Download

1 / 14
140 likes | 170 Views
This literature review explores a novel FPGA coprocessor design for simulating neural networks efficiently, focusing on the binary neuron model, matrix storage, SpMxV multiplication, and software optimizations. The study highlights the challenges, optimizations, and scalability issues in neural network simulation.

E N D
Chapter 11 in Systems and Circuit Design for Biologically-Inspired Intelligent Learning FPGA Coprocessor for Simulation of Neural Networks Using Compressed Matrix Storage Richard Dorrance Literature Review: 1/11/13
Overview • Binary neuron model for unsupervised learning • arranged into minicloumns and macrocloumns • Sparse matrix vector multiplication (SpMxV) • compressed row format • software optimizations • FPGA coprocessor • exploiting matrix characteristics for a “novel” architecture • benchmarks and scalability (or lack there of)
Binary Neuron Model • Modeled as McCulloch-Pitts neurons (i.e. binary): • only 2 states: firing (1) and not firing (0) • fixed time step t • refractory period of one time step
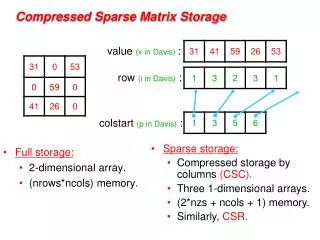
Compress Row Format • Sparse matrix representation (w/ 3 vectors): • value • column index • row pointer
SpMxV is the Bottleneck • Theoretically SpMxV should be memory bound • Reality: lots of stalling for data due to irregular memory access patterns • Coding Strategies: • cache prefetching • matrix reordering • register blocking (i.e. N smaller, dense matrices) • CPU: 100 GFLOPS (theoretical), 300 MFLOPS (reality) • GPU: 1 TFLOPS (theoretical), 10 GFLOPS (reality)
Simplifications and Optimizations • Matrix elements are binary: value vector is dropped • Strong block-like structure to matrices: compress column index vector
Conclusions • SpMxV is the major bottleneck to simulating neural networks • Architectures of CPUs and GPUs limit performance • FPGAs can increase performance efficiency • Specialized formulation of SpMxV limited scalability