s 1
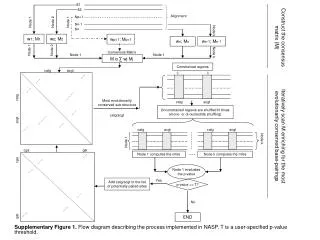
s 1. Consensus Matrix. w p+1 ; M p+1. M α ∑ wj M j. catg. acgt. Unconstrained regions are shuffled N times (mono- or di-nucleotide shuffling). catg. acgt. catg. acgt. Node k. Node 1. Node 1 computes the mfes. Node k computes the mfes. s 2. s p+1. Alignment. Node 1. Node 1.

s 1
E N D
Presentation Transcript
s1 Consensus Matrix wp+1; Mp+1 M α∑ wj Mj catg acgt Unconstrained regions are shuffled N times (mono- or di-nucleotide shuffling) catg acgt catg acgt Node k Node 1 Node 1 computes the mfes Node k computes the mfes s2 sp+1 Alignment Node 1 Node 1 Node 2 sn-1 sn Node k Construct the consensus matrix (M) w1; M1 w2; M2 wn; Mn wn-1; Mn-1 Node 1 Node 2 Node k Node 1 Node 1 Constrained regions catg acgt catg Most evolutionarily conserved sub-structure catg/acgt acgt Supplementary Figure 1. Flow diagram describing the process implemented in NASP. T is a user-specified p-value threshold. Iteratively scan M enriching for the most evolutionarily conserved base-pairings cga gat cga Node 1 evaluates the p-value Yes Add catg/acgt to the list of potentially paired sites p-value <= T? No gat END