Bandwidth and latency optimizations
430 likes | 667 Views
Bandwidth and latency optimizations. Jinyang Li w/ speculator slides from Ed Nightingale. What we’ve learnt so far. Programming tools Consistency Fault tolerance Security Today: performance boosting techniques Caching Leases Group commit Compression Speculative execution.

Bandwidth and latency optimizations
E N D
Presentation Transcript
Bandwidth and latency optimizations Jinyang Li w/ speculator slides from Ed Nightingale
What we’ve learnt so far • Programming tools • Consistency • Fault tolerance • Security • Today: performance boosting techniques • Caching • Leases • Group commit • Compression • Speculative execution
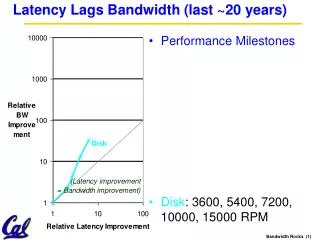
Performance metrics • Throughput • Measures the achievable rate (ops/sec) • Limited by the bottleneck resource • 10Mbps link: max ~150 ops/sec for writing 8KB blocks • Increase tput by using less bottleneck resource • Latency • Measures the latency of a single client response • Reduce latency by pipelining multiple operations
data GETATTR READ READ Caching (in NFS) • NFS clients cache file content and directory name mappings • Caching saves network bandwidth, improves latency
LEASE fh1, data READ fh1 fh1: C1 fh1: C1 INVAL fh1 READ WRITE fh1 OK Leases (not in NFS) • Leases eliminate latency in freshness check, at the cost of keeping extra state at the server
WRITE WRITE COMMIT Group commit (in NFS) • Group commit reduces the latency of a sequence of writes
Two cool tricks • Further optimization for b/w and latency is necessary for wide area • Wide area network challenges • Low bandwidth (10~100Mbps) • High latency (10~100ms) • Promising solutions: • Compression (LBFS) • Speculative execution (Speculator)
Low Bandwidth File System • Goal: avoid redundant data transfer between clients and the server • Why isn’t caching enough? • A file with duplicate content duplicate cache blocks • Two files that share content duplicate cache blocks • A file that’s modified previous cache is useless
LBFS insights: name by content hash • Traditional cache naming: (fh#, offset) • LBFS naming: SHA-1(cached block) • Same contents have the same name • Two identical files share cached blocks • Cached blocks keep the same names despite file changes
SHA-1(8K) SHA-1(8K) Naming granularity • Name each file by its SHA-1 hash • It’s rare for two files to be exactly identical • No cache reuse across file modifications • Cut a file into 8KB blocks, name each [x*8K,(x+1)*8K) range by hash • If block boundaries misalign, two almost identical files could share no common block • If block boundaries misalign, a new file could share no common block with its old version
Align boundaries across different files • Idea: determine boundary based on the actual content • If two boundaries have the same 48-byte content, they probably correspond to the same position in a contiguous region of identical content
Align boundaries across different files 87e6b..f5 ab9f..0a 87e6b..f5 ab9f..0a
LBFS content-based chunking • Examine every sliding window of 48-bytes • Compute a 2-byte Rabin fingerprint f of 48-byte window • If the lower 13-bit of f is equal to v, f corresponds to a breakpoint • 2 consecutive breakpoints define a “chunk” • Average chunk size?
LBFS chunking • Two files with the same but misaligned content of x bytes • How many fingerprints for each x-byte content? How many breakpoints? Breakpoints aligned? f1 f2 f3 f4 f1 f2 f3 f4
Why Rabin fingerprints? • Why not use the lower 13 bit of every 2-byte sliding window for breakpoints? • Data is not random, resulting in extremely variable chunk size • Rabin fingerprints computes a random 2-byte value out of 48-bytes data
A new fingerprint is computed from the old fingerprint and the new shifted-in byte Rabin fingerprint is fast • Treat 48-byte data D as a 48 digit radix-256 number • f47 =fingerprint of D[0…47] = ( D[47] + 256*D[46] + … + 25646*D[1]+ …+25647*D[0] ) % q • f48 = fingerprint of D[1..48] = ((f47 - D[0]*25647)* 256 + D[48] ) % q
LBFS reads File not in cache GETHASH (h1, size1, h2, size2, h3, size3) Fetching missing chunks Only saves b/w by reusing common cached blocks across different files or different versions of the same file Ask for missing Chunks: h1, h2 READ(h1,size1) READ(h2,size2) Reconstruct file as h1,h2,h3
LBFS writes MKTMPFILE(fd) Create tmp file fd CONDWRITE(fd, h1,size1, h2,size2, h3,size3) Transferring missing chunks saves b/w if different files or different versions of the same file have pieces of identical content Reply with missing chunks h1, h2 HASHNOTFOUND(h1,h2) TMPWRITE(fd, h1) Construct tmp file from h1,h2,h3 TMPWRITE(fd, h2) COMMITTMP(fd, target_fhandle) copy tmp file content to target file
LBFS evaluations • In practice, there are lots of content overlap among different files and different version of the same file • Save a Word document • Recompile after a header change • Different versions of a software package • LBFS results in ~1/10 b/w use
Speculative Execution in a Distributed File System Nightingale et al. SOSP’05
How to reduce latency in FS? • What are potentially “wasteful” latencies? • Freshness check • Client issues GETATTR before reading from cache • Incurs an extra RTT for read • Why wasteful? Most GETATTRs confirm freshness ok • Commit ordering • Client waits for commit on modification X to finish before starting modification Y • No pipelining of modifications on X & Y • Why wasteful? Most commits succeed!
Key Idea: Speculate on RPC responses Client Server 1) Checkpoint RPC Req RPC Req 2) Speculate! Block! RPC Resp RPC Resp 3) Correct? No: restore process & re-execute Yes: discard ckpt. RPC Req RPC Resp • Guarantees without blocking I/O!
Conditions of useful speculation • Operations are highly predictable • Checkpoints are cheaper than network I/O • 52 µs for small process • Computers have resources to spare • Need memory and CPU cycles for speculation
Spec Undo log Implementing Speculation 1) System call 2) Create speculation Time Process Checkpoint
Spec Undo log Speculation Success 1) System call 2) Create speculation 3) Commit speculation Time Process Checkpoint
Spec Undo log Speculation Failure 2)Create speculation 1) System call 3)Fail speculation Time Process Process Checkpoint
Ensuring Correctness • Speculative processes hit barriers when they need to affect external state • Cannot roll back an external output • Three ways to ensure correct execution • Block • Buffer • Propagate speculations (dependencies) • Need to examine syscall interface to decide how to handle each syscall
Handle systems calls • Block calls that externalize state • Allow read-only calls (e.g. getpid) • Allow calls that modify only task state (e.g. dup2) • File system calls -- need to dig deeper • Mark file systems that support Speculator Call sys_getpid() getpid reboot Block until specs resolved mkdir Allow only if fs supports Speculator
Spec(stat) Spec (mkdir) Undo log Output Commits 1) sys_stat 2) sys_mkdir 3) Commit speculation Time Process “stat worked” Checkpoint Checkpoint “mkdir worked”
Multi-Process Speculation • Processes often cooperate • Example: “make” forks children to compile, link, etc. • Would block if speculation limited to one task • Allow kernel objects to have speculative state • Examples: inodes, signals, pipes, Unix sockets, etc. • Propagate dependencies among objects • Objects rolled back to prior states when specs fail
Spec 1 Spec 1 Spec 2 Multi-Process Speculation Checkpoint Checkpoint Checkpoint Checkpoint Checkpoint pid 8000 pid 8001 Chown-1 Chown-1 Write-1 Write-1 inode 3456
Multi-Process Speculation • What’s handled: • DFS objects, RAMFS, Ext3, Pipes & FIFOs • Unix Sockets, Signals, Fork & Exit • What’s not handled (i.e. block) • System V IPC • Multi-process write-shared memory
Example: NFSv3 Linux Client 1 Server Client 2 Modify B Write Commit Open B Getattr
Example: SpecNFS Client 1 Server Client 2 Write+Commit Modify B speculate Getattr Open B speculate Getattr Open B speculate
Problem: Mutating Operations Client 1 1. cat foo > bar Client 2 2. cat bar • bar depends on speculative execution of “cat foo” • If bar’s state could be speculative, what does client 2 view in bar?
Solution: Mutating Operations • Server determines speculation success/failure • State at server is never speculative • Clients send server hypothesis speculation based on • List of speculations an operation depends on • Server reports failed speculations • Server performs in-order processing of messages
Foo v=1 Server checks speculation’s status Server Client 1 Cat foo>bar Write+Commit Check if foo indeed has version=1, if no fail
Group Commit • Previously sequential ops now concurrent • Sync ops usually committed to disk • Speculator makes group commit possible Client Client Server Server write commit write commit
Putting it Together: SpecNFS • Apply Speculator to an existing file system • Modified NFSv3 in Linux 2.4 kernel • Same RPCs issued (but many now asynchronous) • SpecNFS has same consistency, safety as NFS • Getattr, lookup, access speculate if data in cache • Create, mkdir, commit, etc. always speculate
Putting it Together: BlueFS • Design a new file system for Speculator • Single copy semantics • Synchronous I/O • Each file, directory, etc. has version number • Incremented on each mutating op (e.g. on write) • Checked prior to all operations. • Many ops speculate and check version async
Apache Benchmark • SpecNFS up to 14 times faster
Rollback cost is small • All files out of date SpecNFS up to 11x faster
What we’ve learnt today • Traditional Performance boosting techniques • Caching • Group commit • Leases • Two new techniques • Content-based hash and chunking • Speculative execution