
栈的基本概念:
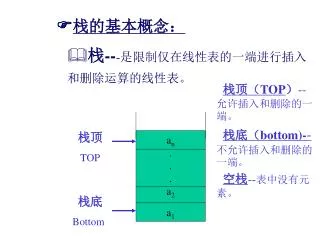
栈的基本概念:. 栈 -- - 是限制仅在线性表的一端进行插入和删除运算的线性表。. 栈顶( TOP ) -- 允许插入和删除的一端。 栈底( bottom)- - 不允许插入和删除的一端。 空栈 -- 表中没有元素。. 栈顶 TOP. a n . . . a 2 a 1. 栈底 Bottom. 栈的基本概念:. 栈 -- 又称为后进先出的线性表( LIFO 表, Last In First Out ). 进栈. 退栈. 进栈 --- 最先插入的元素放在栈的底部。 退栈 --- 最后插入的元素最先退栈。. a n . . .

栈的基本概念:
E N D
Presentation Transcript
栈的基本概念: • 栈---是限制仅在线性表的一端进行插入和删除运算的线性表。 • 栈顶(TOP)--允许插入和删除的一端。 • 栈底(bottom)--不允许插入和删除的一端。 • 空栈--表中没有元素。 栈顶 TOP an . . . a2 a1 栈底 Bottom
栈的基本概念: • 栈--又称为后进先出的线性表(LIFO表,Last In First Out) 进栈 退栈 进栈--- 最先插入的元素放在栈的底部。 退栈---最后插入的元素最先退栈。 an . . . a2 a1 栈顶 栈底
栈的基本运算: • 置空栈 • 进栈 • 取栈顶元素 • 判空栈 • 退栈
顺序栈:栈的顺序结构 • 顺序栈:用向量定义(类似于顺序表),将栈底位置设置在向量两端的任意一个端点;用top(整型量,栈顶指针)来指示栈当前栈顶位置。 • 顺序栈的定义: Typedef int datatype;/*栈元素的数据类型*/ #define maxsize 64 /*栈可能达到的容量,暂定为64*/ Typedef struct {datatype data[maxsize]; Int top; }seqstack;/*顺序栈类型定义*/ Seqstack *s;/* S是顺序栈类型指针*/
顺序栈:栈顶指针与栈中元素间的关系 3 2 1 0 3 2 1 0 3 2 1 0 A D C B A TOP TOP Top=-1空栈 A进栈 B、C、D依次进栈 3 2 1 0 3 2 1 0 B A TOP Top=-1,B、A退栈 D、C依次退栈
顺序栈主要运算 • 栈底位置固定在向量的低端,即: • S->data[0]----表示栈底元素; • 进栈:S->TOP加1(正向增长)。 • 退栈:S->TOP减1。 • 空栈:s->top<0 • 栈满:S->TOP=maxsize-1 • 上溢:栈满时再做进栈运算(一种出错状态,应设法避免)。 • 下溢:栈空时再做退栈运算将产生溢出,这是一种正常状态(因为栈的初态和终态都是空栈,下溢常用作程序控制转移的条件)。
顺序栈的几种基本运算例 • 置空栈: • 判栈空: • 进栈: • 退栈: • 取栈顶元素:
顺序栈的几种基本运算例 • 置空栈: SETNULL(S)/*将顺序栈S置为空*/ Seqstack *s; {s->top=-1 } /* SETNULL */
顺序栈的几种基本运算例 • 判栈空: int EMPTY(S)/*判定顺序栈S是否为空*/ Seqstack *s; {if(s->top>=0) return FAULSE; else return TRUE; } /* EMPTY */
顺序栈的几种基本运算例 • 进栈: Seqstack *PUSH(S,X) /*将元素X插入顺序栈S顶部*/ Seqstack *s; datatype x; {if(s->top==maxsize-1) {输出“上溢”; return NULL;} else {s->top++;s->data[s->top]=x;} return s; } /* PUSH */
顺序栈的几种基本运算例 • 退栈: Seqstack POP(S) /*若栈S非空,取出栈顶元素删除之*/ Seqstack *s; {if(EMPTY(S)) {输出“下溢”; return NULL;} else {s->top--;return(s->data[s->top+1]);} /* 删除栈顶元素,并返回被删值 */ } /* POP */
顺序栈的几种基本运算例 • 取栈顶: datatype TOP(S) /*取顺序栈S的栈顶*/ Seqstack *s; {if(EMPTY(S)) {输出“栈空”; return NULL;} else {return(s->data[s->top]);} } /* TOP */
关于顺序栈的约定和主要运算的思考: • 如果约定顺序栈栈空为:s->top=0(教材的约定),则顺序栈下述的几种运算如何描述? 置空栈: 判栈空: 进栈: 退栈: 取栈顶元素:
栈上溢的解决方法 当程序中同时使用几个栈时,如何防止栈的上溢? • 方法一: • 将栈的容量加到足够大,但这种方法由于事先难以估计容量,有可能浪费空间。 • 方法二: 使用两个(或多个)栈共享存储空间办法。 • 两栈的栈底分别设在给定存储空间的两端,然后各自向中间伸延,当两栈的栈顶相遇时才可能发生溢出。
栈上溢的解决方法之 -----方法二(两栈共享存储空间) 讨论:向第i(i=1或i=2)个栈插入元素x和删除一个元素的算法(参见教材)。
链栈 • 链栈---栈的链式存储结构(当顺序栈的最大容量事先无法估计时,可采用链栈 结构)。 data link TOP 栈顶 链栈的定义: Typedef struct node{ int data; struct node *link;}JD . .
链栈 • 链栈的特点--- (1)插入和删除(进栈/退栈)仅能在表头位置上(栈顶)进行。 (2)链栈中的结点是动态产生的,可不考虑上溢问题。 • (3)不需附加头结点,栈顶指针就是链表(即链栈)的头指针。
链栈 • 链栈进栈运算--- JD *lzjz(JD *top,int x) {/*将元素x进链栈 */ JD *p; p=(JD *)malloc(sizeof(JD)); P->data=x; p->link=top; return(p); }
链栈 • 链栈退栈运算--- JD *lztz(JD *top,int *p) {/*从链栈顶取出元素存至(*p) */ JD *q; if(top!=NULL) {q=top; *p=top->data; top=top->link; free(p);} return (top); }
栈小结: • 顺序栈有发生上溢 的可能,而链栈通常不会发生栈满(除非整个空间均被占满) • 只要满足LIFO原则,均可采用栈结构。 • 栈的应用:递归调用。
迷宫问题 (a) 迷宫的图形表示 (b) 迷宫的二维数组表示
求解迷宫问题的简单方法是:从入口出发,沿某一方向进行探索,若能走通,则继续向前走;否则沿原路返回,换一方向再进行探索,直到所有可能的通路都探索到为止。求解迷宫问题的简单方法是:从入口出发,沿某一方向进行探索,若能走通,则继续向前走;否则沿原路返回,换一方向再进行探索,直到所有可能的通路都探索到为止。 为避免走回到已经进入的点(包括已在当前路径上的点和曾经在当前路径上的点),凡是进入过的点都应做上记号。 为了记录当前位置以及在该位置上所选的方向,算法中设置了一个栈,栈中每个元素包括三项,分别记录当前位置的行坐标、列坐标以及在该位置上所选的方向(即directon数组的下标值)
栈用顺序存储结构实现,栈中元素的说明如下: struct NodeMaze { int x,y,d; }; typedef struct NodeMaze DataType; 算法4.15 求迷宫中一条路径的算法 void mazePath(int *maze[],int *direction[],int x1,int y1,int x2,int y2) /* 迷宫maze[M][N]中求从入口maze[x1][y1]到出口maze[x2][y2]的一条路径 */ /* 其中 1<=x1,x2<=M-2 , 1<=y1,y2<=N-2 */
{ int i,j,k,kk; int g,h; PSeqStack st; DataType element; st = createEmptyStack_seq( ); maze[x1][y1] = 2; /* 从入口开始进入,作标记 */ element.x = x1; element.y = y1; element.d = -1; push_seq(st,element); /* 入口点进栈 */ while (not isEmptyStack_seq(st)) /* 走不通时,一步步回退 */ { element = top_seq(st); i = element.x; j = element.y; k = element.d + 1;
pop_seq(st); while (k<=3) /* 依次试探每个方向 */ { g = i + direction[k][0]; h = j + direction[k][1]; if (g==x2 && h==y2 && maze[g][h]==0) /* 走到出口点 */ { printf("The path is:\n"); /* 打印路径上的每一点 */ for (kk=1;kk<=st->t;kk++) printf("the %d node is: %d %d \n",kk, st->s[kk].x,st->s[kk].y); printf("the %d node is: %d %d \n",kk,i,j); printf("the %d node is: %d %d \n",kk+1,g,h); return; }
if (maze[g][h]==0) /* 走到没走过的点 */ { maze[g][h] = 2; /* 作标记 */ element.x = i; element.y = j; element.d = k; push_seq(st,element); /* 进栈 */ i = g; /* 下一点转换成当前点 */ j = h; k = -1; } k = k + 1; } } printf("The path has not been found.\n"); /* 栈退完,未找到路径 */ }
队列的概念 • ---只允许在表的一端进行插入,而在表的另一端进行删除,是一种先入先出的线性表(FIFO)。 • 出队 入队 • 队头 队尾 a1 a2 …….an
队列的基本概念: • 队头(front):允许删除(出队)的一端。 • 队尾(Rear):允许插入的一端。 • 空队列:队列中没有元素。 • 进队:队的插入运算,即插入新的队尾元素。 • 出队:队的删除运算,删除队首元素。
队列的基本运算: • 入队 • 出队 • 取队头元素 • 置空队列 • 判队列是否为空
顺序队列: • 顺序队列: • ----队列的顺序存储结构,用一组连续的存储单元依次存放队列中的元素。 • 顺序队列的类型说明: typedef struct {datatype data[m]; int f,r; /*队首、队尾*/ }sequeue; sequeue *sq
顺序队列运算时的头、尾指针变化: B A 3 2 1 0 Sq->r Sq->r Sq->f Sq->f 空队列 A、B相继入队 D C Sq->r Sq->r Sq->f Sq->f A、B相继出队 C、D相继入队
顺序队列的约定和主要运算: • 队头指针:f总是指向当前队头元素的前一个位置。 • 队尾指针:r指向当前队尾元素的位置。 • 初始状态:f=r=-1 • 入队运算: sq->r++; /*尾指针加1 */ sq->data[sq->r]=x; /* x入队 */ • 出队运算: sq->f++; /* 头指针加1 */
顺序队列的约定和主要运算: • 队列长度: (sq->r)-(sq->f) • 队空: (sq->r)=(sq->f) • 下溢:队空时再作出队操作。 • 队满: (sq->r)-(sq->f)=m • 上溢:队满时再作入队操作。
顺序队列的上溢: • 队上溢: 真上溢(r-f=m):队列真正满时再入队。 假上溢:r已指向队尾,但队列前端仍有空位置。 • 解决假上溢的方法: • 方法一:每次删除队头一个元素后,把整个队列往前移一个位置(造成时间浪费)。 • 方法二:循环队列
循环队列 将所用的数组sq->data[m]设想为首尾相接的循环数组(即:data[0]连在data[m-1]之后)。 r f m-1 0 1
循环意义下的队列入队: 若尾指针r等于向量的上界,再入队,令尾指针等于向量的下界,即:在循环意义下的尾指针的加1操作可描述为: If(sq->r+1>=m) sq->r=0; Else sq->r++; • 利用“模运算”,则下述运算可描述为: 入队:sq->r=(sq->r+1)%m 出队:sq->f=(sq->f+1)%m 队空: sq->r=(sq->f) 队满: (sq->r+1)%m=sq->f • 循环队列的几种运算描述: 置空队、判空队、入队、出队、取队头元素(略)
链队列 • 链队列---队列的链式存储结构,它是限制仅在表头删除和表尾插入的单链表。 • 链队列的描述和几种基本运算(自学): • 置空队、判队空、取队头结点数据、入队、出队。
队列的应用举例--求迷宫的最短路径 1 2 3 4 5 6 7 8 1 2 3 4 5 6
需要解决的问题1:如何从某一坐标点出发搜索其四周的邻点需要解决的问题1:如何从某一坐标点出发搜索其四周的邻点
需要解决的问题2:如何存储搜索路径 需要解决的问题3:如何防止重复到达某坐标点
struct moved { int x,y; } move[8]; int maze[m2][n2]; #define r 64 #define m2 10 #define n2 10 int m=m2-2,n=n2-2; typedef struct { int x,y; int pre; } sqtype; sqtype sq[r];
int SHORTPATH(int maze[][2]) { int i,j,v,front,rear,x,y; sq[1].x=1; sq[1].y=1; sq[1].pre=0; front=1; rear=1; maze[1][1]=-1; while(front<=rear) { x=sq[front].x; y=sq[front].y; for (v=0;v<8;v++) { i=x+move[v].x; j=y+move[v].y; if (maze[i],[j]==0) { rear++’ sq[rear].x=i; sq[rear].y=j; sq[rear].pre=front; maze[i][j]=-1; } if ((i==m)&&(j==n)) { PRINTPATH(sq,rear); RESTORE(maze); return(1); } } front++; } return(0); }
PRINTPATH(sqtype sq[],int rear) { int i; i=rear; do { printf(“\n(%d,%d)”,sq[i].x,sq[i].y); i=sq[i].pre; } while (i!=0); }