Download
1 / 48
480 likes | 623 Views
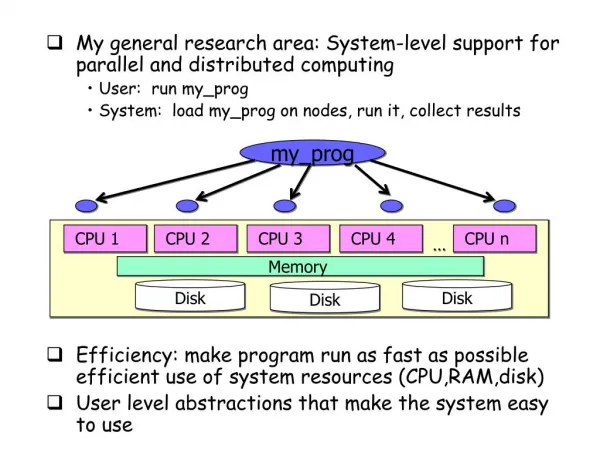
CPU 1. CPU 2. CPU 3. CPU 4. CPU n. …. Memory. Disk. Disk. Disk. My general research area: System-level support for parallel and distributed computing User: run my_prog System: load my_prog on nodes, run it, collect results

E N D
CPU 1 CPU 2 CPU 3 CPU 4 CPU n … Memory Disk Disk Disk • My general research area: System-level support for parallel and distributed computing • User: run my_prog • System: load my_prog on nodes, run it, collect results • Efficiency: make program run as fast as possibleefficient use of system resources (CPU,RAM,disk) • User level abstractions that make the system easy to use my_prog
… Network Nswap: Network RAM for cluster computers Cluster computer: multiple inexpensive, “independent” machines connected by a network, run system SW that make them look and act like single parallel computer Cluster system software
General Purpose Cluster • Multiple parallel programs share the cluster • Assigned to some, possibly overlapping, machines • Share NW, Memory, CPU, disk resources • Program workload changes over time • New programs may enter the system • Existing programs may complete and leave ==> imbalances in RAM and CPU usage across nodes some nodes don’t have enough RAM, some have unused RAM P1 P2 P3
CPU Memory Disk When node doesn’t have enough RAM space? Lots of Data that cannot all fit into Memory OS moves data to/from disk as needed (swapping) time to access data: CPU: 0.000000005 secs RAM: 100 x slower than CPU Disk: 10 million x slower -> Swapping is really, really slow
Network Swapping in a Cluster Node 1 Node 2 CPU CPU Bypass disk and swap pages of RAM to remote idle memory in the cluster RAM RAM Node 3 Disk CPU RAM network Network Swapping: expand Node 1’s memory using idle RAM of other cluster nodes rather than local disk
Why Nswap? The network is much faster than disk, so swapping data over NW to remote RAM is much faster than swapping to local disk
Nswap Architecture Divided into two parts that run on each node 1) Nswap client device driver for network swap “device” • OS makes swap-in & swap-out requests to it 2) Nswap server manages part of RAM for caching remotely swapped pages (Nswap Cache) User space Node A Node B OS space swap out page Nswap server Nswap Cache Nswap client Nswap server Nswap client Nswap Communication Layer Nswap Communication Layer Network
This summer • Answer questions having to do with policies for growing/shrinking RAM available for Nswap and implement solution(s): • How do we know when idle RAM is available? • Can we predict when idle RAM will be available for a long enough time to make it useful for NSWAP? • How much idle RAM should we take for Nswap? • How much RAM should we “give back” to the system when it needs it • Investigate incorporating Flash memory into the memory hierarchy and using it with Nswap to speed up swap-ins • System-level support for computation involving massive amounts of globally dispersed data (cluster computing on steroids) • Internet scale distributed/parallel computing • Caching, prefetching, programming interface?
A B C How Pages Move Around Cluster Node A (not enough RAM) Node B (has idle RAM) • Swap Out: • Swap In: • Migrate from node to node with changes in WL: A B When node B needs more RAM, it migrates A’s page to node C
Reliable Network RAM • Automatically restore remotely swapped page data lost in node crash • How: Need redundancy • Extra space to store redundant info. • Avoid using slow disk • Use idle RAM in cluster to store redundant data • Minimize use of idle RAM for redundant data • Extra computation to compute redundant data • Minimize extra computation overhead
Soln 1: Mirroring • When page is swapped out send it to be stored in idle RAM of 2 nodes • If first node fails, can fetch a copy from second node + easy to implement • Requires twice as much idle RAM space for same amount of data • Requires twice as much network bandwidth • two page sends across NW vs. one
01 0 01 0 00 0 00 0 00 1 01 1 01 1 Soln 2: Centralized Parity Encode redundant info for a set of pages across diff nodes in a single parity page If lose data, can recover it using parity page and other data pages in set parity page recovered page 00 1 01 1
Centralized Parity (cont.) • A single dedicated cluster node is the parity server • Stores all parity pages • Implements page recovery on a crash • Parity Logging: regular nodes compute a parity page locally as they swap-out pages, only when parity page is full is it sent to parity server • One extra page send to parity server on every N page swap-outs (vs. 2 on every swap-out for mirroring)
01 0 00 0 00 1 01 1 Soln 3: Decentralized Parity No Dedicated Parity Server Parity Pages distributed across cluster nodes 00 1 00 0 10 1 10 0 11 0 01 0 01 0 11 0 10 1 01 1 00 1 11 1
CPU Memory Disk Sequential Programming • Designed to run on computers with one processor (CPU) • CPU knows how to do a small number of simple things (instructions) • Sequential program is ordered set of instructions CPU executes to solve larger problem (ex) Compute 34 • Multiply 3 and 3 • Multiply result and 3 • Multiply result and 3 • Print out result
x Sequential Algorithm For each time step do: For each grid element X do: compute X’s new value X = f(old X, neighbor 1, neighbor 2, …)
The Earth Simulator Japan Agency for Marine-Earth Science and Technology
How Computer Executes Program • OS loads program code & data from Disk into RAM • OS loads CPU withfirst instruction to run • CPU starts executinginstructions one at a time • OS may need to movedata to/from RAM & Disk as prog runs CPU 2 Memory (RAM) 1 Disk
How Fast is this? • CPU speed determines max of how many instructions it can execute • Upper bound: 1 clock cycle: ~ 1 instruction • 1 GHertz clock: ~1 billion instructions/sec • Max is never achieved • When CPU needs to access RAM • takes ~100 cycles • If OS needs to bring in more data from Disk • RAM is fixed-size, not all program data can fit • Takes ~1,000,000 cycles
Fast desktop machine • This is the idea but check these nubmers!!!!! • GigaHertz processor • Takes ~.000000005 seconds to access data • 2 GigaBytes of memory • 231 bytes • Takes ~.000001 seconds to access data • 80 GB of disk space • Takes ~ .01 seconds to access data 1 million times slower than if data is on CPU
Requirements of Simulation • Petabytes of data • 1 petabyte is 250 bytes (1,125,899,906,842,624 bytes) • Billions of computations at each time step • We need help: • A single computer cannot do one time step in real time • Need a supercomputer • Lots of processors run simulation program in parallel • Lots of memory space • Lots of disk storage space
Processor 1 Processor 2 Processor n Parallel Programming • Divide data and computation into several pieces and let several processors simultaneously compute their piece 3.6 1.2 2.3 2.6 … …
Supercomputers of the 90’s • Massively parallel • 1,000’s of processors • Custom, state of the art • Hardware • Operating System • Specialized Programming Languages and Programming Tools
Fastest Computer* Blue Gene TMC CM-5 Earth Simulator ASCI White Cray Y-MP ASCI Blue Intel Paragon computation took 1yr in 1980, takes 16mins in 1995, 27secs in 2000 *(www.top500.org & Jack Dongara)
Fastest Computer* ASCI White ASCI Blue TMC CM-5 Intel Paragon TMC CM-2 Cray Y-MP computation took 1yr in 1980, takes 16mins in 1995, 27secs in 2000 *(www.top500.org & Jack Dongara)
Fastest Computer* Blue Gene Earth Simulator ASCI White *(www.top500.org & Jack Dongara)
Problems with Supercomputers of the 90’s • Expensive • Time to delivery ~2years • Out of date soon
Cluster: Supercomputer of the 00’s • Massively parallel Supercomputer out of network of unimpressive PCs • Each node is off-the-shelf hardware running off-the-shelf OS Network
Are Clusters Good? + Inexpensive • Parallel computing for the masses + Easy to Upgrade • Individual components can be easily replaced • Off-the-shelf parts, HW and SW • Can constantly and cheaply build a faster parallel computer - Using Off-The-Shelf Parts • Lag time between latest advances and availability outside the research lab • Using parts that are not designed for parallel systems Currently 7 of the world’s fastest 10 computers are clusters
System-level Support for Clusters • Implement view of a single large parallel machine on top of separate machines Single, big, shared memory on top of n, small, separate ones Single, big, shared disk on top of n, small, separate ones Network
Nswap: Network Swapping • Implements a view of a single, large, shared memory on top of cluster nodes’ individual RAM (physical memory) • When one cluster node needs more memory space than it has, Nswap enables it use idle remote RAM of another cluster node(s) to increase its “memory” space
files Traditional Memory Management processor OS moves parts (pages) of running programs in/out of RAM RAM Disk Program1pages swap Program2pages RAM: limited size, expensive, fast, storage Disk: larger, inexpensive, slow (1,000,000 x slower), storage Swap: virtual memory that is really on disk expand memory using disk
Network Swapping in a Cluster Node 1 Node 2 processor processor RAM RAM Swap pages to remote idle memory in the cluster files Node 3 Disk processor RAM network Network Swapping: expand memory using RAM of other cluster nodes
Nswap Goals: • Transparency • Processes don’t need to do anything special to use Nswap • Efficiency and Scalability • Point-to-Point model (rather then central server) • Don’t require complete state info to make swapping decisions • Adaptability • Adjusts to local processing needs on each node • Grow/Shrink portion of node’s RAM used for remote swapping as its memory use changes
Nswap Architecture Divided into two parts that run on each node 1) Nswap client device driver for network swap “device” • OS makes swap-in & swap-out requests to it 2) Nswap server manages part of RAM for caching remotely swapped pages (Nswap Cache) User space Node A Node B OS space swap out page Nswap server Nswap Cache Nswap client Nswap server Nswap client Nswap Communication Layer Nswap Communication Layer Network
Client A Server B Server C How Pages Move Around Cluster Node A (client) Node B (server) • Swap Out: • Swap In: • Migrate from server to server: Client A Server B When Server B is full, it migrates A’s page to server C
Complications • Simultaneous Conflicting Operations • Ex. Migration and Swap-in for same page • Garbage Pages in the System • When program terminates, need to remove its remotely swapped pages from servers • Node failure • Can lose remotely swapped page data
Currently, our project… • Implemented on Linux cluster of 8 nodes connected with a switched 100 Mb/sec Ethernet network • All nodes have faster disk than network • Disk is up to 500 Mb/sec • Network up to 100 Mb/sec -> We expect to be slower than swapping to disk
Experiments • Workload 1: sequential R & W to large chunk of memory • Best case for swapping to disk • Workload 2: random R & W to mem • Disk arm seeks w/in swap partition • Workload 3: Workload 1 + file I/O • Disk arm seeks between swap and file partitions • Workload 4: Workload 2 + file I/O
Workload Execution Times • Nswap faster than swapping to much faster disk for workloads 2, 3 and 4
Nswap on Faster Networks Measured on Disk, 10 Mb/s and 100 Mb/s Calculated speed-up values for 1,000 & 10,000 Mb/s
Conclusions • Nswap: Scalable, Adaptable, Transparent Network Swapping for Linux clusters • Results show Nswap is • comparable to swapping to disk on slow network • much faster than disk on faster networks • Based on network vs. disk speed trends, Nswap will be even better in the future
Acknowledgements Students : Sean Finney ’03 Matti Klock ’03 Kuzman Ganchev ’03 Gabe Rosenkoetter ’02 Michael Spiegel ’03 Rafael Hinojosa ’01 Michener Fellowship for Second Semester Leave Support More information, results, details: EuroPar’03 paper, CCSCNE’03 poster http://www.cs.swarthmore.edu/~newhall/











![Prof. Chris Carothers Computer Science Department Lally 306 [Office Hrs: Wed, 11a.m – 1p.m]](https://cdn2.slideserve.com/4071720/slide1-dt.jpg)








