Download

1 / 37
390 likes | 587 Views
Quantitative Research. Types of Quantitative Research. Descriptive statistics Correlational research Experimental research. Descriptive statistics. Describing a setting or event using numbers e.g. surveys of - Motivation Learning styles Needs analysis Evaluation of language programs

E N D
Types of Quantitative Research Descriptive statistics Correlational research Experimental research
Descriptive statistics Describing a setting or event using numbers e.g. surveys of - Motivation • Learning styles • Needs analysis • Evaluation of language programs - Student/teacher attitudes/beliefs
Pies and Histograms How many male and female students are there in this room? • Express the figures as a frequency distribution (histogram) • Express figures as percentages - Express figures as a pie chart
Likert scales Answer the following on a four point scale 4 strongly agree, 3 agree 2 disagree 1 strongly disagree A. All Vietnamese students should study English B. It is important that sentences be grammatically correct when spoken How can we display this data?
Frequency – add up the number of votes for each level: Q/A Q/B 4 3 2 1 What are the mean and mode for each question? *
How can this data be displayed and analyzed? • Frequency – e.g. histogram for responses to each question 2. Percentage + pie chart for each question 3. Central tendency or mean M = ΣX N 4. Dispersion or Standard Deviation
Dispersion or Standard Deviation Draw a frequency distribution (histogram) for the following two sets of numbers* • 65, 61, 60, 54, 50, 50,47, 41, 22 • 54, 53, 51, 50, 50, 50, 49, 47, 46 (the distribution is between 20 and 65 and has intervals of five) What do you notice about the dispersion of scores?
What you notice is that A and B have the same median and mean scores BUT the B scores are more focused around the median score WHILST the A scores are more widely spread out.
If you draw a line to cover all of the scores, you get two lines with different shapes • B is a steep curve • A is a flat curve • However, both have the same general shape. This shape is called a ‘bell shape’ or a ‘bell curve’.
The average of distances from the mean in the B curve is less than the average of the distances from the mean in the A curve. This concept of finding average distances is called standard deviation. • Standard deviation measures the distance from the mean = “average of the differences of all scores from the mean”
Normal distribution • Normal distribution of final test results is in the shape of a bell curve. Why is this?
Because final tests, e.g. end of schooling tests, are designed to assess the full range of ability. Therefore, some questions on these tests are easy, some are moderately difficult, and some are extremely difficult. This means that there are only some students in the highest and the lowest categories.
Of course, you could design a test in which everyone gets full marks. But this is not helpful if you need to choose students for a particular purpose such as university admission.
Types of data • The previous example of A and B test scores used interval data • A survey with a Likert scale will use ordinal data • How are they different?
If you are doing a survey you will probably use a Likert scale. • You will need to write very clear Likert scale survey items to get reliable data
Writing Survey Items** Avoid: - Long statements - Ambiguous ones • Negative ones - Overlapping choices • Double-barreled choices - Loaded words • Words that express an absolute • Prestige items • Biased questions
We have looked at descriptive statistics, the next category is correlationalstatistics
Correlational Research Correlation coefficient = the degree of relationship between sets of scores e.g. two examiners’ marks out of 10 Examiner A Examiner B Marie 9 8 Jose 8 7 Jeanne 7 5 Hachiko 6 6 Raphael 5 4 Yuka 4 3 Hossein 3 1 Tamara 2 2 Hans 1 0
Do the two examiners mostly agree? • Can we say that their scores show a high degree of correlation or agreement? • How can we find out?
1. We could calculate the mean for each examiner. BUT a more accurate statistic would be a correlation between the two examiner’s scores. The first step is to find out what kind of data are used.
What kind of data is involved? • Nominal e.g. male/female? • Ordinal/Rank ordered e.g. Likert scale ? • Interval/Continuous e.g. there is a fixed distance between the figures?
Types of Correlation • Rank ordered data – Ordinal Data e.g. students ranked 1st, 2nd, 3rd etc. (Spearman’s rho or p) 2. Continuous scale – values show distances between data e.g. test scores 50, 44, 41 etc. (Pearson product moment – r)
Meaning of Correlations • A correlation between sets of data is not necessarily ‘significant’. There are significance tables that indicate degree of significance. 2. Most importantly, correlation does not indicate a cause for the data differences. E.g. correlation says that A matches B, not that A causes B.
Experimental Research Type 1 Do males and females have differing abilities to remember lists of words? You will see two lists for 2 minutes each and then be asked to write down words you remember.
List A bath write bed crisp dream fresh glass Shiny jar lie cup listen window new pail read bright think rest bucket room sleep speak relax table
List B Light lamp bulb lantern Sit stand kneel bend jump Old ancient tired weak bent Tire wheel engine gear door Student desk teacher pencil eraser
How many words did you remember from A and from B? • What are your conclusions?
Recording and analyzing the data 1. We could record the data as in Tables 7.1 and 7.2* 2. We could also work out the mean and the standard deviation
Key question: Is there a significant difference between the means?
T-Test This test compares the mean scores for two groups e.g. male/female, younger/older, Vietnamese/Spanish etc. Statistical tables will indicate the significance of the two means.
Experimental Studies Type 2 An experiment = “a situation in which one observes the relationship between two variables by deliberately producing a change in one and looking to see whether this alteration produces a change in the other” (Anderson in Brown/Rodgers 211) e.g. compare effectiveness of Method A and Method B in teaching academic writing, see table 7.7**
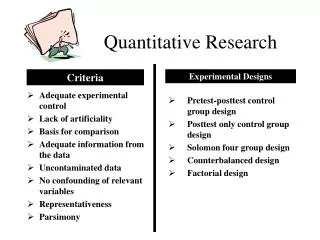
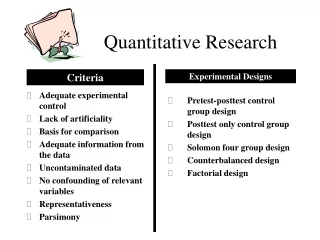
Features of Experimental Studies Type Two • A research question or hypothesis is posed**. • Students are randomly selected and assigned to the two groups, • Two different treatments are applied to the two groups, • Pre-tests and post-tests are given • One group will be the control group, the other the experimental group
Summary of types of statistics • Comparison of means – t-test • Correlations • Rank ordinal data – Spearman’s rho • Interval/continuous data – Pearson’s r • Nominal data – Phi or Chi square
Denscombe, Quantitative Data, p. 270/302 • Sources of numbers • answers to closed-ended questions • content analysis of transcripts • observation of events • official stats • business data • Nominal data • counting things and placing them into a category • Ordinal data • responses on a five point Likert scale • Interval data • distance between catogories is known e.g. ten year calendar data, as opposed to more than/less than • Ratio data • scale has a zzero point e.g. income data • Discrete data • data in whole units e.g. children per family • Continuous data • e.g. height ( could be measured with more or less precision) • Coding • data can be divided into categores and then coded e.g. datat about 1000s of job types • Frequency • e.g. grouping employees’ absences acc. to frequency – 6 days occurs six times etc. • Describing frequency • the mean (aveage) – can only b used with real (cardinal) number • affected by outliers • median, middle point • mode, the most common • range of data – subtract min. from max. • fractiles – divide range into fractiosn e.g. quartiles dividesdata into four groups, percentiles into 100
Standard deviation • spread of data relative to the arithmetic mean • can only be used with interval and ration data • Statistical significance • Are two variables associated? • chi-square test can be used with all forms of data = difference between what was observed and what was expected • Are two groups different? • t-test – • differences are ‘real’, not a fluke, if there is a probability of less than 1 in 20, ‘p<0.05’, that any difference between the two sets of data were due to chance • works well with small groups of less than 30 • groups do not have to be the same size • Are two variable related? • correlations cannot be used with nominal data • Spearman’s rank correlation coefficient for ordinal data • Pearson’s product moment correlation coefficient with interval and ratio data • +1 – 0 - -1 • correlation not = to cause • Types of Quantitative Data p. 288 • Type Central Tendency Dispersion Statistical Test • Nominal mode frequency chi-square • Ordinal median range Mann-Whitney • Interval mean standard deviation t-test • Checklist for use of basic statistics, p. 301b
Quantitative Research Design, 247/269 • Broad distinction - comparisons between groups and relationship between variables • “Research design situates the researcher in the empirical world, and connects the research questions to data”, 248 • Design = • Strategy – qual. or quant. + • Framework – how much structure + • Data from whom? + • Method of data collection + • Comparison between groups based on experiments – looks ‘forwards’ from the independent variable to the dependent variable i.e. from cause to effect – what are the effects? • Relationship between variables uses correlations, looks ‘backwards’ from the dependent to the independent variable i.e. from effects to causes – what are the causes? = ex post facto research • Independent variable/IV = ‘cause’ • Dependent variable/DV = ‘effect’ • Control variable = the variable whose effects we want to remove or control – extraneous to the inquiry but might have distorting effect = covariance • Experiment • two groups, control and treatment, t-test, ANOVA • apply an independent variable to the treatment group • compare the outcomes • “We aim to attribute dependent or outcome variable differences between the groups to independent or treatment variable differences between the groups” • assumes that groups are alike in all other respects • random assignment “maximises the probability that they will not difer in any systematic way” 254 • Quasi-experimental/non-experimental design • use of naturally occurring groups e.g. a school class • Correlational survey • examines the relationship between two variables – one can be said to account for variance in he other • multiple linear regression (MLR) estimates how much variance arises from a particular set of independent variables as well as effect of each independent variable