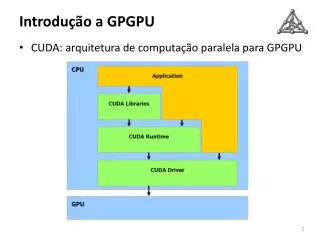
GPGPUのための統合環境CUDA • nVIDIA社のGPU上でGPGPUを実現するため,2006年に同社が発表した統合プログラミング環境 • 特徴 • 標準のC言語 + 簡単な拡張でGPUのプログラミングが可能 • 標準により近いメモリモデル • スレッド並列による多数のストリーミングプロセッサの利用 • nVIDIA社の最新GPU向けの最適化機能 • チューニングのための情報が豊富 • 詳細なマニュアル • Web上のフォーラム GPUの性能を引き出すプログラミングが,従来に比べ 格段に簡単化
CUDAの利用例 • 行列計算 • FFT • 重力多体計算 • 分子軌道法 • 気象予測 • 画像処理 • データマイニング • バイオインフォマティクス Cf. http://www.nvidia.com/object/cuda_showcase.html#apps
本研究の目的 • ある組合せ最適化問題をCUDAで高速化 • 企業の現場で現れる在庫管理計画問題 • 動的計画法による解法をベースとする • 実用的な時間での求解を目指す • 動的計画法を用いた最適化が,GPU向きの計算であることを明らかにする • 多数の応用(ポートフォリオ最適化,オプション価格評価など)
2. 問題設定 • 在庫管理計画問題 • N日の間,毎日トラックで来る原料を,K個ある倉庫のどれかに搬入 • 各倉庫中の原料は,毎日少しずつ搬出され,工場で消費される。 • 各倉庫の充填率が上下限に近づきすぎないよう搬入先を予め計画 充填率の変化の例 (K=5,N=90の場合)
数学的定式化 • 変数と定数 • 充填率の変化を表す式 • 目的関数 ペナルティ関数 0% 100% 50% min {j(n)}n=1N
問題の特徴と解法の候補 • 問題の特徴 • 独立変数 {j(n)}n=1Nが整数値のみを取る組合せ最適化問題 • K=5,N=90(実問題のサイズ)の場合,可能な組合せは 590と膨大 • 解法の候補 • 0-1整数計画法 • メタヒューリスティクス • 動的計画法
3. 動的計画法による解法 • n日目以降の部分目的関数 • n日目以降に最適戦略を取った場合の部分目的関数(価値関数) • G(n)の満たす漸化式(Bellman方程式) Bellman方程式を用いて,各状態に対する G(n)と j(n)を最終日から遡って決めていくことが可能(後ろ向き計算)
動的計画法の図解(K=2の場合) <N–1日目> ・各格子点において次の処理を行う。 ①各選択肢に対してN日目の充填率( , )を求め、ペナルティ値を計算 ②ペナルティ値の少ない方の選択肢を選ぶ。 ③その格子点における G(N–1)として、最適な選択とともに保存 100% 50% 1日目 0% 100% 50% N-2 日目 N-1 日目 N 日目
動的計画法の図解(K=2の場合) <N–2日目> ・各格子点において次の処理を行う。 ① 各選択に対してN–1日目の充填率( , )を計算 ② N–1日目におけるペナルティ値を計算 ③ ( , )より、 N–1日目以降の部分目的関数値を求める。 ④ ②+③の小さい方を選ぶ。 ⑤ その格子点における G(N–2)として、最適な選択とともに保存 1日目 N-2 日目 N-1 日目 N 日目
離散化と補間 • 離散化 • 計算を行うため,充填率の空間(状態空間)を格子に分割 • 以下,各方向の格子点数をLとする。 • 補間 • 各選択に対して計算したN–1日目の充填率 ( , )は格子点上にあるとは限らない。 • N–1日目以降の目的関数を求める際は,隣接する2K個の格子点での目的関数値を用いて多重線形補間を行う。 (N-2日目) (N-1日目)
最適計画の作成 1日目 2日目 3日目 N・最終日 時間軸 <前向き計算> ・最終日から初日まで遡って計算すると,全ての日,全ての格子点について最適な選択が与えられる。 ・その後,初期の充填率から出発し,順方向に進んで各日の選択を決めていく。 ・格子点上にない点の場合は最も近い格子点での最適な選択を利用 ② ①
状態空間の次元縮小 • 充填率の変化を表す式 について,kとnに関する和を取り, を用いると, 右辺は定数だから,これはK個の充填率のうちK–1個のみが独立であることを示す。 • これを用いて,状態空間の次元を1だけ縮小可能
アルゴリズム(K=4, 後ろ向き計算の部分のみ) 時間に関する後ろ向きループ 格子点に関するK–1重ループ K通りの選択肢のうちで最適な選択 j を求め, j とそのときの G(n)と を保存 (各格子点ごとに完全に独立な計算) 計算量: O(NLK–1K2)
動的計画法による解法の特徴 • 計算量が O(NLK–1K2),メモリ量が O(LK–1) と大きい • K=5,N=90,L=80の実問題の場合,Core2Duo で90分程度 • 実務上は数分程度で計算できることが望ましい • 所要メモリは約400MB • 並列性は極めて高い • LK–1 個の格子点での計算が完全並列 • 計算は単精度で十分 • 主要な誤差は離散化誤差 • 丸め誤差は無視できる • メモリバンド幅に対する要求が高い • 計算量の大部分を占める補間演算では,演算量とアクセス回数は同程度
4.GPGPUのための統合環境CUDA • CUDAのプログラミングモデル • CPUのmain関数から,GPUで実行されるカーネルを呼び出す • CPUとGPUのメモリ空間は別々。cudaMemcpy関数でデータ転送 • ブロックとスレッドによる並列化 • 多数のスレッドを時分割で実行し,GPUメモリのレイテンシを隠蔽
CUDAのメモリモデル • メモリ階層 • 全スレッドでの共有メモリ • グローバルメモリ • 定数メモリ(キャッシュあり) • テクスチャメモリ(キャッシュあり) • ブロックごとの共有メモリ • スレッド毎のローカルメモリ • レジスタ • カーネル中でのスレッド間同期 • ブロック内では同期可能 • ブロック間では同期不可 本応用では問題なし
チューニングの指針 • データ参照の局所性向上 • 共有メモリ,定数メモリ,レジスタの活用 • スレッド数をできるだけ多くする • CPUメモリとの間のデータ転送の最小化 • IF文の排除 • スレッドは32個単位でSIMD形式で並列実行 • IF文は両方の分岐が逐次的に実行される • メモリアクセスの連続化 • 連続する番号を持つスレッドが連続領域をアクセスするようにする • メモリアラインメントの条件を満たすようにする
5. 動的計画法のCUDAによる高速化 • 動的計画法とCUDAの親和性 動的計画法は極めてCUDA(GPGPU)向きのアルゴリズム
CUDAでの実装 • GPUによる実行部分 • 後ろ向き計算の1日分をカーネルとしてGPUで実行 • カーネルをN回呼ぶことで,後ろ向き計算を完了 • 変数・定数のメモリ空間への割り当て • 定数 → 定数メモリ,共有メモリ • G(n),j → グローバルメモリ • スレッド毎の中間変数 → レジスタ • ブロックとスレッドによる並列化 • 格子点に関するK–1重ループのうち,最内側の2重ループをスレッド並列化に利用 (→ メモリアクセスの連続化) • その一つ外側のループをブロック並列化に利用 • CPUメモリへの転送は,配列 j のみ(最大1.8GB程度)
6. 性能評価 • 評価条件 • 提案アルゴリズムをCUDAで実装 • デュアルコアCPU上での C+pthread による実装と性能を比較 • 最大規模の問題(倉庫数 K=5,期間 N=90)で評価 • 評価環境
GPUによる速度向上効果 • 条件と結果 • スレッドの数と形状(2次元)は実験的に求めた最適値を使用 • CPU(2コア使用)に対し,最大15.6倍の高速化 • 6分で最適解を計算 計算時間 問題サイズ
得られた最適解 • 条件が厳しくない問題 • 条件が厳しい問題(倉庫の容量を最大限に利用) • L=80で初めて良好な解が得られる L=60 L=60
スレッドの数と形状の最適化 • スレッド形状(2次元)の候補 • 格子サイズに合わせる(無駄なスレッドをなくす) • 第1方向を32の倍数とする(メモリアラインメントの重視) • 結果 • どちらかが常に良いとは言えないが,メモリアラインメントを重視した場合は安定した性能が得られる。
7. おわりに • 本研究のまとめ • 在庫管理計画問題の動的計画法による解法を,CUDAを用いてGPU上で実装した。 • GeForce8800GTX を用いた評価では,最大規模の問題の場合,Core2Duo の15倍の高速化が得られ,目標計算時間を達成した。 • 今後の課題 • GPU上での実行時間の詳細な解析 • より高度なチューニング • 共有メモリの活用 • GPUの補間機能の活用 • より大規模な問題への適用 • 強化学習の利用など • 他の最適化問題への適用 • ポートフォリオ最適化,オプション価格評価など