Download

1 / 26
270 likes | 526 Views
PIPP: Promotion/Insertion Pseudo-Partitioning of Multi-Core Shared Caches. Yuejian Xie, Gabriel H. Loh Georgia Institute of Technology Presented by: Yingying Tian. 36th ACM/IEEE International Symposium on Computer Architecture (ISCA ‘ 09). Manage Shared Caches.

E N D
PIPP:Promotion/Insertion Pseudo-Partitioning of Multi-Core Shared Caches Yuejian Xie, Gabriel H. Loh Georgia Institute of Technology Presented by: Yingying Tian 36th ACM/IEEE International Symposium on Computer Architecture (ISCA ‘09)
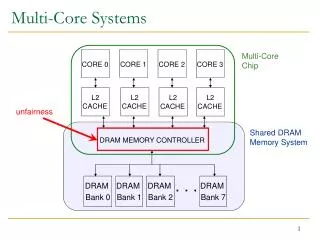
Manage Shared Caches • Last Level Caches (LLCs) are shared by all cores in Chip Multi-Processors (CMPs). • Multiple cores compete for the limited LLC capacity. Core0 Core1 L1I L1D L1I L1D Core0’s Data Core1’s Data Last Level Cache (LLC) 2
LRU leads to poor performance and fairness as a sharing-oblivious cache management policy. • Previous works tried to allocate LLC resources fairly via: • Capacity Management: way-partitioning (UCP) • Dead-Time Management: LRU insertion (TADIP) • PIPP: Do both capacity and dead time management better at the same time !
Outline • Background and Motivation • Previous Work • PIPP • Evaluation • Conclusion
UCP (Utility based Cache Partitioning) Core0 Core1 • ` Core 0 gets 5 ways Core 1 gets 3 ways *Some materials are taken from original presentation slides.
DIP (Dynamic Insertion Policy) MRU LRU Incoming Block
DIP (Dynamic Insertion Policy) MRU LRU Occupies one cache blockfor a long time with no benefit!
DIP (Dynamic Insertion Policy) MRU LRU Incoming Block
DIP (Dynamic Insertion Policy) MRU LRU
DIP (Dynamic Insertion Policy) MRU LRU
Cache Replacement Policy • Eviction: Which block should be replaced when a cache miss occurs? • LRU block • Insertion: For a coming block, where should it be inserted in the corresponding set? • MRU insertion (Default LRU replacement policy) • LRU insertion (Dead-on-arrival blocks) • Promotion: If a block is re-referenced, where should its position be adjusted? • Move to MRU position
Insert Position = 3 (Target Allocation) New Promote To Evict Hit PIPP: Promotion/Insertion Pseudo-Partitioning • Insertion: Target partitioning: ∏ = {∏1, ∏2, …., ∏n}, ∑∏i= w (w is the associativity of the cache) On insertion, corei inserts its coming block in position ∏i. (Dynamically computed via UCP monitors or other ways.) • Promotion: One step toward MRU position with P and unchanged with 1-P. MRU LRU
PIPP Example Core0’s Block Core1’s Block Core0 quota: 5 blocks Core1 quota: 3 blocks Request D Core1’s quota=3 1 A 2 3 4 B 5 C MRU LRU
PIPP Example Core0’s Block Core1’s Block Core0 quota: 5 blocks Core1 quota: 3 blocks Request 6 Core0’s quota=5 1 A 2 3 4 D B 5 MRU LRU
PIPP Example Core0’s Block Core1’s Block Core0 quota: 5 blocks Core1 quota: 3 blocks Request 7 Core0’s quota=5 1 A 2 6 3 4 D B MRU LRU
PIPP Example Core0’s Block Core1’s Block Core0 quota: 5 blocks Core1 quota: 3 blocks Request D 1 A 2 7 6 3 4 D MRU LRU
PIPP Example Core0’s Block Core1’s Block Core0 quota: 5 blocks Core1 quota: 3 blocks Request E Core1’s quota=3 3 1 A 2 7 6 D 4 MRU LRU
PIPP Example Core0’s Block Core1’s Block Core0 quota: 5 blocks Core1 quota: 3 blocks Request 2 1 A 2 7 6 E 3 D MRU LRU
Pseudo-Partition Benefit Core0’s Block Core1’s Block Core0 quota: 5 blocks Core1 quota: 3 blocks Request New Strict Partition MRU1 MRU0 LRU0 LRU1
Pseudo-Partition Benefit Core0’s Block Core1’s Block Core0 quota: 5 blocks Core1 quota: 3 blocks Request New Pseudo Partition MRU LRU
Methodology • SimpleScalar simulator for x86 • Intel Core 2 processor • 32KB, 8-way 3-cycle L1I-L1D for each core • A shared 4MB, 16-way, 11-cycle LLC • Multi-programmed workloads from SPEC CPU benchmarks. (2-core and 4-core workloads) • 500m insns warmup, 250m insns simulation
Evaluation • 2-Core Weighted Speedup UCP Friendly TADIP Friendly PIPP outperforms LRU by 19.0%, UCP by 10.6%, TADIP by 10.1%
4-Core Weighted Speedup UCP Friendly TADIP Friendly PIPP outperforms LRU by 21.9%, UCP by 12.1%, TADIP by 17.5%
Occupancy Control For most workloads, the partitioning deviation is within 1.0 of the target allocation, similar to UCP.
Conclusion • Novel proposal on Insertion and Promotion • A single unified mechanism provides both capacity and dead time management • Outperforms prior UCP and TADIP
Thank you ! Questions?