
Speaker Verification System using SVM
This project explores the use of support vector machines (SVM) for speaker verification. Techniques such as score-space kernels and phonetic SVM are proposed to improve the system. The system is evaluated using likelihood ratios and phone N-grams.
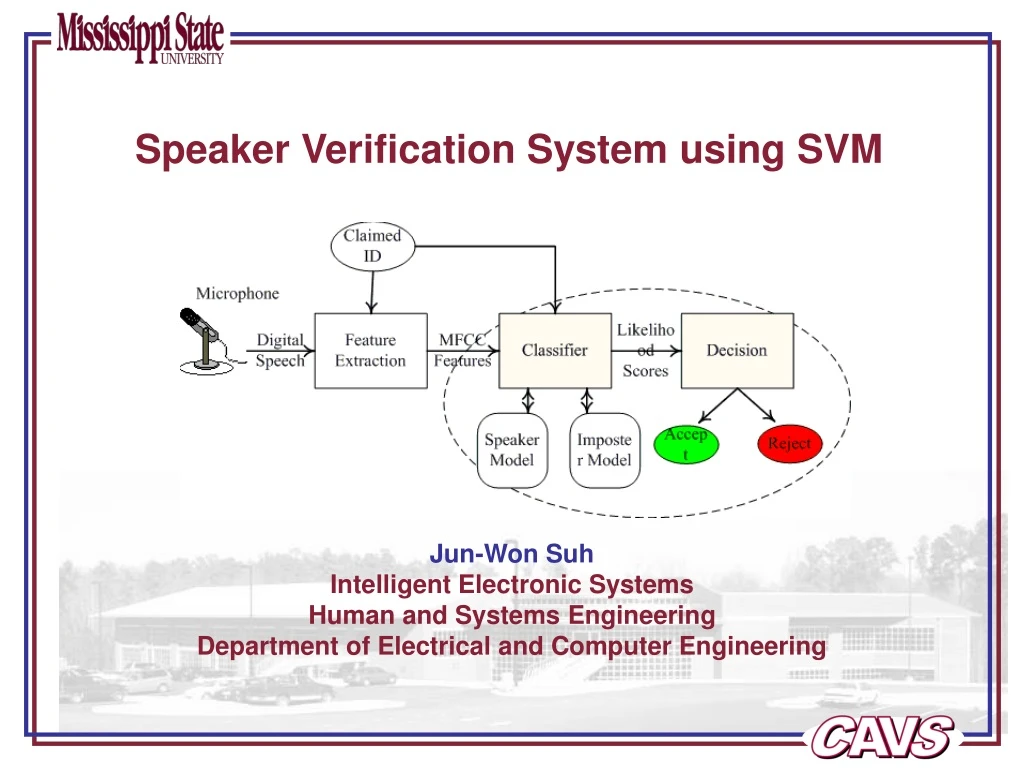

Speaker Verification System using SVM
E N D
Presentation Transcript
Speaker Verification System using SVM Jun-Won Suh Intelligent Electronic Systems Human and Systems Engineering Department of Electrical and Computer Engineering
Research Activities • Software Release • Tcl/Tk Search Demo debug • Language Model Tester • Diagnose Method for LanguageModel Classes • Speaker Verification System • Setup parameters for isip_verify • Run the isip_verify utility to make SVM baseline • Propose techniques to improve system (Thesis Topic) • Overall • Speed up on my research to graduate at DECEMBER.
SVM baseline DEC curve • Some minor changes in front-end cause little bit better results.
Classifying sequences using score-space kernels • The score-space kernel enables SVMs to classify whole sequences. • A variable length sequence of input vectors is mapped explicitly onto a single point in a space of fixed dimension. • The score-space is derived from the likelihood score. • Score-argument, ,which is a function of scores of a set of generative model • Score-mapping operator, ,which maps the scalar score-argument to the score-space. Choosing the first derivative operator, the gradient of log likelihood wrt a parameter describes how that parameter contribute to generating a particular speaker model.
Computing the score-space vectors Define the global likelihood of a sequence X = {x1, …, xNl} where, Ng is the number of Gaussians that make up the mixture model. Nd is the dimensionality of the input vectors with components, and parameters of GMM Since we define the sequence X = {x1, …, xNl}, The derivatives are with respect to the covariances, means, and priors of the GMM. Let
Computing the score-space vectors The derivative with respect to the jth prior is, The derivative with respect to the kth components of the jth mean is, Lastly, the derivative with respect to the kth component of the jth covariance is, The fixed length score-space vector can be expressed as, where, j* runs number of GMM, Ng and k* runs dimensionality of input vectors Nd.
Computing the score-space vectors Using the first derivative with argument score-operator and the same score-argument the mapping becomes • This mapping have a minimum test performance that equals the original generative model, M. • The inclusion of the derivatives as “extra features” should give additional information for the classifier to use. . • An alternative score-argument is the ratio of two generative models, M1 and M2,
Computing the score-space vectors • The dimensionality of the score-space is equal to the total number of parameters in the generative models. Hence the SVM can classify the complete utterance sequences. • The kernel is constructed using dot products in score-space where, G is the inverse fisher information matrix in log likelihood score-space mapping.
One of MIT-LL approach: Phonetic SVM System • Same approach as Score-space method (prosody, word choice, pronunciation, and etc.) • Using the phone sequence of acoustic information, the system performs accurate on speaker verification job. • This technique uses likelihood ratio score-space kernel with no derivative arguments.
Phone Sequence Extraction • Phone sequence extraction for speaker recognition process is performed using the phone recognition system (PPRLM) designed by Zissman for language identification. • Phone is modeled in a gender dependent context independent manner using a three state HMM. • Phone recognition is performed with a Viterbi search using a fully connected null-grammar network on monophones (no explicit language model in decoding). • The phone sequences is vectorized by computing frequencies of N-grams.
Bag of N-grams Produce N-grams by the standard transformation of the stream. Example: For bigrams, the sequence of phones, t1, t2, …, tn, is transformed to the t1_t2, t2_t3, …,tn-1_tn. The unique unigrams and bigrams are designated d1,…,dM, and d1_d1, … dM_dM. Then we calculate probabilities and joint probabilities.
Kernel Construction • Likelihood ratio computation serve as the kernel. • Suppose that the sequence of N grams in each conversation side is t1, t2, … , tn and u1, u2, …, um. Also denote the unique set of N grams as d1, d2, …,dM.
Conclusion • Using the nature of human listeners, the Speaker Verification can be improved. • Using phone N-gram and Score-space technique can improve the Speaker Verification system.
References • V. Wan, Speaker Verification using Support Vector Machines, University of Sheffield, June 2003 • V. Wan, Building Sequence Kernels for Speaker Verificaiton and Speech Recognition, University of Sheffield • S. Bengio, and J. Marithoz, Learning the Decision Function for the Speaker Verification, IDIAP, 2001 • W.M. Campbell, J.P. Campbell, D.A. Reynolds, D.A. Jones, and T.R. Leek, Phonetic Speaker Recognition with Support Vector Machines, Advances in Neural Information Processing Systems, 2004





















