Download

1 / 4
0 likes | 62 Views
Importance of Data Masking in Test Data Management<br>Importance of Data Masking in Test Data Management<br>Importance of Data Masking in Test Data Management<br>

E N D
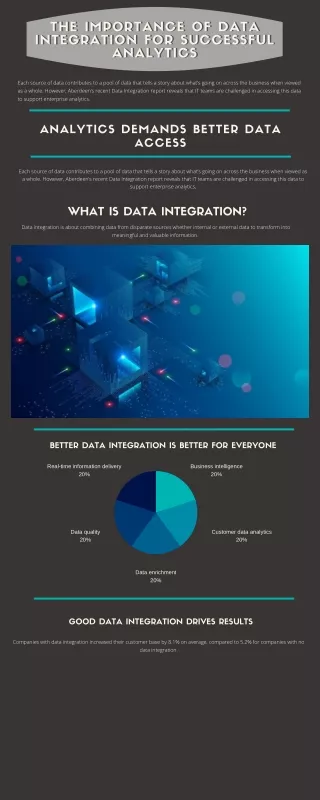
Importance of Data Masking in Test Data Management The software release management process involves multiple phases, and one crucial phase is test data management. As an IT leader, you know the significance of test data management to manage and control the data used for testing software applications. Test data management is critical in the application testing life cycle by directly impacting the testing process and software's quality and reliability. But for adequate testing, you will need secure access to data. Now, the question is, in this digital age where data breaches and cybercrime have become critical issues, how can you securely access data required for software testing and development functions? It's when data masking comes into the picture. You can protect your company's sensitive data with the help of a data masking technique. Let's dive in to learn about data masking and its importance in test data management. What is Data Masking? Data masking creates structurally similar but essentially inauthentic versions of a company's data that can be used for several purposes, such as software testing, sales demos, or user training.
The format of the original data remains the same, but technicians alter the values. Data can be changed through substitution, scrambling, or character shuffling. Data masking is a one-way process of retrieving the original organisational data. The primary purpose of this technique is to protect the actual data while having a functional, unrealistic substitute for tasks not requiring actual corporate data. How Data Masking is Important for Test Data Management? With more IT companies realising the importance of data to build data-driven applications and software, they are looking for ways to securely access organisational data to accelerate application development without compromising security and privacy. Your company can be home to an enormous amount of sensitive data in non-production environments used for software development and testing functions. Non-production environments are reported to represent the greater risk in the company, where there can be multiple copies for non-production purposes for every copy of production data. The software development team must access realistic, secure data for effective Test data management. However, actual data can be exposed to considerable security risks. With the data masking technique, you can eliminate the risk of personal data exposure while complying with data privacy regulations. By following the appropriate data masking practices, enterprises can move data fast to the software development team in real-time, resulting in an accurate test data management process. How Does Data Masking Work? Encryption is considered an excellent practice to store and transfer sensitive data securely. However, technicians find it difficult to query and analyse encrypted data, resulting in delayed software development and testing. As a result, companies need another way to keep their data secure and private when used for development, testing, or research. Data masking, also known as sanitisation, helps keep sensitive organisational information private by making it unrecognisable but usable. It lets software developers use data sets without exposing sensitive data to any security risk, resulting in effective and accurate test data management solutions. Data masking differs from data encryption as you can decrypt the encrypted data and return it to its original state using the correct encryption key.
However, with masked data, you will have no algorithm to recover the initial values of data. With data masking, you can generate a characteristically accurate but fake version of a data set that has no value for hackers. Types of Data Masking Here discussed are different types of data masking you can choose to effectively test the data required for developing and testing software: ● Static data masking: This masked data type creates a separate hidden data set from a production database used in non-production environments, such as development and testing. The masked data values generate test and analytical results mirroring the original data, which persists over time to ensure accurate and repeatable results. Dynamic data masking: It provides role-based security, specifically in production systems, when users need actual data. When a user requests data, dynamic masking transforms, blocks, or obscures the user's access to sensitive information fields in real-time. On-the-fly data masking: This masked data type allows software development teams to read and mask a small subset of production data into the test environment. Data is hidden by copying it from one environment to another, meaning data is never presented in an unmasked form in the target environment. With this approach, you can eliminate delays incurred when using a staging environment to prepare data. ● ● Data Masking Techniques Companies can use various data masking techniques to anonymise or mask private and sensitive data, thus providing the software development team secure access to data required for test data management. These data masking techniques are as follows: Scrambling Scrambling involves randomly reordering alphanumeric characters to obscure the original data. For example, a customer complaint ticket number 123765 in the production environment can appear as 962312 in a test environment after scrambling it. Substitution This technique replaces the original data with the other values from credible values. Technicians often use lookup tables to provide alternative values to the original data. You must ensure the values pass rule constraints and preserve the data's original characteristics. Data aging Using this method, you can increase or decrease a date field using a specific date range. In addition, make sure to keep the range value secure. Shuffling
You can shuffle the values within a column to randomly reorder them when using the shuffling technique. For instance, when shuffling customers' surnames, the results will look accurate but won't reveal their personal information. Variance The variance technique can be applied to a number or date field. With the variance algorithm, you can modify each date or number in a specific column by a random percentage of its actual value. Summing up it all The whole point of security is maintaining data confidentiality where the test users can be assured of the data's privacy. With data masking, you can protect the organisational data while preserving business value. An expert offering reliable test data management solutions will ensure consistent data masking while maintaining referential integrity across different data sources. It will further ensure the security of the company's sensitive data for accurate, real-time software testing. Contact Us Company Name: Enov8 Address: Level 2, 389 George St, Sydney 2000 NSW Australia Phone(s) : +61 2 8916 6391 Email id: enquiries@enov8.com Website: https://www.enov8.com