Download

1 / 86
870 likes | 1.37k Views
4 Principal Component Analysis (PCA). Principal Component Analysis (PCA). PCA ✔ PCA in high dimensional space Nonlinear PCA Kernel PCA KL expansion 2D-PCA. 主分量. Dimension Reduction. 农作物. Dimension Reduction. 语言. Intuition. Intuition (Continued). Principal Component Analysis.

E N D
Principal Component Analysis (PCA) • PCA ✔ • PCA in high dimensional space • Nonlinear PCA • Kernel PCA • KL expansion • 2D-PCA
Principal Component Analysis • A method for re-expressing multivariate data. It allows the researchers to reorient the data so that the first few dimensions account for as much information as possible. • Useful in identifying and understanding patterns of association across variables.
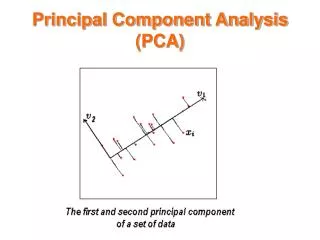
Principal Component Analysis • The first principal component, denoted Z1, is given by the linear combination of the original variables X=[X1,X2,…,Xp] with the largest possible variance.
Mechanics Let z=Xu where X=[X1,X2,…,Xp], u=(u1,u2,…,up)’. Then, we have Var(z)=u’Su where S=var(X). The problem thus can be stated as follows:
Mechanics (Continued) The Lagrangian is given by L=u’ Su-λ(u’u-1) where λ is called the Lagrange multiplier. Taking the deviative of L with respect to the elements of u yields
Eigenvalue-Eigenvector Equation S u = λu where • the scalarλ is called an eigenvalue • the vector u is called an eigenvector • the square matrix S is the covariance matrix of row random vector X, and can be estimated by the mean-differenced data matrix Xdas follows:
Principal Component Analysis(Cont’d) • The second principal component, denoted Z2, is given by the linear combination of X that accounts for the most information (highest variance) not already captured by Z1; that is, Z2 is chosen to be uncorrelated with Z1. • All subsequent principal components Z3, …, Zc are chosen to be uncorrelated with all previous principal components.
Standardizing The Data Because principal component analysis seeks to maximize variance, it can be highly sensitive to scale difference across variables. Thus, it is usually (but not always) a good idea to standardize the data and denote them Xs. Example:
Example (Continued) 红点与蓝点分别对应于基于协方差矩阵或相关系数矩阵的前两个主分量的二维数据显示.
PCs of the Standardized Data • Each eigenvector, denoted ui, represents the direction of the principal axes of the shape formed by the scatter plot of the data. • Each eigenvalue, denoted λi, is equal to the variance of the principal component zi =Xsui
PCs of the Standardized Data (Cont’d) The standardized matrix of principal components is Zs=XsUD-1/2.
PCs of the Standardized Data (Cont’d) The sum of variances of all principal components is equal to p, the number of variables in the matrix X. Thus, the proportion of variation accounted for by the first r principal components is given by ?
Principal Component Loadings The correlation corr(Xs, Zs) between the principal components Zs and the original variables Xs
Principal Component Loadings The general expression for variance accounted for in variable Xi by the first c principal components is If all PCs are retained, the sum is 1.
PCA and SVD From the standardized matrix of principal components Zs=XsUD-1/2 We obtain Xs=ZsD1/2U’ What this reveals is that any data matrix X can be expressed as the matrix products of three simpler matrices. Zs is a matrix of uncorrelated variables, D1/2 is a diagonal matrix that performs a stretching transformation, and U’ is a transformation matrix that performs an orthogonal rotation. PCA=spectral decomposition of the correlation matrix /singular value decomposition of the data
Examples [U, D, V]=svd(A) [U, D, V]=svd(A,0)
Looking around the backyard helps to recognize faces and digits Honghao Shan Cottrell, G.W. Dept. of Comput. Sci. & Eng., Univ. of California, San Diego, La Jolla, CA Human being has the ability to learn to recognize a new visual category based on only one or few training examples. Part of this ability might come from the use of knowledge from previous visual experiences. We show that such knowledge can be expressed as a set of“universal” visual features, which are learned from randomly collected natural scene images. Published in IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008), 23-28 June 2008, page(s): 1-8 人具有只学习一个或少量训练样本就能够识别该类模式的能力。该能力的一部分可能来自于已有视觉经验知识的运用。这些知识可以表示为“通用”的视觉特征,而这些视觉特征是可以从随机收集的自然场景图像中学习得到。
Principal Component Analysis (PCA) • PCA ✔ • PCA in high dimensional space ✔ • Nonlinear PCA • Kernel PCA • KL expansion • 2D-PCA
Solution and Embedding Solution: B=[v1, v2, …,vr]p×r 这里vi为第i大特征值所对应的特征向量(i=1,…,r) Embedding of a sample x: 当特征维数p很大,计算B代价很大。
Dual Formulation (I) (II) 当特征维数p远低于样本数目n时, 问题(I)求解比问题(II)求解容易得多。 反之,当特征维数p远高于样本数目n时, 问题(I)求解比问题(II)求解困难得多。
PCA in High Dimensional Space Solution: BII=[u1,u2,…,ur] 这里ui为第i大特征值所对应的特征向量(i=1,…,r) Embedding of a sample x:
Experiments: The ORL face databaseat the AT&T (Olivetti) Research Laboratory • The ORL Database of Faces contains a set of face images taken between April 1992 and April 1994 at the lab. The database was used in the context of a face recognition project carried out in collaboration with the Speech, Vision and Robotics Group of the Cambridge University Engineering Department. • There are ten different images of each of 40 distinct subjects. For some subjects, the images were taken at different times, varying the lighting, facial expressions (open / closed eyes, smiling / not smiling) and facial details (glasses / no glasses). All the images were taken against a dark homogeneous background with the subjects in an upright, frontal position (with tolerance for some side movement). • When using these images, please give credit to AT&T Laboratories Cambridge.
Programming in Matlab d=92*112; %图像象素数目 n=400; %图像数目 fileInput=sprintf('orl%05d.dat',dim); FID=fopen(fileInput,'rb'); x=fread(FID,[d,n],'double'); fclose(FID); m=mean(x'); for i=1:n xd(:,i)=x(:,i)-m'; end R=xd'*xd; [V1,D1]=eig(R); r=300; %保留主分量数目 [V, D]=mysort(V1,D1,300); U=xd*V*D^(-1/2); y=U’xd;
Reconstruction Using PCs 将中心化的数据投影 将数据直接投影
Performance of Dimension Reduction 实验:每人前5幅训练、后5幅测试
Principal Component Analysis (PCA) • PCA ✔ • PCA in high dimensional space ✔ • Nonlinear PCA ✔ • Kernel PCA • KL expansion • 2D-PCA
Examples However, PCA doesnot necessarily preserve interesting information such as clusters.
Problems with Applications From “Nonlinear Data Representation for Visual Learning” by INRIA, France in 1998.
Non-linear PCA A simple non-linear extension of linear methods while keeping computational advantages of linear methods: • Map the original data to a feature space by a non-linear transformation • Run linear algorithm in the feature space
Example • d=2